
上海AI Lab提出TimeSuite:解锁MLLM长视频理解的潜力!

论文名:TIMESUITE: IMPROVING MLLMS FOR LONG VIDEOUNDERSTANDING VIA GROUNDED TUNING
论文链接:https://arxiv.org/pdf/2410.19702.pdf
引言
多模态大型语言模型(MLLMs)通过遵循一般的人类指令来解释视觉内容,已经展示了令人印象深刻的视频理解性能。然而,这些MLLMs在长视频理解方面仍然存在困难,因为长视频序列可能包含各种动态动作和复杂的时间关系,这使得MLLMs难以有效定位与问题相关的关键片段。当人类观看长视频时,他们的注意力会自觉地集中在几个秒内的突出部分。NExT-GQA也验证了时间定位对于准确回答视频问答任务的相关性。因此,一个自然的问题出现了:我们能否通过使用时间定位作为辅助任务来增强对长视频的理解?
简介
本文提出了TimeSuite,这是一系列新设计,用于适应现有的短视频MLLMs进行长视频理解,包括一个简单而高效的框架来处理长视频序列、一个高质量的视频数据集用于MLLMs的定位调整,以及一个精心设计的指令调谐任务,以明确地将定位监督纳入传统的QA格式。具体来说,基于VideoChat,我们提出了我们的长视频MLLM,命名为VideoChat-T,通过实施令牌洗牌来压缩长视频令牌,并引入时自适应位置编码(TAPE)来增强视觉表示的时间意识。
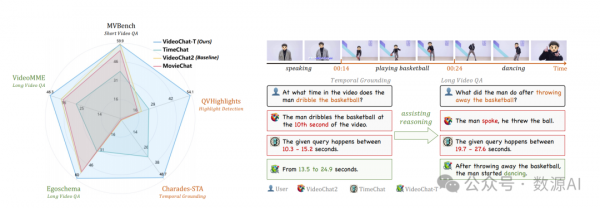
与此同时,我们介绍了TimePro,这是一个由9个任务和349k高质量接地注释组成的综合以时地为中心的指令调优数据集。值得注意的是,我们设计了一种新的指令调优任务类型,称为Temporal Grounded Caption,用于执行带有相应时间戳预测的详细视频描述。这种明确的时间位置预测将指导MLLM在生成描述时正确关注视觉内容,从而减少LLMs引起的幻觉风险。实验结果表明,我们的TimeSuite提供了一个成功的解决方案,用以增强短格式MLLM的长视频理解能力,在Egoschema和VideoMME基准测试上分别实现了5.6%和6.8%的提升。此外,VideoChat-T展示了强大的零样本时间接地能力,显著优于现有的最先进的MLLM。经过微调后,其表现与传统的监督专家模型相当。
方法与模型
TimeSuite,这是一个新的设计集合,用于改进短视频LLMs。具体来说,我们的TimeSuite包括一个长视频建模框架、一个高质量的视频数据集用于定位调整,以及一个精心设计的指令调优任务。通过这种新的TimeSuite设计,我们能够适应短视频MLLM,获得了在两种长视频理解任务上的显著性能提升:传统的长视频问答和时序视频定位。
1、VIDEOCHAT-T
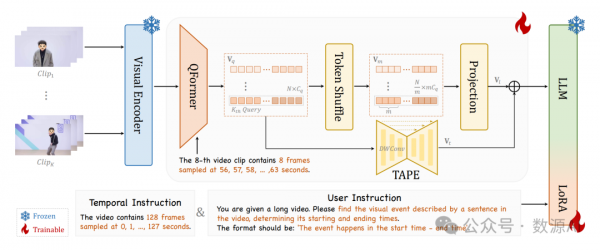
我们首先描述了我们提出的长视频建模框架的架构。具体来说,基于VideoChat2(Li等人,2024a),我们设计了VideoChat-T的长视频版本。我们的VideoChat-T由一个视频骨干组成,用于提取视觉表示,一个视觉-语言连接器用于压缩视觉标记并桥接视觉和语言模态,以及一个LLM来遵循人类指令解释视频内容。
VideoChat-T的架构如图2所示。其工作流程分为三个阶段。在第一阶段,长视频被均匀分割成片段,这些片段被Video Encoder和Q-Former(嵌入。然后,为了压缩视觉标记数量并突出关键部分,采用了标记洗牌来合并相邻的标记,并使用TAPE来添加时间自适应的位置编码。最后,压缩的视频标记序列被送入LLM以生成符合用户要求的准确响应。
(1)基础设计
视频片段编码。对于给定的长视频,我们执行均匀采样以获得KXT帧。我们将这些帧按时间顺序分成K个视频片段,并从每个片段中采样T帧。接下来,我们使用视频编码器及其视觉-语言连接器(此处为Q-Former)将每个片段编码成N个标记。在上述处理之后,整个视频被编码成一个序列的视觉标记。
大型语言模型。根据先前的研究,图像和视觉线索被投影到LLM相同的特征空间中。LLM作为MLLM中的交互界面,用于处理多模态输入、解析用户指令和生成适当的响应。为了处理长视频序列,我们需要在视觉编码器和LLM之间设计一个高效的压缩模块。
(2)VL-CONNECTOR:标记洗牌
我们提出了一种简单的标记洗牌压缩方案,该方案在避免过度性能损失的同时确保压缩前后视频标记的时间一致性。以往的方法通常使用投影仪来实现维度转换。然而,从低维到高维投影视觉编码向量并不会增加信息密度。因此,我们建议沿通道维度重新排列多个视觉标记。
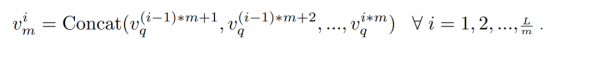
接下来,对合并的视觉特征VmVm应用线性投影层,生成视觉令牌序列Vl ∈ RLm×ClVl∈RmL×Cl作为输入到LLM中,其中ClCl代表LLM的令牌通道维度。这种方案有效地通过沿通道维度复制原始线性层参数m次来重用基础模型的投影器,实现了相当于平均池化的初始化,窗口长度为m。这种设计避免了引入可能扰乱原始模型的额外随机初始化参数,从而保留了其原始能力。此外,与直接使用池化相比,这种方法提供了更高的灵活性,用于微调以实现更好的结果
(3)时间自适应位置编码
为了将时间位置信息绑定到视觉令牌上,我们提出了一种称为时间自适应位置编码(TAPE)的适配器。受CPVT的启发,我们的TAPE在卷积的两端使用零填充作为锚点,并逐渐传输相对位置编码信息。TAPE无需添加任何特殊的时间令牌,就可以自动感知令牌序列的相对时间位置并生成时间嵌入。
具体来说,长视频令牌序列Vq首先通过线性层在通道维度上进行压缩,然后通过池化层进一步在序列长度上进行压缩。接下来,我们使用类似U-Net的结构,由一维深度可分离卷积组成,逐步下采样序列,获得三个不同分辨率的一维时间特征序列。随后,对最短的时间特征序列应用足够长的窗口卷积,并在两端使用零填充作为锚点来编码序列中每个标记的相对时间位置。然后,我们逐步上采样并恢复时间特征序列,从短到长,使用残差连接以保留不同尺度的时间特征。最后,将时间特征序列恢复到与Vl相同的长度,并通过线性层在通道维度上进行对齐,从而通过TAPE获得时间特征Vt输出。
2、TIMEPRO:时间分层的指令数据
传统的时间定位数据集只包含单调的真实值,即目标时期的开始和结束时间。这种数据格式在训练经典专家模型方面表现良好,但在释放大型语言模型(LLMs)的潜力方面却很困难。尽管已经发布了几个以时间定位为中心的数据集用于微调大型语言模型(MLLMs),但它们在数据量、数据质量和任务多样性方面仍有不足。因此,有必要构建一个更全面的时间定位数据集,专门用于调整大型语言模型。
根据多样性、长度和难度标准,我们收集并清理了几个现有的高质量时间定位中心数据集,并创建了两个新的数据集,形成了TimePro。与以往的时间定位中心数据集相比,TimePro提供了更大规模的数据、更广泛的分布和更高的任务多样性,这有助于学习更具泛化性的时间表示,以适应大型语言模型的需求。
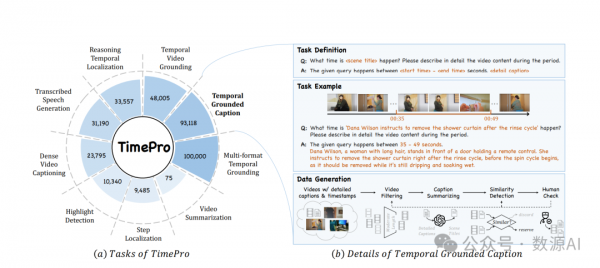
TimePro包含了来自15个与时间定位高度相关的数据集中的9种任务类型,包含大约349K的高质量时间定位注释。
实验与结果
实验细节
基于VideoChat2,我们分别使用UMT-L和Mistral-7B作为视频编码器和LLM。除了TAPE外,所有组件都从预训练的VideoChat2-Mistral模型中初始化。对于TAPE,我们使用随机初始化,将最终线性层的初始值设为零,并在训练的第一周期内冻结它。我们将每个剪辑的帧数T设置为8,因此长视频的剪辑数量K等于总帧数除以T。我们使用TimePro进行3个周期的模型微调,实例数为349K,以及一个包含82K实例的一般问答任务数据集。为了确保模型训练的稳定性,我们在第一周期使用192帧输入。在第二和第三周期,我们解冻TAPE并将模型输入调整为128帧。所有实验都在16台A100 GPU上进行。
定量对比结果
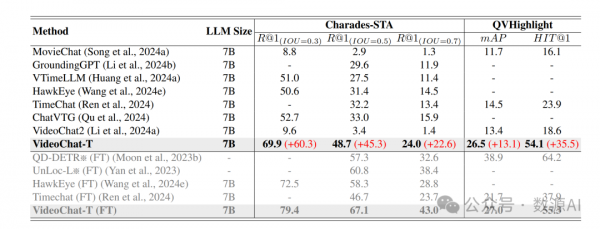
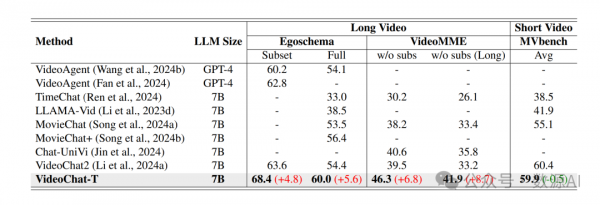
我们使用两个常用的时间定位任务来评估我们的方法,即时间定位和突出检测。VideoChat-T与其他模型的性能比较显示在表1中。我们的方法在零样本性能上超越了所有之前的基于大型语言模型(LLM)的方法,在微调之后,VideoChat-T甚至超过了某些经典专家模型在时间基定位任务上的表现。
定性对比结果
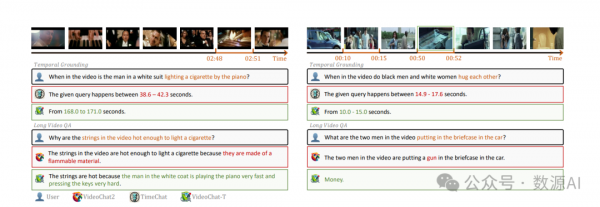
VideoChat-T能够回答更复杂的长视频推理问题。我们的模型准确地识别出“点一支烟”的事件时间位置,并根据视频内容确定正确的关键线索“穿白大褂的人”。这导致推断出“弹钢琴非常快且按键非常用力”是真正的原因。
好文章,需要你的鼓励


雷克萨斯LFA电动超跑2027年量产,将搭载固态电池
丰田旗下豪华品牌雷克萨斯正以纯电动版本复活经典跑车LFA。新车已在古德伍德速度节亮相,预计2027年量产,将采用丰田期待已久的固态电池技术。该技术承诺更高能量密度与更快充电速度,但丰田已多次推迟相关计划。新款LFA搭载电动动力系统,内饰配备Yoke方向盘与沉浸式数字座舱,车身尺寸与阿斯顿马丁DB12相近。面对比亚迪腾势Z等1500马力级竞品,雷克萨斯能否追上电动超跑赛道,值得关注。

慧眼难辨“何时何处“——慕课里AI通才的专业盲区,庆应义塾大学新出的这套考卷让15个顶级模型集体翻车
庆应义塾大学与英伟达推出AnyGroundBench,测试15个顶级视觉语言模型在手术、工业等五大专业领域的时空定位能力,揭示当前AI在专业场景下的系统性空间定位瓶颈。

科学家研究证明:我们并非生活在模拟现实中
加拿大不列颠哥伦比亚大学奥卡纳根分校的研究人员通过数学方法,对"模拟现实"理论给出了否定答案。研究人员米尔·法扎尔在《物理全息应用期刊》上指出,基于不完备性与不可判定性数学定理,现实无法仅通过计算来完整描述,它需要非算法性的理解,而这超出了算法计算的范畴,因此无法被模拟。尽管如此,"模拟宇宙"的观念短期内仍难以从公众讨论中消失。

清华大学与蚂蚁集团联合打造“数据科学AI考官“:AgenticDataBench如何给数据智能体打出一张精准成绩单?
清华大学与蚂蚁集团联合推出AgenticDataBench,含344道真实数据科学任务和433个精细技能标签,系统评测12种主流数据智能体配置的能力边界与短板。
2024
10/29
10:04
分享
点赞

