
电影角色大变身!MovieCharacter框架让角色视频合成更简单高效!
数源AI 最新论文解读系列

论文名:MovieCharacter: A Tuning-Free Framework for Controllable Character Video Synthesis
论文链接:https://arxiv.org/pdf/2410.20974.pdf
开源代码:https://moviecharacter.github.io/

引言
角色视频合成已成为计算机视觉和图形学领域的一个关键挑战,其多样化的应用领域包括电影制作、视频游戏开发、虚拟现实和交互媒体体验。最近在这一领域的进步,如神经渲染技术和深度生成模型,在产生逼真的角色动画和栩栩如生的场景方面取得了有希望的结果。然而,许多主流方法都需要大量的微调或依赖于复杂的3D建模技术。这些要求不仅阻碍了这些方法的可用性,还限制了它们在实时场景中的适用性,在实时场景中效率和响应性至关重要。因此,迫切需要创新解决方案来简化合成过程,使高质量的角色视频能够以更高效和用户友好的方式生成。解决这些挑战对于扩大角色视频合成在各种创意和交互应用中的潜力至关重要。
简介
角色视频合成的最新进展仍然依赖于广泛的微调或复杂的3D建模过程,这可能会限制可访问性并阻碍实时应用性。为了解决这些挑战,我们提出了一种简单而有效的无调整框架,名为MovieCharacter,旨在简化合成过程同时确保高质量的结果。我们的框架将合成任务分解为不同的、可管理的模块:角色分割和跟踪、视频对象去除、角色动作模仿和视频合成。这种模块化设计不仅促进了灵活的定制,还确保每个组件协同工作,有效满足用户需求。通过利用现有的开源模型并整合成熟的技术,MovieCharacter在不需要大量资源或专有数据集的情况下实现了令人印象深刻的合成结果。实验结果表明,我们的框架提高了角色视频合成的效率、可获取性和适应性,为更广泛的创意和交互式应用铺平了道路。
方法与模型
本文提出了一个名为MovieCharacter的无需调优的框架,用于解决电影角色视频合成问题。
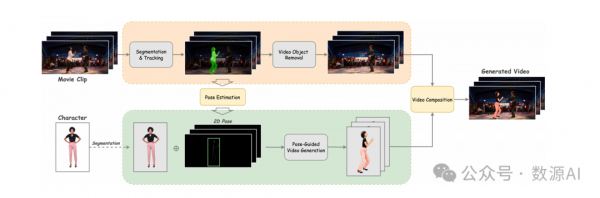
1、角色分割和跟踪
MovieCharacter需要精确地将角色从背景中分离出来,这可以通过用户提供的空间信息来启动。用户可以通过各种方法提供角色的空间信息,例如点击帧内特定点、定义包含角色的边界框,或手动创建勾勒出角色形状的遮罩。这些用户输入作为分割模型的关键提示PP,以准确识别并隔离初始帧中的角色。为了在整个剪辑V中实现连贯的替换,分割必须在所有后续帧中保持一致跟踪。在本文中,我们采用最先进的Segment Anything 2(SAM2)来完成这项任务。SAM2是一个强大的工具,它不仅能在第一帧中分割角色,还能跟踪整个帧的分割,确保角色替换过程的连续性和准确性。
通过SAM2获得的分割序列对于下游任务至关重要。这些包括视频对象去除,其中选定的角色从场景中完全移除,以及2D人体姿态估计,涉及分析角色在帧内的姿势和运动。分割序列的准确性和鲁棒性显著影响这些后续任务的有效性,突显了它在整体合成过程中的关键作用。
2、视频对象移除
实现角色合成的直观方法是将对目标角色的驱动姿势动作叠加到原始电影剪辑上。基于目标角色的姿势与电影场景中的姿势对齐,这是可行的,确保了一致性的整合。潜在的假设是,姿势作为一组抽象的运动数据,可以直接应用于旧剪辑,而不损害视觉连贯性。然而,这种简单性可能会以视觉降级的代价为代价。直接粘贴姿势可能无法解释新旧角色之间的微妙差异,例如身体类型、服装形状和运动动态的变化,这可能导致最终输出中的明显差异。

为了解决这些潜在的差异并提高组合视频的视觉质量,采用了更为细致的方法。这涉及到从视频中仔细去除旧角色的所有痕迹,从而为新角色的整合提供一个干净的背景。擦除旧角色及其相关元素的过程并不简单,需要使用复杂的工具来确保背景保持完整且无任何伪影。为了解决这些潜在的差异并提高组合视频的视觉质量,擅长填补被移除角色留下的空白,确保新旧角色之间的无缝且视觉上令人愉悦的过渡。通过利用ProPainter,我们可以在最终组合中实现高度的真实感,与当代视频制作中预期的美学标准相一致
3、角色运动模仿
角色动作模仿旨在使定制的角色II能够复制选定电影中目标角色的动作,确保合成的动作与目标的行为和视角一致。在这项工作中,我们将角色动作模仿任务重新构想为一个姿态引导的角色动画问题。姿态引导角色动画的最新进展主要集中在扩散模型上,这些模型通过高维姿态表示有效地捕捉复杂的运动动态。
4、视频合成
为了实现角色动作、外观和场景元素的无缝集成,提出了光照感知和视频和谐化技术,以及边缘感知视频细化技术。PCT-Net用于和谐化前景和背景的外观,确保时间上的连贯性。ProPainter用于进一步细化边缘区域,捕捉角色的细微差别,提高合成视频的边缘保真度和整体视觉质量。

实验与结果
实验细节
为了评估我们提出的框架的有效性,我们构建了一个包含经典电影剪辑的数据集,这些剪辑是从一个广泛使用的视频分享平台收集的。在我们的实验设置中,输入参考图像被调整为1024x768的分辨率,而输入视频则配置为1024x2048的分辨率。为了全面评估我们方法的鲁棒性和泛化能力,我们进行了大量专注于角色视频合成的实验。如图5所示,结果表明我们的方法始终能够产生高质量的输出,并且合成的角色无缝集成到电影剪辑中,验证了所提解决方案的有效性。
实验可视化结果

好文章,需要你的鼓励


依米康泰国接入数据中心温控交付,液冷生产线与焓差实验室补齐制造测试
今天讲的出海案例是依米康,这家数据中心温控与液冷设备厂商正在把泰国纳入海外交付体系,并用生产线、总装车间和焓差实验室承接算力设施订单。

人民大学、上海AI实验室等联合打造的“全能生物AI“:一个模型搞定分子、蛋白质和自然语言的终极尝试
BioMatrix是首个将分子序列、分子三维结构、蛋白质序列、蛋白质三维结构和自然语言统一在单一语言模型中的生物基础模型,在80项任务中77项达到最优或第二优。

Craig Primack博士:远程医疗如何填补肥胖症诊疗缺口
美国远程医疗巨头Hims & Hers完成对澳大利亚竞争对手Eucalyptus的收购后,正式进军英国、德国、日本等市场。公司肥胖症业务负责人Craig Primack博士表示,肥胖症是慢性、复发性疾病,需综合治疗方案而非单纯开药。远程医疗能填补NHS等公共医疗体系的服务缺口,为患者提供药物、营养、运动及生活方式的全方位支持,并在GP停诊时提供及时的医疗咨询。

浙江大学研究团队打造“技能护栏“:让AI电脑助手在危险环境中也能安全学习和工作
浙江大学提出SKILLHARNESS框架,通过为AI电脑助手的每项技能附加安全边界,从成功、失败和风险三类经历中学习,使AI在动态危险环境中安全高效地完成任务。
2024
11/01
11:04
分享
点赞

