
揭秘:“BBAT”万卡AI集群网络架构
随着大模型从千亿参数的自然语言模型向万亿参数的多模态模型升级演进,超万卡集群亟需全面提升底层计算能力。
字节megascale集群网络
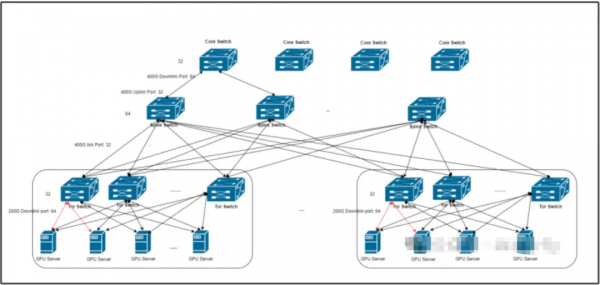
注:该拓扑图是字节上一代网络拓扑,新一代架构类似,交换机及接口速率翻倍提升
网络拓扑集群规模宏大,集成了超过10,000个GPU,依托一个精心设计的三层类CLOS网络架构实现高效互联。该网络的核心在于采用Broadcom Tomahawk 5芯片自研中心交换机,每颗芯片性能为51.2Tbps带宽,并集成64个800Gbps高速端口。网络架构中,每层交换机均维持1:1的收敛比,即32个端口专用于下行链路,另32个端口则负责上行链路,确保高带宽与低延迟并存。这一设计使得集群内任意节点均能在极少的网络跳数内实现无缝通信。
每台服务器配置了八个400Gbps网络接口卡,通过多轨方式连接至八个独立的ToR(Top of Rack)交换机,形成高效的ToR交换机群组。值得注意的是,ToR交换机利用先进的AOC(Active Optical Cable)技术,将单个800G下行端口灵活分割为两个400G端口,以优化资源利用。
在三层架构中,Spine交换机配置32个下行端口,专门服务于ToR交换机;而Core交换机则拥有64个下行端口,用于连接Spine交换机。具体而言,每个ToR-group(包含8个ToR交换机)能够支持接入64台服务器(即512张GPU)。进一步地,一个Spine-block由32个Spine交换机组成,每个Spine交换机全连接至所有ToR交换机,覆盖4个ToR-group,总计支持2048张GPU。最终,Core-pod通过Core交换机的64个端口连接两个Spine-block,实现高达4096张GPU的聚合能力。多个Core-pod通过Core交换机全互联,共同构建出超大规模的万卡级GPU集群。
为优化网络性能,实施了精细的路由设计与流量调度策略,有效减少ECMP(等价多路径)哈希冲突。得益于上行链路带宽是下行链路的两倍,交换机级别的设计进一步降低了冲突概率。同时,策略性地安排数据密集型训练任务在同一ToR交换机下运行,不仅大幅减少了通信跳数,还进一步降低了ECMP哈希冲突的风险。
在拥塞控制方面,我们创新性地融合了Swift与DCQCN算法的优势,开发出一种新型拥塞控制机制。该机制结合了往返时间(RTT)的精确测量与显式拥塞通知(ECN)的快速响应能力,既提升了网络吞吐量,又有效减轻了与PFC(优先级流控制)相关的拥塞问题,确保了网络的高效稳定运行。
百度HPN网络
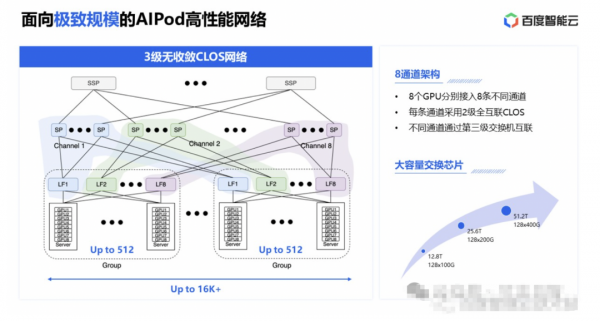
百度HPN网络采用了创新的HPN-AIPod架构,该架构基于8导轨设计,构建了一个3级无收敛(即收敛比为1:1)的CLOS网络拓扑。在这一架构中,每台服务器配置了8张高性能网卡,每张网卡均独立连接至一个TOR(Top of Rack)汇聚组的8个TOR交换机上,从而实现了高度灵活且高效的网络连接。这种设计使得每个TOR汇聚组能够支持的最大GPU数量达到512张(即888的配置)。
进一步地,8个Leaf交换机作为汇聚层的核心组件,通过8个独立的通道向上连接至不同的网络层级。在每个通道内部,Spine交换机与Leaf交换机之间实现了full mesh全互联,确保了通道内的高效数据流通。通过这种设计,整个集群的最大GPU支持能力可超过16,000张,极大地提升了网络规模和扩展性。
尽管主要的网络通信流量通常集中在同一通道内,但跨通道通信的需求仍然存在。为了解决这个问题,百度HPN网络引入了SuperSpine交换机,它将不同通道的Spine交换机连接起来,形成了一个跨越所有通道的互联网络。这一设计不仅打破了通道间的壁垒,还进一步增强了整个集群的通信能力和容量。
在路由选择方面,百度HPN网络采用了联合亲和性调度和DLB(动态负载均衡)技术,以有效解决交换机哈希冲突问题。通过智能的路由选择和负载均衡策略,网络能够确保数据包在网络中的高效传输,同时降低延迟和丢包率,为用户提供更加稳定、可靠的网络服务,针对数据包的乱序问题则是通过网卡的重排序能力来解决。
阿里HPN7网络
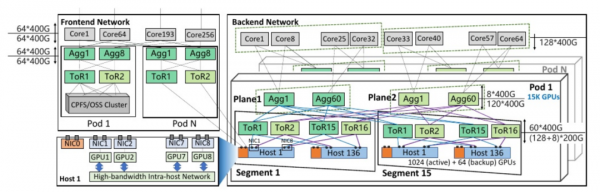
阿里HPN7网络采用了创新的两层双平面架构,摒弃了传统的三层CLOS架构,实现了单个Pod内对高达15,000个GPU(即万级GPU)的高效互联。该网络拓扑中,每个Pod精心划分为15个segment,每个segment集成了1024张主GPU与64张备用GPU,以确保高可用性和可扩展性。
每台服务器均配备了先进的9个NIC(1个前端网卡+8个后端网卡),其中每个NIC支持2×200Gbps的超高带宽。特别地,一个NIC(即NIC0)专用于前端网络连接,而其余八个NIC则全力支撑后端网络,确保LLM(大型语言模型)训练期间的数据洪流得以顺畅流通。这八个NIC通过2*8=16个端口与16个ToR(Top of Rack)交换机实现全连接,极大提升了数据交换的灵活性和效率。
HPN7网络使用阿里自研51.2Tbps以太网单芯片交换机,这些交换机在Tier1层级中配置了128个活动200Gbps下行端口与8个备份端口,以及60个上行400Gbps端口,实现了接近1:1的超额认购比(精确为1.067:1),有效保障了网络资源的充分利用与高效管理。
为了进一步提升整体集群容量,HPN7网络在Tier1之上增设了Core层(收敛比15:1),通过该层将多个Pod紧密连接,构建出强大的第三层网络架构。这一设计不仅增强了网络的可扩展性,还为实现更大规模的GPU集群提供了坚实的基础。
在路由选择方面,HPN7网络部署了先进的主机-交换机协作系统,该系统能够确保所有主机实时掌握最新的链路状态信息,并据此计算出正确的不相交路径,从而有效避免网络拥堵和哈希冲突。
此外,HPN7网络还实现了一套简单而高效的应用层负载均衡方案,以最大化RDMA连接的利用率。该方案通过为每个连接维护一个计数器来监控当前活动工作队列元素(WQEs)中的总字节数,从而精准评估连接的拥塞状态。一旦发现连接拥塞,系统将自动调整工作队列的消耗速度,以确保网络的平稳运行。
腾讯星脉2.0网络架构
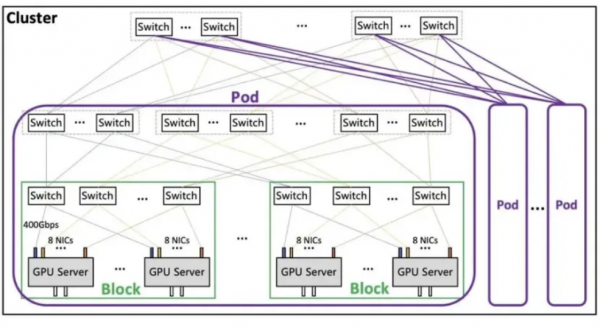
腾讯在RoCE技术基础上,全面升级并推出了星脉网络计算架构2.0版本。该架构集成了腾讯自主研发的网络设备与高性能AI算力网卡,同时引入了创新的TiTa和TCCL网络协议,专为超大规模(超过10万张GPU)的组网需求设计。相较于前代,星脉2.0的网络通信效率实现了60%的显著提升,直接推动大模型训练效率提升20%,展现了卓越的性能优势。
在网络拓扑层面,星脉2.0采用了高效的Fat-Tree架构,单个集群即可支持高达1.6万个计算节点(总计超过10万个GPU),充分满足大规模计算需求。每个计算节点由一台服务器构成,内置8个GPU及8张400Gbps高速网卡,提供总计3.2Tbps的通信带宽,确保数据传输的极致流畅。
整体架构精心划分为Block-Pod-Cluster三级结构,以实现灵活高效的资源管理。Block作为最小单元,包含256个GPU,为基础计算单元提供坚实支撑;Pod则代表典型的集群规模,由16至64个Block组成,灵活适应不同规模的计算需求;而Cluster作为最高层级,最大可支持16个Pod,即涵盖65,536至262,144个GPU,展现出强大的扩展能力和计算潜力。
在拥塞控制方面,星脉2.0搭载了腾讯自主研发的TiTa协议2.0版本,该协议实现了从交换机到端侧网卡的迁移,并引入了先进的主动拥塞控制算法。这一算法能够智能感知网络状态,主动调整数据包的发送速率,有效预防网络拥堵的发生。同时,通过拥堵智能调度机制,实现网络拥塞的快速自愈,确保网络环境的持续稳定与优化,为大规模计算任务提供可靠保障。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2024
09/09
17:04
分享
点赞

