
阿里Qwen-2成全球开源大模型排行榜第一,中国处于领导地位。
6月27日凌晨,全球著名开源平台huggingface(笑脸)的联合创始人兼首席执行官Clem在社交平台宣布,阿里最新开源的Qwen2-72B指令微调版本,成为开源模型排行榜第一名。
他表示,为了提供全新的开源大模型排行榜,使用了300块H100对目前全球100多个主流开源大模型,例如,Qwen2、Llama-3、mixtral、Phi-3等,在BBH、MUSR、MMLU-PRO、GPQA等基准测试集上进行了全新评估。
重新评估的原因是,目前开发者太注重排行榜的名次,在训练过程中使用了很多评估集的数据,并且之前的评估流程对于那些模型来说太简单了,所以,本次给这些模型加大了难度,想看看它们的真正实力。
结果显示,阿里开源的Qwen-2 72B力压科技、社交巨头Meta的Llama-3、法国著名大模型平台Mistralai的Mixtral成为新的王者,中国在全球开源大模型领域处于领导地位。
Qwen-2开源地址:https://huggingface.co/Qwen/Qwen2-72B-Instruct
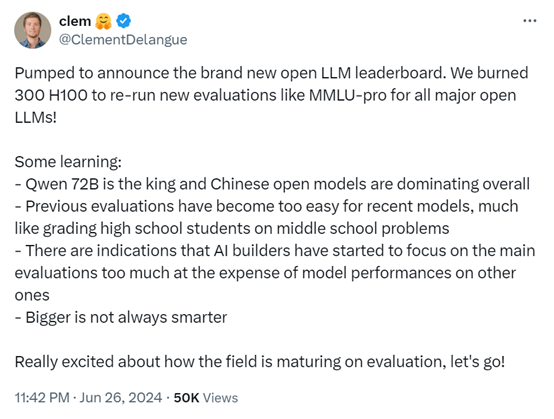
根据排行榜的数据显示,Meta开源的Llama-3-70B指令微调版本位列第2;阿里的Qwen2-72B基础版本排名第3;Mistralai的Mixtral-8x22B指令微调版本排名第4;
微软最新开源的小参数模型Phi-3-Medium-4K 14B排名第五,这说明小参数模型经过高质量数据集的预训练,同样能实现媲美大参数模型的能力。
中国零一万物最新开源的Yi-1.5-34B-Chat版本排在了第六名;知名大模型平台Cohere开源带RAG功能的Command R+ 104B排名第7;
英伟达开源的Smaug-72B-v0.1曾经排名第一,但在新的排行榜只有第8名;第9和第10名,全部都是阿里之前开源的Qwen1.5基础和Chat版本。
所以,全新排行榜的前10名竞争非常激烈,很多都是当过之前排行榜第一名的高手,相当于大模型界的“华山论剑”。
阿里开源的4款大模型傲视群雄,无愧于“中神通”的名号,这也充分说明中国对全球开源大模型的重要贡献以及领导地位。
对于这个排名结果,StabilityAI的研究总监,19岁便获得博士学位的Tanishq表示,他很早就说过中国在开源大模型领域非常有竞争力,除了Qwen2,还有零一万物、InternLM、Deepsseek等很多知名的开源模型。
关于中国在开源大模型领域处于落后状态简直可笑,相反,他们却处于领导者地位。
对于阿里Qwen-2取得如此高的成绩,确实让很多人感到惊讶,但事实结果就是这样。
他们也把希望寄托在Meta身上了,赶紧发布点新模型和Qwen-2再来一次大PK。

其实,不只是huggingface,曾经就有人发布过ElyzaTasks100性能评测,Qwen2-72B的指令微调版本也是性能最高的开源大模型,仅次于OpenAI的GPT-4o,高于谷歌的Gemini1.5Pro。
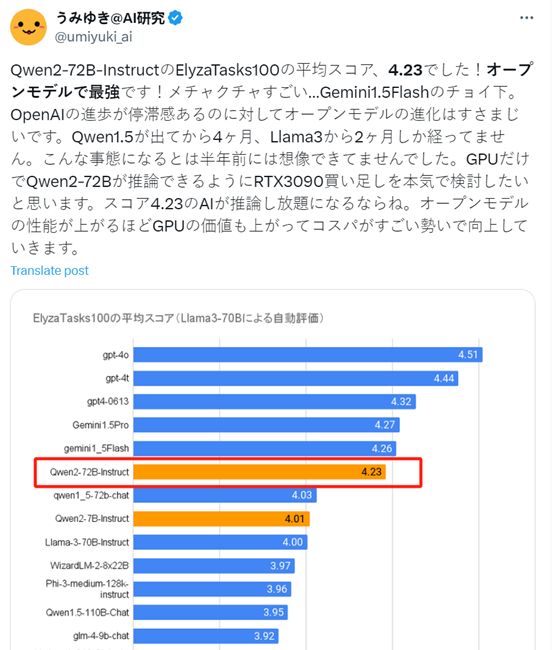
其实在与OpenAI、Anthropic这两家著名闭源大模型平台进行PK时,Qwen2-72B指令微调版本也丝毫不落下风,也是中国唯一进入美国评估标准前10的国内公司。
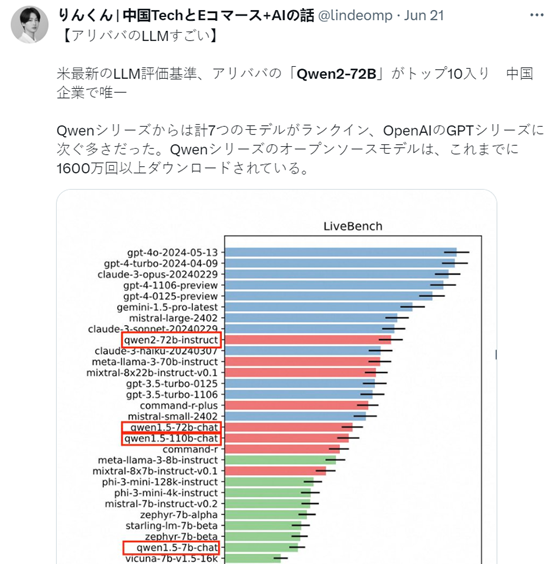
希望阿里砥砺前行,更上一层楼。期待未来发布更多高性能的开源大模型,造福全人类。
来源:AIGC开放社区
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2024
06/28
21:04
分享
点赞

