
大模型变革:从云到端融合
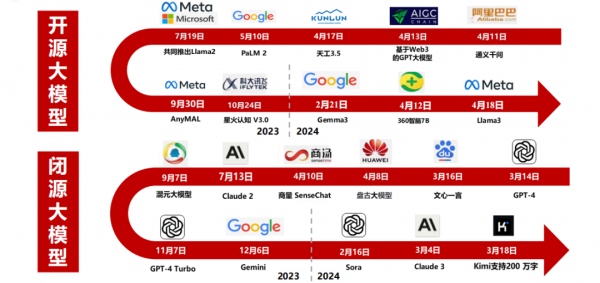
从GPT-1到GPT-5,GPT模型的智能化程度不断提升。ChatGPT在拥有3000亿单词的语料基础上预训练出拥有1750亿个参数的模型(GPT-2仅有15亿参数),预训练数据量从5GB增加到45TB。
AI对云厂商资本开支需求的拉动始于2023年四季度,据一季度各大云厂商的资本开支及指引,预计2024年北美云商资本开支有望重回高速增长态势。
Transformer算力需求在2年内增长750倍,平均每年以接近10倍的速度增长;英伟达平均每2年左右推出一代加速卡,从A系列到B系列的升级节奏来看,每一代产品算力提升幅度在3倍左右,价格提升幅度比算力提升幅度略低。综合大模型的参数增长和算力的单位价格来看,过去5年大模型训练对资本开支的需求持续快速提升,未来大模型参数的持续提升仍将带动算力需求激增。
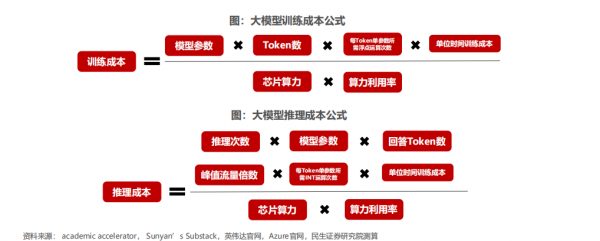
在生成式AI场景下,模型训练和推理所需的算力与参数大小成正相关。
1)训练所需的算力和模型参数以及训练集大小(Token)数量成正比;
2)推理所需的算力和模型参数,回答大小,以及访问量成正比关系。
当前大模型参数仍以较快速度增长,后续将推出的GPT-5模型,参数有望达到十万亿量级,有望引起大模型以及云厂商在算力领域的新一轮竞赛,拉动下游算力需求。
AI大模型的算力需求在过去几年呈现快速增长的态势,Transformer算力需求在2年内增长750倍,平均每年以接近10倍的速度增长。以OpenAI的GPT为例,GPT 1在2018年推出,参数量级为1亿个,Open AI下一代推出的GPT 5参数量级预计达到10万亿。
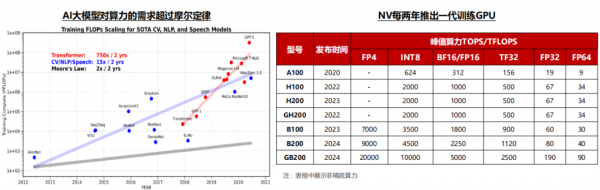
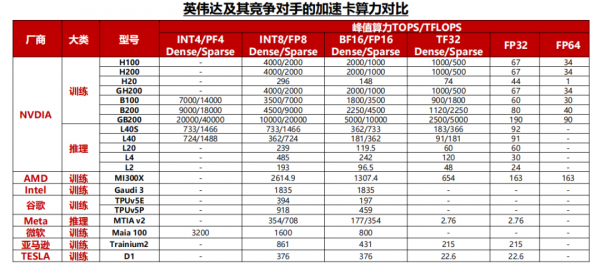
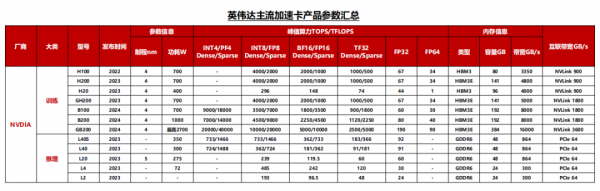
算力是加速卡的核心性能指标。AI芯片算力根据精度有所差异,一般神经网络的标准训练精度是32位浮点数,但有时为了节省时间和资源,也可以使用16位浮点数进行训练,推理时对算力精度的要求相对较低,而对功耗、推理成本、响应速度等要求较高,通常采用INT8算力。
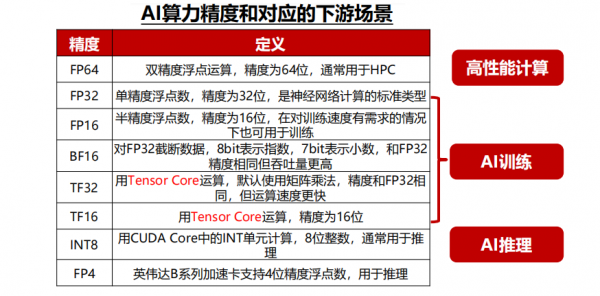
英伟达的加速卡在算力方面仍处于行业领先地位,最新一代Blackwell平台加速卡不仅在8~32位推理算力中显著超过竞争对手,还额外提供了FP4算力用于低精度的推理场景。
其他厂商来看,AMD在算力方面与英伟达最为接近,并且在FP64算力上超越英伟达最新一代的产品,更适合用于科学计算的场景。而目前其他的互联网公司自研加速卡与英伟达仍有较大差距。
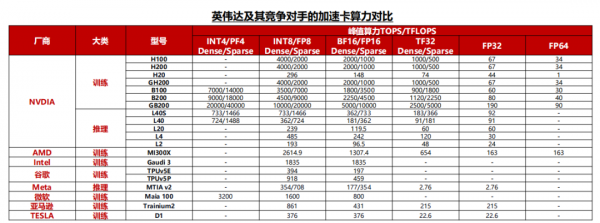
英伟达的NV Link和NV Switch保持着2年一代的升级节奏,目前NV Link带宽已达到1.8TB/s的双向互联,在市面上处于领先地位。
竞争对手的情况来看,AMD和谷歌的片间互联带宽分别达到了896GB/s和600GB/s,与英伟达的上一代H系列产品较为接近,而其他云厂商自研加速卡大多采用PCIe通信协议,在片间互联能力方面与英伟达仍有较大的差距。
据TechInsights,2023年英伟达占全球数据中心GPU出货量份额的98%,处于垄断地位。
同时,AMD、谷歌、特斯拉等厂商相继推出MI300系列、TPU V5以及Dojo D1等产品,挑战英伟达的垄断地位,尽管2024年4月英伟达推出的B系列加速卡再一次在算力方面与竞争对手甩开差距,但当前全球加速卡市场竞争者不断增加已成定局。
国内市场方面,伴随美国禁令趋严,2023年10月17日美国商务部公布算力芯片出口管制新规,A100、H100、A800、H800、L40、L40S等芯片进入管制名单,同时国内昇腾、寒武纪等龙头厂商产品能力不断追赶海外龙头,AI芯片国产化成为大趋势。

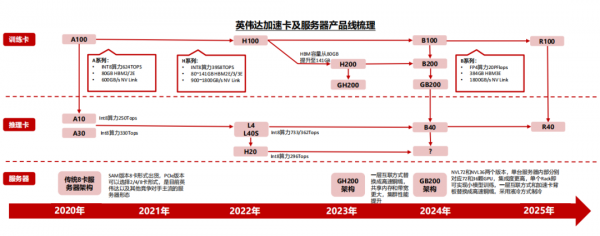
英伟达自2020年以来,平均每2年推出一代产品,每一代产品在算力、互联带宽等指标方面的提升幅度均在一倍左右。
训练卡方面,除了英伟达常规的H100、B100等加速卡外,H系列以后,英伟达还增加了H200、B200等产品,从而给客户提供更多的产品选择和更好的性价比,例如H200加速卡在HBM容量方面相较于H100均有较大提升,但价格方面提升幅度相对较少。
推理卡方面,2024年英伟达的产品出货以L40和L40S为主,并且推出了L20,L2,L4等产品供客户选择。
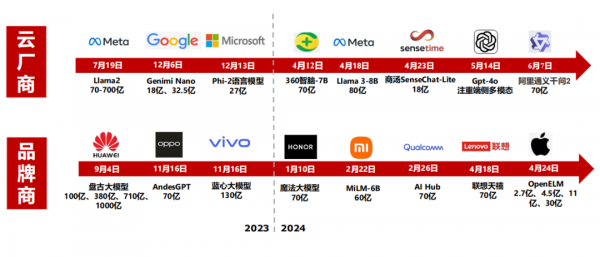
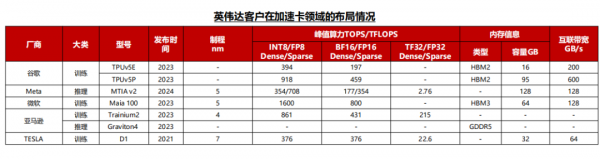
2023年12月,谷歌推出面向云端的AI加速卡TPU v5p,相较于TPU V4,TPU v5p提供了二倍的浮点运算能力和三倍内存带宽提升,芯片间的互联带宽最高可以达到600GB/s。其他云厂商也纷纷推出自研加速卡计划。
1)Meta:2023年,Meta宣布自研MTIA v1芯片,2024年4月,Meta发布最新版本MTIA v2加速卡;
2)微软:微软Azure的企业数量已经达到25万家,微软的Maia 100在2023年推出,专为Azure云服务设计;
3)亚马逊:2023年,亚马逊推出了用于训练的Trainium2加速卡,以及用于推理的Graviton4加速卡,目前亚马逊在训练和推理卡均有布局。
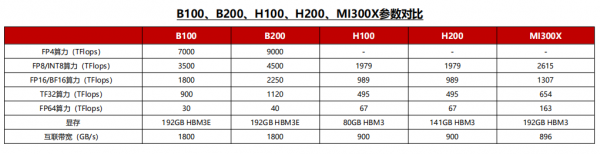
以AMD的MI300X为例,这颗加速卡在Int8、FP16、FP32算力方面均为H100的1.3倍,互联带宽方面达到了接近于NV Link4.0的896GB/s双向互联,FP64算力和HBM容量更是达到了H100的2倍以上,一系列的堆料和价格优势使得下游云厂商考虑转用一部分AMD的产品。
相较于H100,H200将此前的HBM3提升为HBM3E,同时将HBM容量从上一代的80GB提升至141GB。在价格方面,H200相较于上一代产品体现出极强的性价比,该款加速卡发售后预计将受到下游客户的欢迎。英伟达的下一代Blackwell GPU系列产品,在算力、内存和互联带宽的AI三要素领域与竞争对手的差距进一步拉开,巩固了英伟达的领先地位。
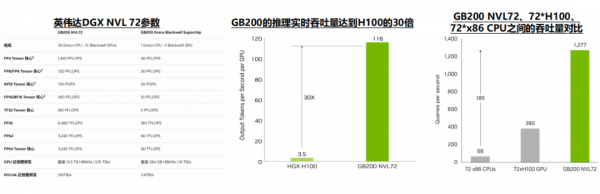
GB200 NVL72显著拉开了英伟达与其竞争对手的差距。英伟达通过架构的创新,解决了GPU之间互联带宽的问题,实现了最多576张卡1.8TB/s的双向互联带宽,显著领先其他竞争对手,使得GB200 NVL72的推理性能达到H100的30倍。
1)从性价比来看:NVL 72的集群规模增大,一方面节省了除算力芯片以外的系统成本,另一方通过提升产品性能,间接提升了下游客户购买的算力性价比。
2)从片间互联能力来看:市场上主流的AI服务器仍然是传统的8卡服务器架构,而伴随Blackwell平台推出的最多可以支持576卡互联,片间互联数量和带宽的提升极大改善了英伟达平台的推理和训练性能。
GB200 NVL72 Rack内部的GPU之间的互联,英伟达采用了高速铜缆的方案,优点包括:
1)成本低——相较于光模块,高速铜缆在相同成本的情况下可以提供更高的互联带宽,从而提升Rack的推理以及训练效率;
2)功耗低——采用铜互联方案可以节省光电转换产生的能量损耗,同时也降低了散热问题;
3)故障率低——光模块每年有2%-5%的损坏率,而铜连接更加稳定。

除了GPU之间,Compute Tray内部以及Rack之间也可以采用铜互连的方案。在英伟达的高速铜缆解决方案中,Compute Tray内部采用跳线对GPU、网卡等产品进行互联;同时多个Rack之间也可以采用铜缆的方案,GB200的Rack架构下,铜互连方案最多可以在8个Rack之间实现576卡的高速互联。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2024
09/21
00:04
分享
点赞

