
微软发布Copilot+ PC:集成GPT-4o,史上最强、最快Windows!
5月21日凌晨,微软发布了Copilot+ PC,这是全球首个专为AI设计的Windows PC,也是Windows史上最强版本。
据悉,Copilot+ PC内置了OpenAI的GPT-4o模型并搭载了超强芯片,每秒能执行40多万亿次操作。可提供实时的语音、语言翻译,实时绘画、文本、图片生成等一系列超强创新功能。
Recall是该产品的一大特色功能,可以帮助用户搜索、查看过去做过的任何事情,例如,用户在PC上打开了哪些应用,使用了哪些文档等。
可以像人的大脑一样记住所有见过、碰过的东西。为了安全性,用户可以手动删除这些操作镜像。
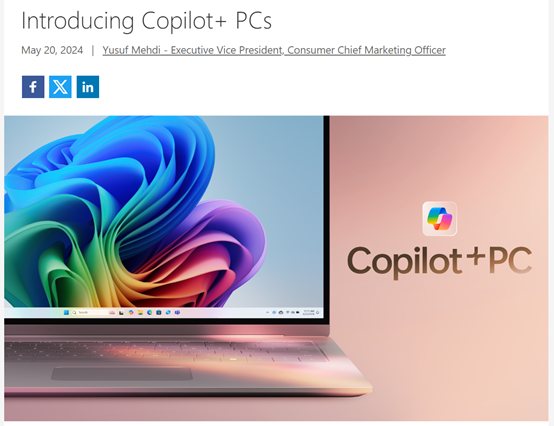
超强的Recall回忆功能
数据爆炸时代,我们每天在电脑上做的事情实在太多,浏览了无数的网页,存储海量的文件夹,从数千封邮件中找出自己最想要的那一个,这些琐碎的小事相当费时间。
现在,通过Recall功能可以将自己过去的所有操作,例如,浏览网站、打开应用、查看的邮件、打开的Office等,皆支持实现可视化搜索。
用户可以通过自然文本来搜索这些记录,就像电脑里的那个文件搜索框一样,Recall便会把你所有的操作罗列出来。
为了安全性和数据隐私,用户可以暂停Recall功能,同时所有镜像操作都存储在本地,随时可以手动删除不会上传到云端。
内置文生图功能
自微软发布文生图产品Image Creator以来,全球用户已经生成了超过100亿张图片。但在网页端使用,会出现延迟长、数据隐私泄露等问题。
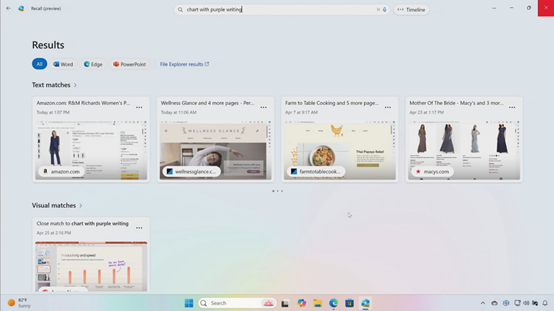
现在,Copilot+ PC内置了功能强消耗低的大模型,帮助用户可以在本地PC直接使用文生图模型,同时重塑了内置的画图工具。
用户可以无限量地重新设计图片,例如,上传一张泰迪狗的照片,用文本提示让大模型帮你重新设计。
也可以在画图工具中实时将线条变成图片,这对于设计人员以及绘画爱好者来说帮助是巨大的。
值得一提的是,所有图片生成、设计都是无限量的,再也不用怕额度不够了。
实时字幕、语音翻译
我们在实时观看不同国家球赛、演出以及和跨国客户交流时,翻译是必不可少的工具。但传统的翻译工具只支持主流语言,对于那些极少语音支持较差,同时也无法做到实时翻译。
现在,Copilot+ PC提供的实时翻译功能,可将电脑的任何音频翻译为英语字幕,并在所有应用程序的屏幕上持续实时显示。
用户也可以将任何应用程序实时视频语音或预先录制的音频,从40多种语言即时、自动地翻译成英文字幕,即便不联网离线状态也能完成。
该功能对于跨国商务、学术交流等有着巨大帮助,帮助人们消除语言障碍更好地进行实时聊天。
增强Adobe全家桶
微软与Adobe达成了技术合作,其旗舰应用Photoshop、Lightroom、Illustrator、Premiere Pro等都将可以在Copilot+ PC使用。
微软也会针对Adobe新推出的生成式AI功能,例如,使用 DaVinci Resolve Studio中的NPU加速的Magic Mask,轻松地将视觉效果应用于物体和人物,在芯片、硬件层面进行大幅度优化增强其性能和响应效率。
使用CapCut 中NPU上运行的自动剪切功能,快速删除任何视频剪辑中的背景。
更快、更好的Copilot
随着ChatGPT的功能不断完善,已经成为我们日常办公、学习不可缺少的工具。为了进一步提升文本生成和响应效率,Copilot+ PC内置了OpenAI最新发布的大模型GPT-4o。
与网页端相比,本地的Copilot响应效率更高,用户可以向其询问任何内容,例如,安排旅行计划、电影推荐、文案扩写、文本翻译等。
此外,对PDF、PPT、Word等文档的总结能力也更加便捷,可以随时为用户解读冗长、繁琐的内容。
目前,联想、宏碁、华硕、戴尔、惠普和三星著名PC厂商已经与微软签订了合作协议,6月18日将正式发布不同型号的Copilot+ PC。
微软表示,Copilot+ PC只是刚开始,他们会通过生成式AI重塑整个PC生态,从底层硬件、芯片再到开发、软件应用层等,这将是Windows平台诞生至今几十年最重要的技术变革。
来源:AIGC开放社区
好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。
2024
05/21
19:04
分享
点赞

