
阿里达摩院提出Animate3D: 4D内容生成的新框架!
数源AI论文推荐知识星球(每日最新论文及资料包,包含目标检测,图像分割,图像识别检索,视觉预训练,3D/点云/视频, 图像超分/去噪,GAN/Diffusion,LLM,ImageCaptioning,VQA,视觉语言预训练,MLLM,Text2Image,OpenVocabulary,语音技术,机器人技术,增量/连续学习,自动驾驶,遥感,医学,量化/剪枝/加速,机器翻译/强化学习,NRF,Visual Counting,时序建模等方向)
论文名:Animate3D: Animating Any 3D Model withMulti-view Video Diffusion
论文链接:https://arxiv.org/pdf/2407.11398.pdf
开源代码:https://animate3d.github.io/

引言
由于3D内容创作在AR/VR、游戏和电影行业中的广泛应用,它已经引起了显著的关注。随着扩散模型的发展和大规模3D对象数据集的建立,最近三代3D基础生成通过微调的文本到图像(T2I)扩散模型以及从头开始训练大型重建模型得到了广泛的探索,引领了3D资产创建进入新时代。尽管静态3D表示取得了显著进展,但这一势头在动态3D内容生成的领域——也称为4D生成——并未得到平行发展。
4D生成更具挑战性,因为同时保持视觉外观和动态运动的时空一致性是困难的。在本文中,我们主要关注两个挑战:1)没有统一的4D生成模型来统一空间和时间的一致性。2)未能通过多视图条件对现有3D资产进行动画化。
简介
在这项工作中,我们提出了Animate3D,这是一个新颖的框架,用于动画任何静态3D模型。核心思想是双重的:1)我们提出了一种新颖的多视图视频扩散模型(MV-VDM),该模型基于静态3D物体的多视图渲染进行条件化,并在我们的提出的大规模多视图视频数据集(MV-Video)上进行训练。2)基于MV-VDM,我们引入了一个结合重建和4D Score Distillation Sampling(4D-SDS)的框架,以利用多视图视频扩散先验来动画3D物体。具体来说,对于MV-VDM,我们设计了一个新的时空注意力模块,通过整合3D和视频扩散模型来增强空间和时间的一致性。此外,我们利用静态3D模型的多视图渲染作为条件来保持其身份。对于动画3D模型,我们提出了一个有效的两阶段流程:我们首先直接从生成的多视图视频中重建运动,然后引入4D-SDS来细化外观和运动。得益于精确的运动学习,我们能够实现直接的网格动画。定性和定量实验表明,Animate3D显著优于以往的方法。
方法与模型
给定一个静态的3D模型,我们的目标是使用文本提示对其进行动画化,并将其多视图渲染作为图像条件。这个4D生成任务特别具有挑战性,因为它需要确保外观和运动的空间和时间一致性、与提示的兼容性以及保持静态物体的身份。为了更根本地解决这些挑战,我们提出了一种新颖的框架Animate3D,用于对任何静态3D对象进行动画化。如图2所示,我们将任务分为两部分:学习多视图视频扩散模型(MV-VDM),以及使用MV-VDM学习3D物体动画。
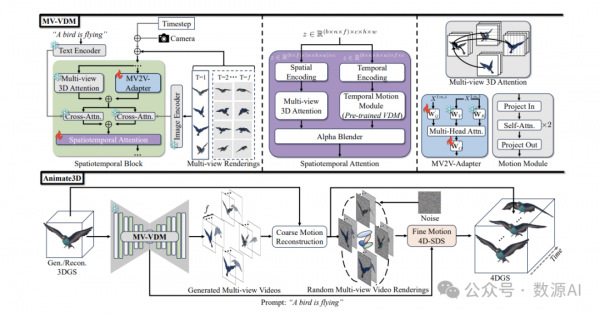
1、多视图视频扩散模型(MV-VDM)
我们提出了一个新颖的多视图图像条件多视图视频扩散模型,命名为MV-VDM。为了继承通过在大规模数据集上训练的空间一致性和时间一致的3D模型和视频模型所获得的先验知识,我们提倡一种基线架构,通过整合它们来利用它们的预训练权重。在这项工作中,我们分别采用MVDream和AnimateDiff作为3D和视频扩散模型。为了增强时空一致性并确保与提示和对象的多视图图像兼容,我们提出了一种高效的即插即用的时空注意力模块,结合了图像条件化方法。我们的MV-VDM是在我们提出的大规模多视图视频数据集MV-Video上训练的。
Spatiotemporal Attention Module
如图2所示,所提出的时空注意力模块包括两个并行分支:左分支用于空间注意力,右分支用于时间注意力。对于空间注意力,我们采用了与MVDream[44]中的多视图3D注意力相同的架构。具体来说,原始的2D自注意力层通过连接n个不同的视图转换为3D。此外,我们将2D空间编码,特别是正弦编码,纳入潜在特征以增强空间一致性。至于时间注意力,我们保持了来自视频扩散模型的所有时间运动模块的设计不变,以便重用它们的预训练权重。基于这两个分支的特征,我们采用了一个带有可学习权重的alpha混合器层来实现具有增强的时空一致性的特征。值得注意的是,由于渲染训练变得不可行的GPU内存要求,我们没有在所有视图中应用时空注意力。相反,我们的并行分支设计提供了一个高效且实用的替代方案。时空注意力可以表述为:
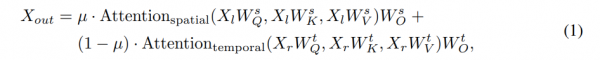
Multi-view Images Conditioning
受 I2V-Adapter 的启发,我们在提出的时空块内添加了一个新的注意力层,称为 MV2V-Adapter,与现有的冻结多视图三维自注意力层并行,如图 2 所示。具体来说,首先沿着空间维度连接噪声帧。然后使用这些帧查询来自多视图条件帧的丰富上下文信息,这些信息是使用冻结的三维扩散模型提取的。接下来,我们将 MV2V-Adapter 层的输出添加到原始多视图三维注意力的输出上。
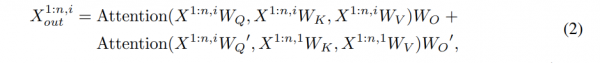
2、4DGS的重建与蒸馏
基于我们的4D生成基础模型MV-VDM,我们提出用任何现成的3D对象来动画。为了效率,我们采用3D高斯切片(3DGS)作为静态3D对象表示,并通过学习由六面体表示的运动场来对其进行动画化
4D Motion Fields
如同4D高斯切片(4DGS),我们用六面体来表示运动场。将静态3DGS表示为G,G=。运动模块 D 通过插值六面体R预测第i帧每个高斯点在位置、旋转和缩放上的变化。运动场计算可以表述为:
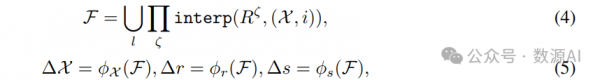
运动重建
基于由MV-VDM生成的空间时间一致的多视图视频,我们首先利用4DGS重建阶段直接重建粗略的运动。具体来说,我们使用一个简单但有效的图像和掩码的L2损失作为我们的Lrec,其计算公式如下:
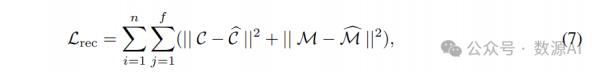
4D-SDS优化
为了更好地模拟细粒度运动,我们引入了一个4D-SDS优化阶段来提炼我们的多视图视频扩散模型的知识。4D-SDS损失 \mathcal_L4D–SDS 是 z_z0 -重建SDS损失的变体,可以表述为:
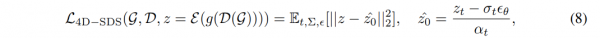
实验与结果
训练数据集
为了训练我们的MV-VDM,我们构建了一个大规模的多视图视频数据集,MV-Video。具体来说,我们从Sketchfab收集了53,340个动画3D模型的多视图视频。每个模型平均有2.2个动画,总共产生115,566个动画。每个动画持续2秒,帧率为24 fps。请注意,不允许用于生成AI程序的动画模型被过滤掉。我们的MV-Video数据集的统计信息在表1中报告。我们将发布此数据集,以进一步推进4D生成研究领域。

实验细节
我们均匀采样每个动画的16帧来训练我们的MV-VDM。我们使用Adamw优化器,学习率为2 e-42e–4,权重衰减为0.01,并以1024的批量大小训练模型20个周期。在推理时,我们将采样步长设置为25,并采用freeinit以获得稳定结果,用于动画3D对象。至于4D生成,Hex平面的分辨率和特征维度分别设置为[100,100,8][100,100,8]和16。我们对前750次迭代进行逐步运动重建,每次迭代有64个样本(4个视图,16帧),然后在另外250次迭代中添加4D-SDS优化。学习率对于Hex平面和偏移预测层分别为0.01和0.0001。我们在32个80G A800 GPU上训练MV-VDM需要10天,而4D生成的优化在单个A800 GPU上针对每个对象大约需要40分钟(运动重建20分钟,4D-SDS20分钟)。Mesh动画需要15分钟,比标准的3DGS动画快,因为它在3DGS中使用更少的点数,并且只需要运动重建阶段。
定量对比结果

我们的方法在I2V、动态度数(Dy. Deg.)和美学质量(Aest. Q.)方面显著优于4Dfy和DG4D。这表明我们的生成结果与给定的静态3D对象(I2V主体)、动态运动(Dynamic Degree)和卓越外观(Aesthetic Quality)高度一致。在运动平滑度方面,我们略逊于4Dfy,因为4Dfy总是生成几乎静态的结果,如表2a第一行的0.0动态度数所示。通常,我们的方法能够以几乎不牺牲它们高质量外观的情况下,为3D对象赋予平滑且动态的运动,从而便于定制和高质量的动态3D对象创建。
定性对比结果

很明显4Dfy的结果模糊且与给定的3D对象有很大偏差,这是由于使用文本条件化的扩散模型来优化运动和外观。此外,它生成的物体几乎是静态的。这是因为在训练过程的开始阶段,即输入到T2V模型的噪声渲染图像序列没有时间变化,这使得视频扩散模型生成几乎静态的监督。对于DG4D,其结果与前视图中的给定3D对象相对较好地对齐,即用于生成引导视频的视角。然而,它与新视角中的物体不对齐,如图3中蜘蛛侠和超人套装上缺失的模式以及模糊的后侧视图所示。这是因为它采用了Zero123来优化新颖视图。Zero123仅对前视图进行条件判断,导致NVS优化倾向于使用预训练的数据分布,这可能会导致潜在的外观退化。更重要的是,当引导视频中的物体被赋予朝向摄像机的运动时,DG4D会失败。例如,在引导视频中,狗正在向摄像机移动,但DG4D将其解释为物体的放大。这种误解通常会导致模糊效果和奇怪的外观。
好文章,需要你的鼓励


Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。

Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber周三发布了一款基于现代Ioniq 5改装的数据采集原型车,搭载14个摄像头、8个固态激光雷达和9个雷达,通过英伟达双驱Thor计算机处理数据。Uber计划今年在全球部署500辆此类车辆,每月可采集200万英里高保真驾驶数据,供Avride、Waymo、WeRide等30余家自动驾驶合作伙伴使用。这是Uber自2020年出售自动驾驶部门以来首次自主组装车辆,也是其AV Labs部门的重要进展。

LMMs-Lab与NTU MMLab联手微软:让AI智能体“一句话自我进化“的秘密
SkillOpt-Lite通过将智能体技能优化形式化为零阶优化问题,提出极简流水线:把执行轨迹存为文本文件,让AI直接用文件系统工具翻日志、找规律、改技能,配合独立验证门控,比复杂的多智能体优化框架跑得更快效果更好,并自然延伸至执行框架自动优化(HarnessOpt),使轻量模型能够超越大模型。
2024
10/29
11:04
分享
点赞

