
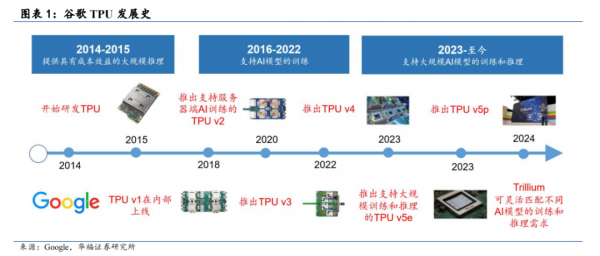
十年一剑,TPU引领AI芯片时代

1、TPU 如何发展而来?
简而言之,为更专用的 AI 计算而来。2013 年,Google AI 负责人发现,如果有1 亿安卓用户每天使用手机语音转文字服务 3 分钟,消耗的算力就已是谷歌所有数据中心总算力的两倍。而传统的通用CPU 以及专攻图形加速、视频渲染等复杂任务 GPU无法满足深度学习工作负载的巨大需求,同时存在效率较低、专用运算有限等问题。
于是,为探索出更具成本效益、节能的机器学习解决方案,谷歌毅然决定自行研发机器学习专用的处理器芯片,并于 2015 年宣布第一代 TPU 芯片(TPU v1)在内部上线,随后开启了长达 10 年的 TPU 更新迭代。
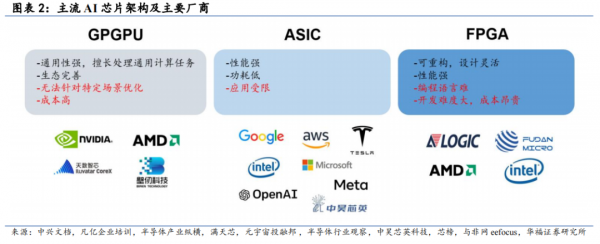
作为一种 AI 芯片,TPU 是专用集成电路(ASIC)的代表。主流 AI 芯片架构包括 GPGPU、ASIC 和 FPGA。GPGPU 通用性强,生态完善,GPGPU 的主要供应商英伟达是 AI 市场的绝对龙头,但 GPGPU 存在着成本高等问题;ASIC 虽然算力强大,功耗小,但相较于 GPGPU 在通用计算上稍有欠缺;FPGA 更具灵活性,也具有足够的算力,但相对开发周期长,复杂算法开发难度大,成本昂贵。
TPU 专为单一特定目的而设计:用以运行构建 AI 模型所需的独特矩阵和基于矢量的数学运算。其架构专为矩阵乘法而设计,这使它们能够处理大量数据以及复杂的神经网络。需要说明的是,我们也看到相关研究将 TPU 归类为 DSA(专用领域架构处理器),因为ASIC 是加速某一项功能,而 DSA 是加速某一类功能。但总体上 ASIC 和 DSA 的特征较为相仿,本文不作进一步区分。
2、TPU 优势何在?
2.1、芯片层面:能效王者,架构设计之美淋漓尽致
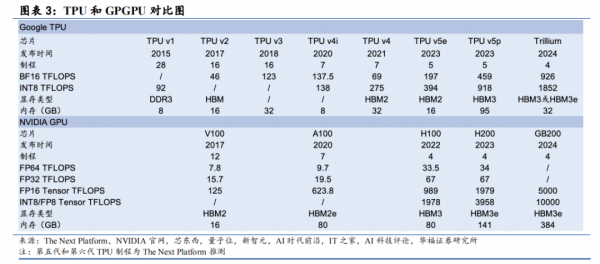
六代版本更新,与 GPGPU 平分秋色。我们将历代 TPU 以及同时代的 GPGPU进行梳理。首先,我们观察到同代 TPU 与 GPGPU 大多数处于同代或相近制程。第四代 TPU 已采用 7nm 制程,据 The Next Platform 推测第五代/第六代 TPU 分别采用5nm/4nm 制程,而英伟达 Ampere/Hopper/Blackwell 架构分别采用 7nm/4nm/4nm 制程。
在算力上,谷歌目前暂时落后一代。2024 年谷歌发布第六代 TPU Trillium,实现最大算力 926TFLOPS(BF16)/1852TFLOPS(INT8),相较于第五代 TPU v5e 和 v5p实现了飞跃式上升,比肩英伟达 2023 年发布的 H100,对应算力为 989TFLOPS(FP16)/1978TFLOPS(INT8 or FP8)。但在性能功耗比上,我们认为谷歌优势显著。谷歌并未披露最新产品的功耗指标,我们从前代产品可以窥见一二——2021 年发布的第四代 TPU v4 性能功耗比为 0.89-1.31TOPS/W,而英伟达同代产品 A100(2020 年发布)的性能功耗比为 1.56TOPS/W。
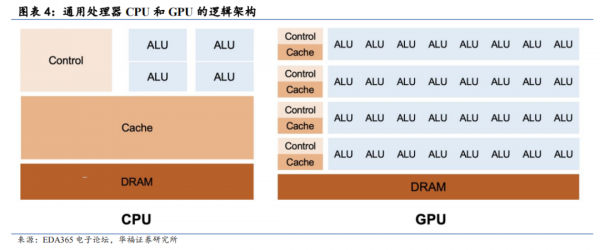
对此现象,我们可以从逻辑芯片架构的角度来进行解释——通用处理器 CPU 和GPGPU 因架构设计而在 AI 计算上存在低效问题。我们一般认为 GPGPU 为改善CPU 效率而生,而 TPU 可以进一步改善 GPGPU 未优化完全的部分,三者是从通用到专用不断演进的过程。
据新智元,CPU 使用了非常大量的片上存储来做缓存(Cache),将程序经常访问的数据放在片上,这样就不必访问内存了,从而实现“内存访问近乎零延迟”,相比之下负责运算的算术逻辑单(ALU)只占据了一小部分,这就是 CPU 进行大规模并行数据运算时效率低的原因之一。GPU 里面有数千个小核心,每个都可以看成是个小 CPU,它可同时运行最多数十万个小程序。虽然 GPU 单核的处理能力弱于 CPU,但是数量庞大,ALU 占比大,非常适合高强度并行计算。
但实际上大多数程序会因为等待访存而卡住,且管理和组织大量程序会付出巨大的硅片面积代价和内存带宽的代价,这个是 GPU 低效的根源。
TPU 优势#1 脉动阵列为基,张量计算横空出世——增大吞吐量,节省时间TPU 本义为张量处理器,这其中的“张量”是在数学和物理领域常见的概念。
从定义上讲,张量是一个多维数组,可以具有任意维度,张量的元素可以是标量、向量或更高维度的张量。一个数值可以看作一个标量(零维张量),一个一维数组可看作一个向量(一维张量),一个二维数组是一个矩阵(二维张量)。在深度学习和神经网络中,我们经常用高维的张量来表示图像、音频、文本等数据。通过在神经网络的各个层级之间进行张量的传递和计算,神经网络能学习和处理复杂的输入数据,执行特征提取、分类、回归等任务。
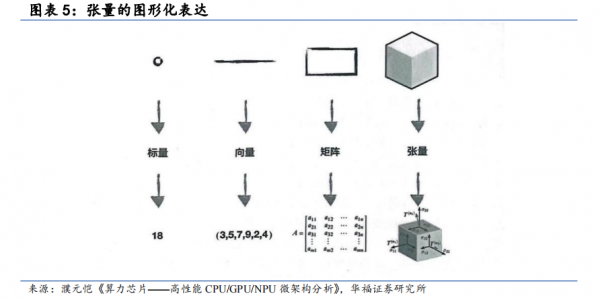
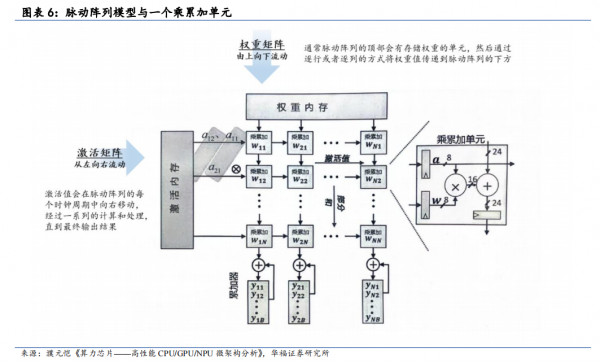
TPU 的核心是 MXU(矩阵乘法单元),MXU 以脉动阵列为架构,使 TPU 能够以很高的吞吐量执行矩阵乘法和累加。脉动阵列作为 TPU 的底层技术,是一种适用于进行大量的并行计算(尤其是矩阵乘法,也是深度学习中最常见的操作)的计算硬件结构。
脉动阵列的名字来源于它的工作方式,即数据在阵列中“脉动”式地流动,就像心脏在血管中泵血一样。通过这种方式,脉动阵列可以高效地执行矩阵计算操作,因为数据的流动方向符合计算规则和数据依赖关系。这种并行的数据流动方式可以充分利用硬件结构的并行性,加速矩阵计算过程。脉动阵列也必然存在局限性,比如它的计算模式相对固定,不适合执行有大量控制流的计算。不过,在深度学习中,大部分的计算都是数据流式的,且执行并行的矩阵计算,因此这个局限性的影响并不大。
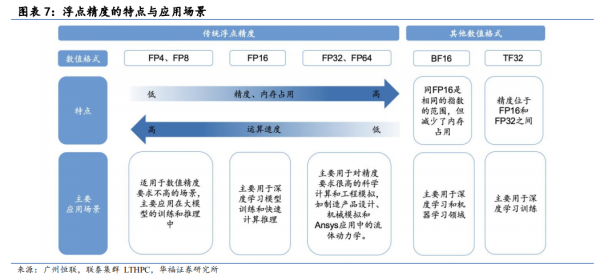
TPU 优势#2 直击 AI 应用,聚焦低精度计算——节省芯片面积
回看本文开篇对谷歌发展历程的复盘,大致可以将其划分为两个时代——以ChatGPT 为分水岭的 AI 初探索阶段和 AI 大爆发时代。TPU 自发明以来一直以低精度著称,从 AI 初探索阶段迈入 AI 大爆发时代,TPU 也经历了“拨云见日”的过程。
AI 初探索阶段:初代 TPU 入局 AI 推理,TPU v2 入局 AI 训练——低精度计算即可满足 AI 计算需求,特定方向优化出奇效。神经网络的两个主要阶段是训练(Training 或者学习 Learning)和推理(inference 或者预测 Prediction)。实际上,初代 TPU 推出的同一时期,训练几乎都是基于浮点运行,这也是 GPU 流行的原因之一。
事实上,推理过程使用 INT8 也基本够用。INT8 运算相较于浮点数而言,对整个芯片的能耗、面积都有较大程度上的节省,主要包括以下两方面:
(1)乘法运算:INT8乘法比 IEEE 754 标准下 FP16 乘法降低 6 倍的能耗,占用的硅片面积也少 6 倍;
(2)加法运算:整数加法的收益是 13 倍的能耗与 38 倍的面积。从这一角度出发,谷歌TPU 设计顺势采用低精度计算模式,TPU v1 仅支持 INT8 精度,而同时代英伟达的AI 推理芯片 K80(2014 年推出)最低需要支持 FP32 精度。
实际效果显示,与 GPU相比,TPU 的控制逻辑单元更小,更容易设计,面积只占整体芯片面积的 2%,给片上存储器和矩阵计算单元留下了更大的空间。后来从 TPU v2 开始,谷歌引入了自创的浮点精度 BF16,虽与 FP16 保持相同位数(在浮点精度的位数上与英伟达同时代产品 V100 保持了一致),但能够减少内存占用,也对 AI 硬件的发展产生深远影响。
在这一阶段,AI 应用的方向还不够清晰,AI 硬件的发展路径也并不明朗。TPU是谷歌基于自身业务以及对 AI 的理解而做出的选择。对于低精度的聚焦,既是在AI 计算上的优势,同样也是在其他计算领域的劣势。这也是 ASIC 本身的专用化特征所造就的。站在当下回望,我们发现,TPU 具备的优势其实最终都形成了 AI 芯片共同的趋势,在优化方向上大同小异,而谷歌的强大在于“前瞻”。
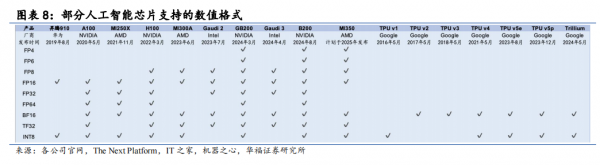
AI 大爆发时代:AI 应用大势所趋,低精度运算成为大规模 AI 训练&推理的标签特征——TPU v5支持大规模训练推理水到渠成。随着AI应用来到“ChatGPT”时刻,大语言模型达到数万亿参数,大规模 AI 计算时代已经到来。AI、高性能计算和数据分析变得日益复杂,AI 模型厂商有时愿意牺牲精度值来获取大模型训练的计算能力,也就是用高运算速度、低存储需求来加速计算过程。通过梳理我们发现,不止 TPU,GPGPU 也在向着低精度趋势发展。
2.2、集群层面:算力利用率是最好的证明
在AI 大模型预训练方面,谷歌 TPU 的算力利用率表现明显领先于英伟达。据量子位,算力利用率(MFU)是实际吞吐量与理论最大吞吐量之比。训练大语言模型并非简单的并行任务,需要在多个 GPU 之间分布模型,并且这些 GPU 需要频繁通信才能共同推进训练进程。通信之外,操作符优化、数据预处理和 GPU 内存消耗等因素,都对算力利用率(MFU)这个衡量训练效率的指标有影响。GPT-3 到 GPT-4明显看到算力利用率由 21.3%提升至 34%(32-36%区间,本文取中值粗略计算),趋势上较为明确。
横向对比发现,相较于 OpenAI 的 GPT 系列,谷歌利用 TPU 训练的Gropher 和 PaLM 明显在算力利用率上更胜一筹,我们认为谷歌自研 TPU 在自有大模型训练上展现出独特的优势。
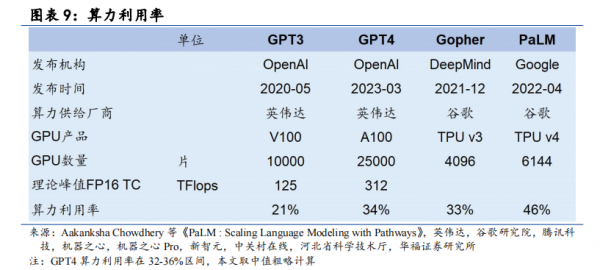
从训练效果上看,谷歌 TPU 也有不俗表现。22 年发布的第四代 TPU 在许多MLPerf 基准测试(最显著的是深度学习和卷积网络)上的表现优于英伟达。在 MLPerf五项基准测试中,TPUv4 性能比 A100 高出 40%。同时,在各 AI 厂商关注的训练成本上,谷歌的 TPU v4 相较于 A100 表现更优异。
#硬件优势 谷歌自研光学芯片 Palomar,从集群互连角度构建优势。谷歌设计TPU 的目的就是构建自己的超级计算机,如何高速度、低延迟地把尽可能多的 TPU芯片连接起来是一个不可避免的问题。谷歌又一次把握前瞻方向,在常规的互连拓扑结构中罕见地自研了光学芯片 Palomar(谷歌 TPU v4 设计的其中一个重点),使用该芯片实现了全球首个数据中心级的可重配置 OCS。在 Palomar 芯片加入后,立方体结构节点之间的互连并非一成不变的,而是可以现场重配置,这样做的最大好处是可以根据具体的机器学习模型来改变拓扑,以及改善超级计算机的可靠性。如下图所示,在使用可重配置光互连(以及光路开关时),系统有效吞吐量和利用率大幅提升。
#软件优势 TPU 专为 TensorFlow 打造,软件与硬件相辅相成。TensorFlow 是Google 的一个开源机器学习软件库。TPU 是根据 TensorFlow 设计的,从而能够降低运算精度,在相同时间内处理更复杂、更强大的机器学习模型并将其更快投入使用。
来源:架构师技术联盟
好文章,需要你的鼓励


Siri AI、ChatGPT、Claude真实横评,谁才是最强AI助手?
海外博主做了一次 Siri AI、ChatGPT、Claude 横评。看完之后我最大的感受是,AI 助手的竞争已经不只是模型能力,而是谁离用户更近。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。
2024
11/01
11:04
分享
点赞

