
OpenAI发布CriticGPT模型,帮助人类找出ChatGPT错误
6月28日凌晨,OpenAI在官网发布了,基于GPT-4的最新模型CriticGPT。
与以往模型不同的是,CriticGPT是一款面向开发人员的产品,可以增强RLHF(人类反馈强化学习)的效率培育出质量更好的训练数据。
所以,CriticGPT也被OpenAI称为“评论GPT”,主要用来审核ChatGPT输出的代码等内容,并解释内容到底错在哪里。例如,让ChatGPT用Python写一个函数,表示文件路径的字符串路径作为输入,并在“path”处返回文件的file对象。
ChatGPT很快就能给出完整代码,但是这段代码是有很大的安全漏洞,例如,使用“Startswitch()”检查文件的绝对路径是否在目录中非常不安全。
因为,用户可以通过符号链接或类似地命名目录来利用此漏洞。而CriticGPT就是专门用来查找这种错误。
论文地址:https://cdn.openai.com/llm-critics-help-catch-llm-bugs-paper.pdf
CriticGPT能增强RLHF
OpenAI表示,RLHF是优化GPT-4等模型的关键技术。RLHF是一种将人类反馈融入到强化学习过程中的技术。主要用于训练智能体,使其在复杂和难以明确建模的环境中表现出更高的性能。

在传统的强化学习框架中,智能体通过与环境的交互来学习,以最大化累积奖励。但这种方法有时会面临奖励设计困难和学习效率低下的问题。
为了解决这些难题,RLHF 引入人类作为奖励信号的来源。人类反馈可以采取多种形式,包括直接的奖励信号、排名反馈、偏好比较等。

所以,RLHF的核心之一就是收集人类对不同 ChatGPT 输出的比较评分。随着大模型的不断迭代,ChatGPT 输出的内容越来越准确,错误也变得更加隐蔽,就算是专业的AI训练师也很难察觉那些错误所在。
而ChatGPT在CriticGPT的帮助下,其输出准确能力可以提升60%左右,并且可以找出很多人类无法发现的问题,这对于增强RLHF非常有帮助。
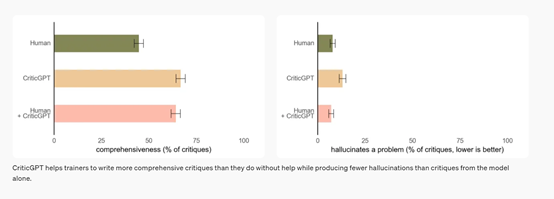
因此,OpenAI会将CriticGPT融合到现在以及未来产品研发中,提升模型输出的准确性和安全性。
训练评论模型
根据OpenAI展示的论文显示,训练CriticGPT模型的第一步是通过篡改的方式开发一套动态数据生成机制,在数据集中故意地在模型生成的答案中插入错误内容。
这不仅是简单地添加错误,而是要求篡改记录下他们插入的每个错误的详细描述,就像在代码审查中发现了这些错误一样,为训练数据提供了丰富的错误示例。
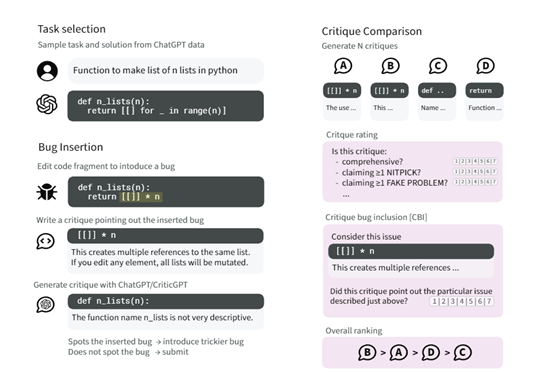
然后,再训练一个奖励模型来预测人类对评论质量的排名。这个奖励模型的目的是评估评论模型生成的评论是否全面、是否包含了特定的错误,以及是否避免了无关紧要的问题或虚假错误。
通过这种方式,可确保评论模型在生成评论时能够平衡准确性和全面性。

在策略优化阶段,使用了近端策略优化(PPO)算法来优化评论模型的行为策略,允许模型在保持策略更新幅度较小的同时,有效地学习如何改进其输出。
同时引入了一种FSBS的推理采样策略,通过在生成评论时强制模型产生特定的高亮部分,然后根据奖励模型的评分选择最佳评论。这种方法允许模型在生成更长、更全面的评论时,减少虚假问题的产生。
根据实验数据显示,评论模型在检测代码错误的表现非常出色,相比人类高出60%,比很多专业的外包更能发现大模型输出的问题所在。
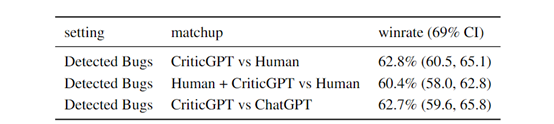
但OpenAI表示,CriticGPT并非总是正确的,有时候也可能输出不正确的内容来误导人类。所以,在使用时需要搭配使用。
好文章,需要你的鼓励


开创电气越南基地形成80万台手持式电动工具年产能力
今天讲的出海案例是开创电气,一家金华手持式电动工具制造商,在越南基地完成首款产品验收并形成80万台年产能力。

当AI学徒“失控发疯“:中国科学院自动化研究所揭示强化学习崩溃真相,并找到了解决之道
本文介绍了中国科学院自动化所的研究,揭示了大型语言模型在多轮工具调用强化学习中崩溃的根本原因,并系统评估了五种监督信号对训练稳定性和泛化能力的影响。

一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津、MIT等顶尖机构联手揭露:当前最强AI智能体,在这些任务上表现堪比新手
牛津、MIT等机构联合发布GauntletBench,测试显示最强AI智能体完成率仅19%,而普通人类完成率超80%,揭示AI在时间感知、图形理解和三维推理上的真实短板。
2024
06/28
19:04
分享
点赞

