
通义千问主力模型降价97%,1块钱能买200万tokens
5月21日,阿里云在武汉AI智领者峰会上官宣,通义千问GPT-4级主力模型Qwen-Long,API输入价格从0.02元/千tokens降至0.0005元/千tokens,直降97%。
这意味着,1块钱可以买200万tokens,相当于5本《新华字典》的文字量。
这款模型最高支持1千万tokens长文本输入,降价后约为GPT-4价格的1/400,直接击穿了全球底价。

Qwen-Long是通义千问的长文本增强版模型,性能对标GPT-4,上下文长度最高可达1千万。除了输入价格降至0.0005元/千tokens,Qwen-Long输出价格也直降90%至0.002元/千tokens。
相比之下,国内外厂商GPT-4、Gemini1.5 Pro、Claude 3 Sonnet及Ernie-4.0每千tokens输入价格分别为0.22元、0.025元、0.022元及0.12元,均远高于Qwen-long。
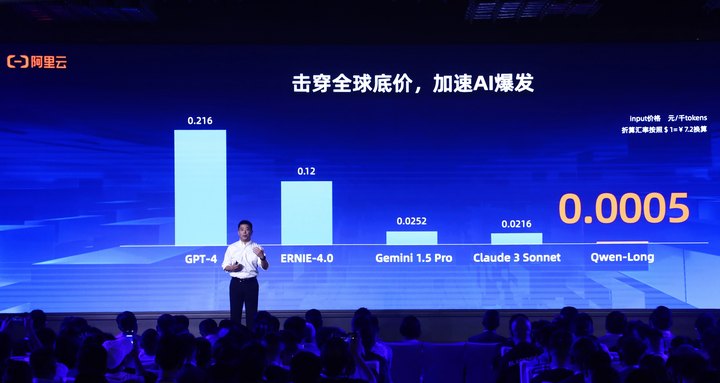
通义千问本次降价共覆盖9款商业化及开源系列模型。不久前发布的通义千问旗舰款大模型Qwen-Max,API输入价格降至0.04元/千tokens,降幅达67%。Qwen-Max是目前业界表现最好的中文大模型,在权威基准OpenCompass上性能追平GPT-4-Turbo,并在大模型竞技场Chatbot Arena中跻身全球前15。

不久前,OpenAI的Sam Altman转发了Chatbot Arena榜单来印证GPT-4o的能力,其中全球排名前20的模型中,仅有的三款中国模型都是通义千问出品。
业界普遍认为,随着大模型性能逐渐提升,AI应用创新正进入密集探索期,但推理成本过高依然是制约大模型规模化应用的关键因素。
在武汉AI智领者峰会现场,阿里云智能集团资深副总裁、公共云事业部总裁刘伟光表示:“作为中国第一大云计算公司,阿里云这次大幅降低大模型推理价格,就是希望加速AI应用的爆发。我们预计未来大模型API的调用量会有成千上万倍的增长。”
刘伟光认为,不管是开源模型还是商业化模型,公共云+API将成为企业使用大模型的主流方式,主要有三点原因:
一是公共云的技术红利和规模效应,带来巨大的成本和性能优势。阿里云可以从模型自身和AI基础设施两个层面不断优化,追求极致的推理成本和性能。阿里云基于自研的异构芯片互联、高性能网络HPN7.0、高性能存储CPFS、人工智能平台PAI等核心技术和产品,构建了极致弹性的AI算力调度系统,结合百炼分布式推理加速引擎,大幅压缩了模型推理成本,并加快模型推理速度。
即便是同样的开源模型,在公共云上的调用价格也远远低于私有化部署。以使用Qwen-72B开源模型、每月1亿tokens用量为例,在阿里云百炼上直接调用API每月仅需600元,私有化部署的成本平均每月超1万元。
二是云上更方便进行多模型调用,并提供企业级的数据安全保障。阿里云可以为每个企业提供专属VPC环境,做到计算隔离、存储隔离、网络隔离、数据加密,充分保障数据安全。目前,阿里云已主导或深度参与10多项大模型安全相关国际国内技术标准的制定。
三是云厂商天然的开放性,能为开发者提供最丰富的模型和工具链。阿里云百炼平台上汇聚通义、百川、ChatGLM、Llama系列等上百款国内外优质模型,内置大模型定制与应用开发工具链,开发者可以便捷地测试比较不同模型,开发专属大模型,并轻松搭建RAG等应用。从选模型、调模型、搭应用到对外服务,一站式搞定。
好文章,需要你的鼓励


Siri AI、ChatGPT、Claude真实横评,谁才是最强AI助手?
海外博主做了一次 Siri AI、ChatGPT、Claude 横评。看完之后我最大的感受是,AI 助手的竞争已经不只是模型能力,而是谁离用户更近。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。
2024
05/21
11:41
分享
点赞

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
