
阿里提出LLaVA-MoD架构!利用MOE技术让小模型也能大显身手!
数源AI 最新论文解读系列

论文名:LLAVA-MOD: MAKING LLAVA TINY VIA MOEKNOWLEDGE DISTILLATION
论文链接:https://arxiv.org/pdf/2408.15881.pdf
开源代码:https://github.com/shufangxun/LLaVA-MoD
引言
多模态大型语言模型(MLLM)通过在大型语言模型(LLM)中集成视觉编码器,在多模态任务中取得了有希望的结果。然而,大型模型的大小和广泛的训练数据带来了显著的计算挑战。例如,LLaVA-NeXT的最大版本使用了Qwen-1.5-110B,并且使用128个H800 GPU训练了18小时。此外,大量的参数需要高级硬件,导致推理速度缓慢,这增加了现实世界的部署难度,特别是在移动设备上。因此,探索一种平衡性能和效率的小规模MLLM(s-MLLM)是一个关键话题。
简介
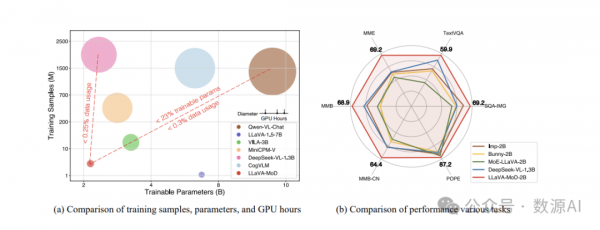
我们介绍LLAVA-MoD,这是一个新颖的框架,旨在实现小规模多模态语言模型(s-MLLM)从大规模多模态语言模型(l-MLLM)中提炼出知识的高效训练。我们的方法解决了LL-MM蒸馏的两个基本挑战。首先,我们通过将稀疏混合专家(MoE)架构集成到语言模型中,优化了s-MLLM的网络结构,在计算效率和模型表达性之间取得了平衡。其次,我们提出了一个渐进式知识转移策略,以实现全面的知识转移。这种策略始于模仿蒸馏,我们最小化输出分布之间的Kullback-Leibler(KL)散度,使s-MLLM能够模仿l-MLLM的理解。接下来,我们通过偏好优化(PO)引入偏好蒸馏,关键在于将l-MLLM视为参考模型。在此阶段,s-MLLM在区分优劣示例方面的能力显著增强,超越了l-MLLM,特别是在幻觉基准测试中。广泛的实验表明,LLaVA-MoD在保持最小激活参数和低计算成本的同时,超越了现有工作在各个基准测试上的表现。值得注意的是,LLaVA-MoD-2B在使用仅0.3%的训练数据和23%可训练参数的情况下,平均增益达到了8.8%,超过了Qwen-VL-Chat-7B。这些结果突显了LLaVA-MoD从其教师模型中有效提炼出丰富知识的能力,为开发高效的MLLM铺平了道路。
方法与模型
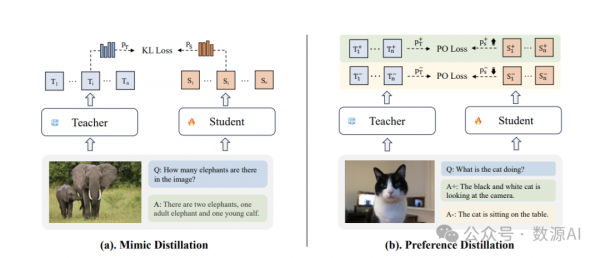
我们引入了LLaVA-MoD,这是一个用于构建高效s-MLLM的新框架,该框架结合了专家混合(MoE)和知识蒸馏。我们的框架由两个主要组成部分组成:(a)s-MLLM的架构设计:如图所示。3,我们设计了一个带有MoE的稀疏s-MLLM,增强了获取专业专家知识的能力,同时保持了训练和推理效率。(b)。蒸馏机制:我们设计了一个如图2所示的渐进式蒸馏机制,以从l-MLLM转移到稀疏s-MLLM。这个过程包括两个阶段:模仿蒸馏和偏好蒸馏。
1、稀疏s-MLLM的架构设计
s-MLLM的基本架构由三个主要组件组成:一个视觉编码器、一个大语言模型(LLM)和一个视觉-语言(VL)适配器。给定一个多模态指令对话(x, y)(x,y),我们定义我们的s-MLLM如下处理响应y:

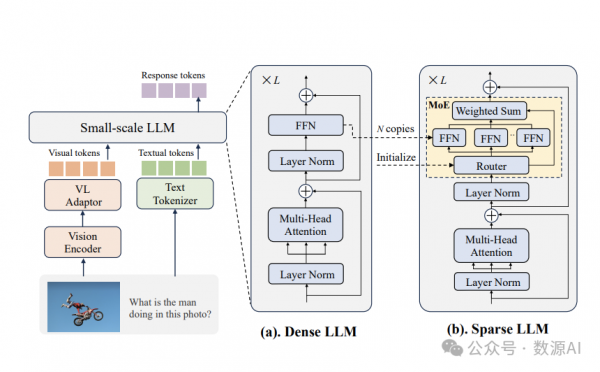
稀疏化s-MLLM。构建我们的s-MLLM的原则是在保持视觉编码器和视觉-语言适配器不变的同时缩小LLM。为了实现这一缩小目标,我们通过引入MoE架构来稀疏化密集的s-MLLM。具体来说,图3展示了这个过程,我们应用稀疏上采样技术(Komatsuzaki等人,2022)来复制N个前馈网络(FFNs)作为专家模块。此外,我们引入了一个线性层作为路由器,它通过预测专家对齐的概率动态激活适当的专家。给定序列中的每个令牌x,w我们首先计算N个专家的路由值:
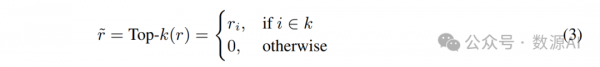
2、渐进式蒸馏
我们的渐进式蒸馏包括两个不同的阶段,即模仿蒸馏(图2(a))和偏好蒸馏(图2(b))。在模仿蒸馏阶段,s-MLLM πS 模仿来自l-MLLM πT 的通用和特定知识。在偏好蒸馏阶段,πS 获得 πT 的偏好知识以进一步细化其输出并减少幻觉。πS 和 πT 都来自同一LLM家族。这确保了一个一致的词汇空间,这对于准确的模仿至关重要。
(1)初始化
在蒸馏之前,我们首先通过一个可学习的适配器将视觉编码器与LLM对齐,旨在获得一个初始化良好的 πS 密集版本。LLMφ 和 ViTχ 保持冻结状态,因为它们的预训练参数已经捕获了丰富的视觉和语言知识。只有Projω 被优化来弥合视觉和语言领域之间的差距。对于初始化,我们利用广泛使用且经过精心策划的数据集中的常见图像-标题对,这些数据集涵盖了多样化的主题和视觉实体。训练目标是使生成的标记的交叉熵最小化。
(2)模仿蒸馏
我们将 πT 中的综合知识分解为一般和特定方面,以应对它们结构差异带来的挑战,这可能会使同时学习变得复杂。随后,我们进行从一般到特定的模仿蒸馏,包括两个步骤:密集到密集(D2D)和密集到稀疏(D2S)蒸馏,以将知识转移到 πS 中。这种两步方法通过逐步蒸馏平衡了一般和特定知识的转移,从而提高了整体性能。如图 3 所示,我们在 D2D 期间利用πS 的密集结构来获取一般知识,并在 D2S 期间将其转换为稀疏结构以获取复杂的特定知识。在整个过程中,πT 保持不变。
(3)偏好蒸馏
在这个阶段,我们的目标是从l-MLLM中蒸馏出偏好知识,以指导s-MLLM生成不仅准确而且合理的响应,这在减少幻觉方面至关重要。在训练过程中,我们有效地使用偏好数据,包括对相同提示x精心配对的正面响应y+和负面响应y–。我们的偏好蒸馏策略受到最近在偏好优化(PO)方面的进展的启发,它通过直接在离线偏好数据集上训练来绕过训练奖励模型的需求。我们的关键见解是将l-MLLM视为参考模型,以提供关于什么是“好”的和“坏”的洞察,从而为s-MLLM建立了一个基本参考。
实验与结果
实验细节
我们采用"ViT-MLP-LLM"架构来展示 LLaVA-MoD 的有效性。使用预训练的 CLIP-ViT-L/14 作为视觉编码器,以及一个两层 MLP 作为适配器。使用不同大小的 Qwen-1.5/2 作为 l-MLLM 和 s-MLLM 的 LLM。具体来说,l-MLLM 配置了 7B 参数,而 s-MLLM 配置了 1.8B 和 0.5B 参数。l-MLLM 在多模态基准测试上的性能在表 1 中展示。我们对蒸馏使用相同的 LLM 系列,即使用 Qwen-1.5 7B 来蒸馏 Qwen-1.5 1.8B 和 Qwen-1.5 0.5B。
定量对比结果
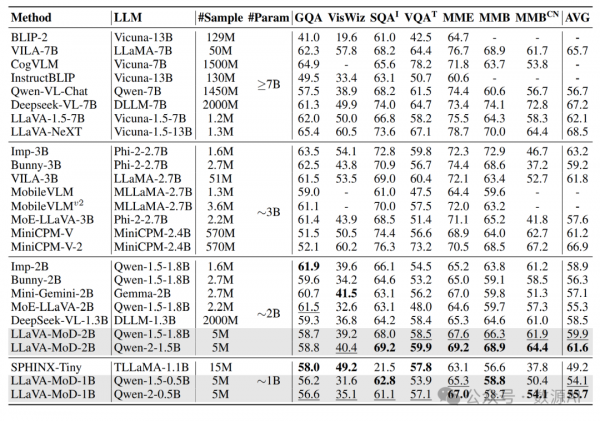
以理解为导向的基准测试。如表所示,LLaVA-MoD在1B和2B大小的模型中实现了理解为导向基准测试的平均最佳成绩。2B大小的LLaVA-MoD比Mini-Gemini-2B高出8.1%,同时使用了较低的图像分辨率(336对比768)。1B大小的LLaVA-MoD比SPHINX-Tiny高出13%。2%,使用的数据样本较少(500万对比1500万)。此外,LLaVA-MoD-2B匹配甚至超过了大规模MLLM的性能。2B大小的LLaVA-MoD比Qwen-VL-Chat-7B高出8.8%,并且与VILA-3B(林等人,2024b)和MiniCPM-V的性能相匹配。这些结果突显了我们的方法通过从大规模MLLM中蒸馏稀疏MoE架构,有效地训练小规模MLLM。
好文章,需要你的鼓励


Inbolt将在Automate展会发布视觉驱动机器人编程新功能
机器人智能公司Inbolt将于2026年6月在芝加哥Automate展会上发布两项新能力:Inbolt机器人编程功能和扩展版机器人控制模块。新功能可让工程师直接基于CAD模型构建程序,结合视觉模型实时定位实体零件并自动调整运动路径,彻底消除传统调试中耗时数周的手动示教环节。此次更新还将原生支持安川机器人,使平台覆盖品牌扩展至六个。

清华大学等团队如何让AI智能体拥有“记忆力“,从而真正学会自主探索未知世界?
清华大学等机构提出JAMEL框架,通过代码覆盖率信号联合训练AI智能体的潜在记忆模块与探索策略,以极低token消耗实现媲美大型闭源模型的自主探索能力。

笔记本电脑深度清洁指南:内外兼修焕然一新
本文提供了一套完整的笔记本电脑深度清洁方案。硬件方面,介绍了如何用温和洗涤剂清洁机身、用微纤维布擦拭屏幕、用压缩空气清理键盘及清洁充电线的正确方法。软件方面,建议及时更新操作系统与驱动程序,删除冗余文件与临时下载内容,并通过开启Windows Storage Sense功能实现自动清理,同时将剩余文件整理归类,保持系统整洁高效运行。

当AI“管家“学会分工协作:卡内基梅隆大学研究团队如何让电脑操作智能体突破单打独斗的瓶颈
卡内基梅隆大学提出MACU框架,让经理AI统筹多个员工AI并行完成复杂电脑操作任务,通过动态调整任务图,在四个基准上均超越单智能体。
2024
10/30
11:04
分享
点赞

