
比OpenAI的Whisper快50%,最新开源语音模型
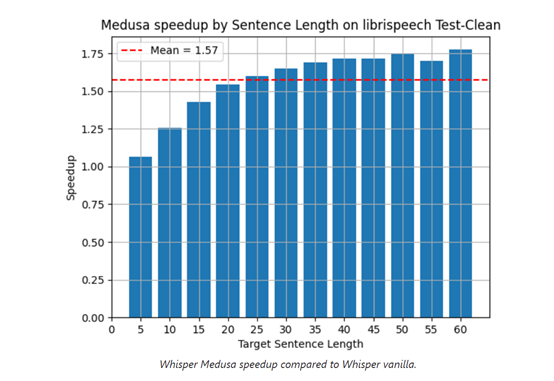
生成式AI初创公司aiOla在官网开源了最新语音模型Whisper-Medusa,推理效率比OpenAI开源的Whisper快50%。
aiOla在Whisper的架构之上进行了修改采用了“多头注意力”机制的并行计算方法,允许模型在每个推理步骤中预测多个token,同时不会损失性能和识别准确率。
开源地址:https://github.com/aiola-lab/whisper-medusa
huggingface:https://huggingface.co/aiola/whisper-medusa-v1
传统的Transformer架构在生成序列时,是遵循逐个token的顺序预测过程。这意味着在生成新序列时,模型每次只能预测下一个token,然后将这个预测的token加入到序列中,再基于更新后的序列预测下一个token。
这虽然能够确保生成序列的连贯性和上下文相关性,但也有一个非常明显的缺陷——极大限制了模型的推理效率。
此外,由于每次只能处理一个 token ,模型难以捕捉到数据中的长程依赖关系,可能会忽略一些重要的全局信息,从而影响模型的整体性能和准确性。
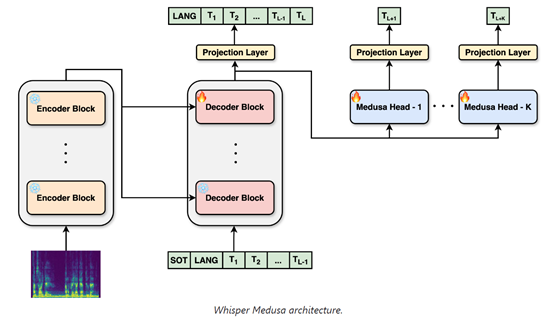
而Whisper-Medusa使用了10头的多注意力机制, 能各自独立地计算注意力分布并行地处理输入,然后将各自的输出通过拼接的方式组合起来,形成一个多维度的向量。
随后向量被送入全连接层进行进一步的处理,以生成最终的token预测。这种并行的数据处理方式不仅加快了模型的推理效率,还增加了模型的表达能力,因为每个注意力头都可以专注于序列的不同子集,捕捉到更丰富的上下文信息。
为了使多头注意力机制在Whisper-Medusa模型中更高效地运行,aiOla采用了弱监督的方法,在训练过程中冻结了原Whisper模型的主要组件,使用该模型生成的音频转录作为伪标签来训练额外的token预测模块。
使得模型即便没有大量手动人工标注数据的情况下,依然能够学习到有效的语音识别模式。
此外在训练过程中,Whisper-Medusa的损失函数需要同时考虑预测的准确性和效率。一方面,模型需要确保预测的token序列与实际转录尽可能一致;
另一方面,通过多头注意力机制的并行预测,模型被鼓励在保证精度的前提下,尽可能地加快预测效率。
aiOla使用了学习率调度、梯度裁剪、正则化等多种方法,确保模型在训练过程中能够稳定收敛,同时避免过拟合性。
业务场景方面, Whisper-Medusa能理解100多种语言,用户可以开发音频转录、识别等多种应用,适用于翻译、金融、旅游、物流、仓储等行业。
aiOla表示,未来会将Whisper-Medusa的多注意力机制扩展至20个头,其推理效率将再次获得大幅度提升。

好文章,需要你的鼓励


开创电气越南基地形成80万台手持式电动工具年产能力
今天讲的出海案例是开创电气,一家金华手持式电动工具制造商,在越南基地完成首款产品验收并形成80万台年产能力。

当AI学徒“失控发疯“:中国科学院自动化研究所揭示强化学习崩溃真相,并找到了解决之道
本文介绍了中国科学院自动化所的研究,揭示了大型语言模型在多轮工具调用强化学习中崩溃的根本原因,并系统评估了五种监督信号对训练稳定性和泛化能力的影响。

一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津、MIT等顶尖机构联手揭露:当前最强AI智能体,在这些任务上表现堪比新手
牛津、MIT等机构联合发布GauntletBench,测试显示最强AI智能体完成率仅19%,而普通人类完成率超80%,揭示AI在时间感知、图形理解和三维推理上的真实短板。
2024
08/05
20:04
分享
点赞

