
Meta开源首个量化模型Llama 3.2:减少40%内存,效率提升2倍以上
全球社交巨头Meta开源了首个轻量级量化版模型Llama 3.2,一共有10亿和30亿两种参数。
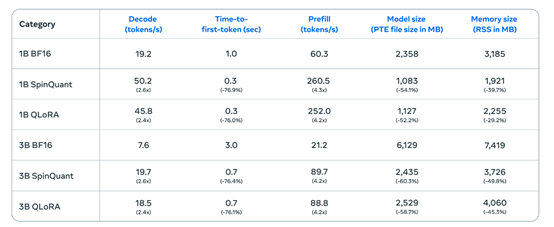
为了使该模型能在手机、平板、笔记本等移动设备上部署使用,Meta使用了带有LoRA适配器的量化感知训练和SpinQuant进行了大幅度性能优化,平均减少了41%的内存使用、减少56%的模型规模,但推理效率却提升了2—4倍。
例如,在一加12手机上,Llama 3.2的解码延迟平均提高了2.5倍,预填充延迟平均提高了4.2倍,而在三星的S24+、S22两款手机同样获得了类似的数据。
开源地址:https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf
在架构方面,Llama 3.2 1B和3B采用了标准的Transformer结构。但对所有变压器块中的线性层进行了特定的量化处理,采用4位组方式量化权重,并对激活进行8位每标记动态量化。
分类层则量化为8位每通道的权重和8位每标记的动态激活量化,同时使用了8位每通道量化用于嵌入。

模型优化方面,使用了LoRA适配器量化感知训练和SpinQuant两种重要技术。LoRA适配器量化在初始化 QAT 时,会使用经过有监督微调后获得的BF16 Llama 3.2模型检查点,进行额外一轮带有 QAT 的有监督微调训练。
然后冻结 QAT 模型的主干,再使用低秩自适应的 LoRA 适配器对变压器块内所有层进行另一轮有监督微调,并且LoRA 适配器的权重和激活保持在 BF16,最后通过直接偏好优化进行微调得到高能效模型。

而SpinQuant是目前最先进的后训练量化技术之一,通过使用WikiText数据集来学习旋转矩阵,这些矩阵有助于平滑数据中的异常值,促进更有效的量化。在确定了旋转矩阵之后,应用了包括范围设置和生成性后训练量化在内的最佳量化效果。
该方法虽不如 QAT + LoRA 准确,但具有很灵活的可移植性,且无需访问通常是私有的训练数据集。这对于数据可用性或计算资源有限的应用来说,是一个非常好的解决方法。
开发者还可以使用此方法对自己微调后的 Llama 模型进行量化,以适应不同的硬件目标和用例,其开源库与 ExecuTorch和 Llama Stack 完美兼容扩展性很强。
虽然Llama 3.2 1B和3B的参数很小,但都支持128k tokens 的上下文长度,这对于移动端来说非常重要,可轻松处理长文本的总结、复杂指令的理解等场,例如,在处理长篇小说的内容总结、学术论文的要点提取等任务时,可以更好地理解文本的整体逻辑和语义,从而提供更准确的结果。
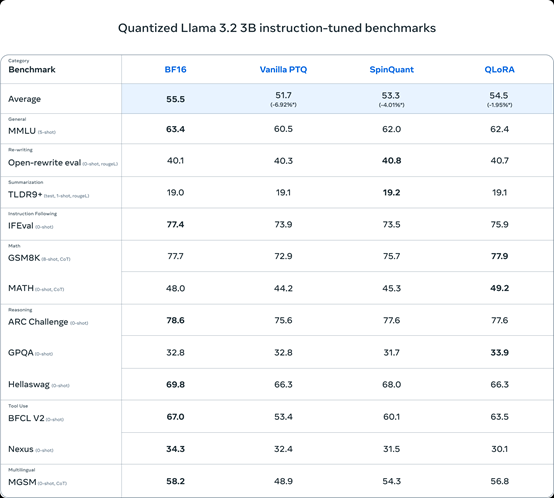
根据Meta公布的测试数据显示,在MMLU、GSM8K、MATH、MGSM等主流基准测试中,量化后的Llama 3.2不仅性能没有减少,还能与Llama 3 8B的性能媲美,充分证明了其高性能低消耗的特点。
好文章,需要你的鼓励

英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2024
10/28
11:04
分享
点赞

