
刚刚,ChatGPT新增重磅功能!能打造自己的聊天数据库了
今天凌晨3点,OpenAI宣布ChatGPT新增重磅功能——聊天记录搜索。
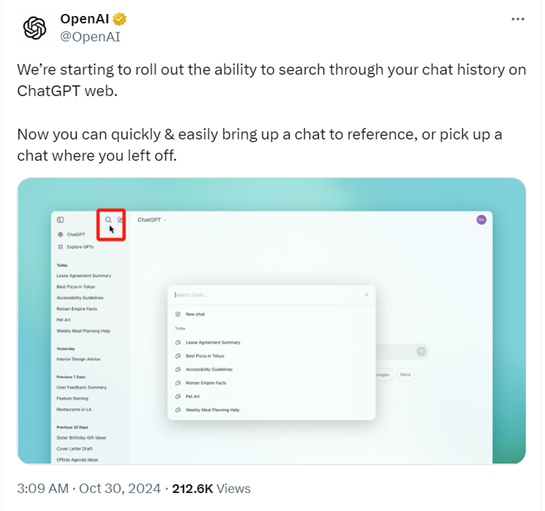
现在,用户可以快速一键搜索自己的聊天记录,或者从中断的地方继续聊天了。无论你开了多少个聊天页面、这个聊天有多难找,都能通过一键搜索轻松把它找出来。
也就是说,用户可以轻松打造独属自己的聊天数据库了。这对于写作、教育、金融、医疗等,对聊天交互频繁的行业来说帮助巨大。
值得一提的是,这个是用户期待已久的功能,向OpenAI反馈了很多次终于上线了,也是全球首个提供一键搜索的产品。
得知一键搜索功能上线后,网友表示,OpenAI是倾听用户声音的,这个功能太实用了。

我简直不敢相信过了这么多年才实现这个功能。之前在网页上找聊天记录真是太痛苦了。
这个功能能为我们节省大量时间,
如果你能在上线一个固定对话功能,我们会更高兴。

我们需要固定聊天功能。

这会为我们节省大量时间!这是基础功能吗?它能识别聊天中的关键词还是只能搜索标题?
很棒的功能!也可以考虑添加按主题或日期范围搜索的过滤器,以便更高效地搜索。

老铁们,只用了两年终于上线了!

期待已久的功能。

一直期待这个功能。虽然是个小功能,但能增加很多价值。如果不是这样的话,能进行 RAG 搜索而不仅仅是文本搜索就更好了。
目前,多数类ChatGPT聊天产品都需要一页一页查找聊天记录非常麻烦,尤其是处理那些有价值且时间较长的聊天记录更是头疼。下面使用ChatGPT聊天记录一键搜索的玩法展示。
打造专业知识数据库:如果你从事特定行业的工作,利用 ChatGPT 与它探讨行业内的专业知识、趋势、案例等,并将这些聊天记录存档。长期积累下来,就形成了一个属于自己的行业知识数据库。
例如,金融从业者可以把关于市场分析、投资策略、金融产品等方面的聊天记录保存起来,以便随时查阅和学习。
轻松管理项目资料:在进行项目工作时,将与项目相关的讨论、思路、解决方案等内容的聊天记录保存到聊天数据库中。
例如,营销人员在策划一场活动时,与 ChatGPT 讨论的活动主题、目标受众、宣传渠道等方面的内容都可以保存下来。后续在回顾项目或者开展类似项目时,可以快速检索并参考之前的讨论,避免重复思考,节省时间和精力。
创意数据库:当面临创意性工作,如广告文案撰写、设计方案构思时,与 ChatGPT 进行多轮对话,获取各种创意和思路。将这些聊天记录保存下来,后续如果灵感枯竭,可以重新查看,从中找到新的启发。
例如,设计师在设计一款产品的外观时,可以向 ChatGPT 描述产品的特点和目标用户群体,获取不同的设计风格和元素建议,并将这些建议记录在聊天数据库中。
写作辅助:对于需要大量文字创作的工作,例如,编辑、记者、文案策划等,ChatGPT 可以帮助生成文章框架、提供观点和论据等。将与 ChatGPT 的创作过程记录保存下来,方便后续对内容进行修改和完善,也可以作为素材库,为以后的创作提供参考。
从今天开始,Plus和Team 用户将在一天内获得聊天搜索功能。Enterprise 和Edu用户将在一周内获得。免费用户将从下个月开始获得访问权限。
好文章,需要你的鼓励


遭黑客入侵的Klue称犯罪分子正在删除窃取的客户数据,但新的黑客组织接连发出威胁
市场研究公司Klue本月初遭黑客入侵,大量客户数据被窃。Klue表示正与黑客组织Icarus沟通,并相信对方正在删除所盗数据。受影响客户包括Gong、LastPass、HackerOne等多家知名企业。然而事态趋于复杂——另一黑客团伙声称从Icarus处获取了Klue客户数据,并向客户发出勒索威胁。Klue提醒客户勿向第二方支付赎金,并建议索取数据样本以核实其真实性。

机械手臂终于学会“看深度“了——KAIST联合POSTECH研究团队让机器人规划与执行真正说同一种语言
KAIST等机构提出3D HAMSTER,通过为视觉语言模型加入深度编码器和几何重建损失,让机器人规划器直接输出三维轨迹,解决了分层机器人系统中规划与执行的维度不匹配问题,显著提升了操作鲁棒性。

苹果起诉OpenAI窃密:前员工利用零日漏洞下载机密文件
苹果公司对OpenAI提起诉讼,指控其窃取商业机密。据披露,前苹果系统电气工程师刘畅(Chang Liu)在离职加入OpenAI后,利用一个此前未知的身份验证零日漏洞,持续数周从苹果内部网络存储中下载大量机密文件,内容涵盖未发布产品信息、工程演示文稿及技术规格等。苹果已修复该漏洞并终止相关访问权限。此案已提交加州北区联邦法院,并要求陪审团审判。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。
2024
10/31
14:04
分享
点赞

