
英伟达GPU:聚焦AI超大规模组网
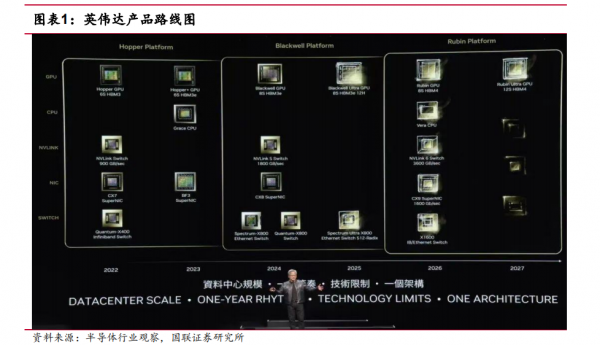
在 2024 年以前,英伟达平均 2 年推出新一代 GPU 架构,目前 Blackwell 芯片已经投产,并预计于 2025 年推出 Blackwell Ultra AI 芯片,2026 年推出下一代 AI 平台“Rubin”,2027 年推出 Rubin Ultra,更新节奏将变为“一年一次”。
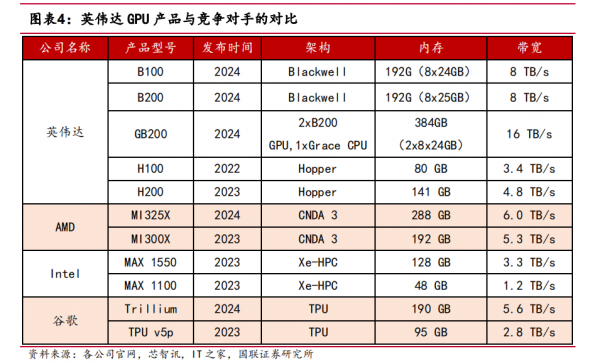
通过加快产品迭代,英伟达保持产品性能优势,且生成单个Token 功耗大幅降低。在各大 GPU 厂商新推出的产品中,英伟达 Blackwell在性能上高于 AMD 的 Instinct MI325X 和谷歌的 Trillium 芯片。
英伟达表达了发力 AI 以太网的决心,其全球首个专为 AI 设计的高性能以太网架构 Spectrum-X,目前正在为多家客户进行量产,公司预计 SpectrumX 将在一年内跃升至数十亿美元的产品线。英伟达推出了适用于以太网的Spectrum X800 交换机。此外,英伟达计划在 2025 年推出 Spectrum X800 Ultra,X800 将支持 10 万卡算力集群互联,而后续的 Spectrum X1600 将支持百万卡算力集群互联。
1 英伟达持续保持 GPU 领先优势
GPU 性能持续提升,生成单个 Token 功耗大幅降低。从“Pascal”P100 GPU 一代到“Blackwell”B100 GPU 一代,8 年间 GPU 的性能提升了 1053 倍,从 19 TFLOPS提升到 20000 TFLOPS。功耗方面,Blackwell 在 Token 生成能耗上大幅降低。在 Pascal时代,每个 Token 消耗的能量高达 1.7 万焦耳,Blackwell 使得生成每个 Token 只需消耗 0.4 焦耳的能量。
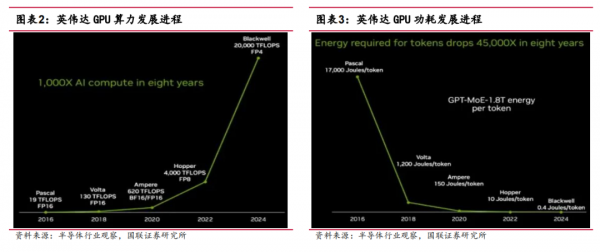
通过加快产品迭代,英伟达得以保持明显的产品性能优势。在各大 GPU 厂商 2024年新推出的产品中,英伟达Blackwell系列GPU在性能上高于AMD的Instinct MI325X和谷歌的 Trillium 芯片,叠加 Blackwell 芯片已经量产,英伟达依然维持较大优势。
2 英伟达发力AI以太网,超大规模组网趋势明确
英伟达在财报会上表达了发力 AI 以太网的决心。英伟达推出了适用于以太网的 Spectrum X800 交换机,拥有每秒 51.2 TB 的速度和 256 路径(radix)的支持能力。此外,英伟达计划在 2025 年推出 Spectrum X800Ultra,X800 将支持 10 万卡算力集群互联,而后续的 Spectrum X1600 将支持百万卡算力集群互联,以太网在 AI 集群组网上的应用或将持续增长。

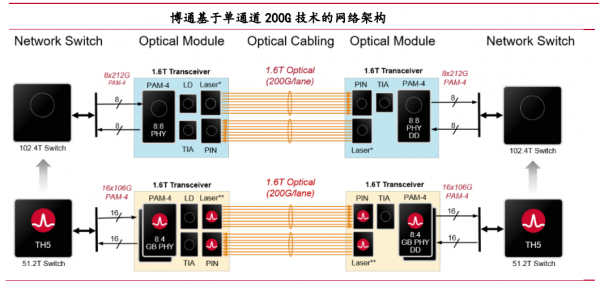
展望 2024 年 H2,英伟达 GPU 芯片的快速迭代,NVLink、InfiniBand、以太网连接方案同步演进。NVIDIA Quantum-X800 是英伟达第一款使用 200Gb/s-per-laneSerDes 方案的交换机设备,通过 72 个 OSPF 1.6T 光模块提供 144 个 800G 端口,明确了 1.6T 光模块需求。
产业链方面,博通在官网给出了基于单通道 200G 光通信技术的网络架构图。根据博通的方案,单通道 200G 光通信技术可以适配 51.2T/102.4T 两个代际的交换机芯片。单通道 200G 光网络包括了 EML、VCSEL、CW 光源、基于单通道 200G 方案的 1.6T光模块、线缆等。
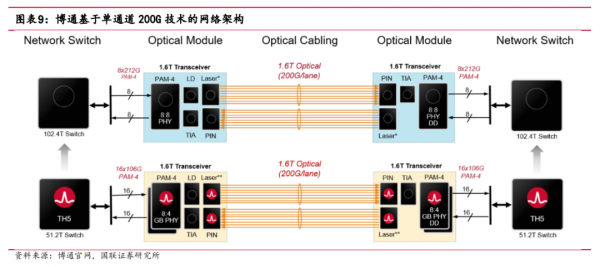
展望 2024H2 至 2025,我们认为 1.6T 光模块的研发和交付能力依然会主导光模块厂商的竞争格局,有利于头部企业强化竞争优势。同时低时延、低成本、低功耗的CPO、LPO、硅光、薄膜铌酸锂方案有望给新的企业带来破局机会。
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2024
09/09
19:04
分享
点赞

