
腾讯放大招,超Meta!史上参数最大,开源专家混合模型
开源大模型领域迎又来一位重磅玩家——腾讯。
腾讯一出手就是个超大模型,开源的Hunyuan-Large是目前市面上最大基于 Transformer架构的专家混合(MoE)模型。一共有3890 亿参数,其中激活参数为 520 亿,具备处理长达256K上下文能力。
根据腾讯公开测试数据显示,Hunyuan-Large不仅超过了社交巨头Meta开源的最新、最大模型LLama3.1 - 405B,并且在激活参数数量显著减少的情况下,实现了高达3.2%的性能提升。在数学、日常推理、文本生成等方面非常优秀。
开源地址:https://github.com/Tencent/Tencent-Hunyuan-Large
huggingface:https://huggingface.co/tencent/Tencent-Hunyuan-Large
云开发平台:https://cloud.tencent.com/document/product/851/112032
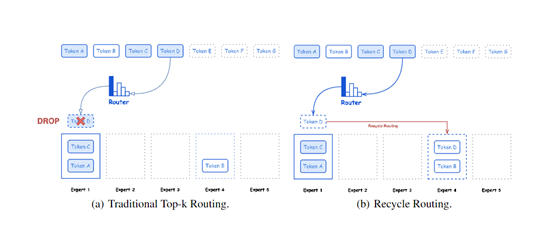
Hunyuan-Large采用了高效的MoE结构,使用多个专家替换了Transformer中的原始前馈网络。在训练过程中,只有一小部分专家会被激活,这样的设计使得模型能够更加高效地进行训练和推理。
一共包含共享专家和专用专家两种模式,不仅能够捕捉所有token所需的共同知识,还能够动态学习特定领域的知识。同时Hunyuan-Large还开发了一种新的回收路由策略,用于处理在原始top-k路由过程中被丢弃的token。这种策略通过将这些token重新分配给未超过容量的其他专家,以优化训练效率和稳定性。
Hunyuan-Large还对KV缓存进行了创新,使用了压缩技术。在传统的Transformer架构中,每层都会维护一个用于存储先前计算出的键值对的缓存,这对于支持长序列输入非常必要。但随着序列长度的增长,这种缓存机制会导致巨大的内存开销。
而KV缓存压缩技术通过减少KV缓存的存储需求来降低内存占用,同时保持了模型对于长序列处理的能力,可以有效地减少键值对的存储空间,而不牺牲准确性或速度。即使面对非常长的文本输入,模型也能高效运行,不会因为内存限制而受到阻碍。
在专家特定的学习率缩放方面,Hunyuan-Large采用了AdamW作为优化器,并根据批量大小调整学习率。根据最新的研究,对于Adam风格的优化器,最佳学习率与批量大小之间的关系有了新的理解。Hunyuan-Large根据每个专家在单次迭代中处理的token数量不同,为不同专家分配了不同的学习率,以优化训练效率。
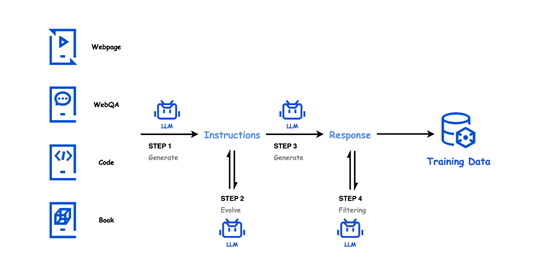
训练数据方面,Hunyuan-Large一共使用了7万亿token数据进行了预训练,其中包括近1.5万亿的高质量和多样化的合成数据。这些合成数据的生成过程涉及四个关键步骤:指令生成、指令演化、响应生成和响应过滤。
在指令生成阶段,利用高质量的数据源,如网页、问答数据、代码库、书籍等,配合多样化的指令生成提示,生成覆盖多个领域的多样化指令。在指令演化阶段,通过增强指令的清晰度和信息量、扩展低资源领域指令以及增加指令难度等手段,进一步提升指令的质量。
响应生成阶段则利用多个专业化模型为这些演化后的指令生成信息丰富、准确的答案。最后,在响应过滤阶段,通过批评模型和自一致性检查,确保合成的指令-响应对的质量,有效去除低质量或不一致的数据。
在Hunyuan-Large的训练过程中,学习率调度扮演了至关重要的作用,一共分为三个阶段:初始的预热阶段、随后的逐渐衰减阶段,以及最后的退火阶段。这种设计使得模型能够在初始阶段有效地探索解空间,避免过早收敛到次优的局部最小值。随着训练的进行,学习率的逐渐降低确保了模型能够向更优解收敛。
在预训练的最后5%阶段,Hunyuan-Large引入了退火阶段,将学习率降低到峰值的十分之一。这有助于模型细致地调整参数,实现更高的泛化能力,从而提升整体性能。在这个阶段,模型优先使用最高质量的数据集,这对于增强模型在退火阶段的性能至关重要。
在退火阶段之后,Hunyuan-Large还进行了长文本预训练,以增强其处理长文本的能力,逐渐增加token长度从32K增长至256K。Hunyuan-Large采用了RoPE来构建位置嵌入,并在256K预训练阶段将RoPE的基础频率扩展到10亿。
长文本预训练的数据主要来自书籍和代码等自然长文本数据,这些数据与正常长度的预训练数据混合,形成了长文本预训练语料库。
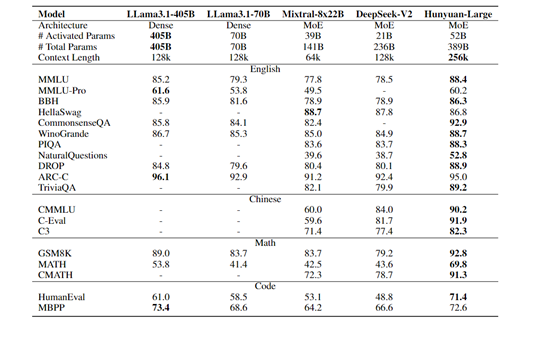
腾讯将Hunyuan-Large与LLama3.1-405B、LLama3.1-70B、Mixtral-8x22B和DeepSeek-V2市面上超大开源模型进行了综合评测。
结果显示,Hunyuan-Large皆取得了超强的性能表现,例如,在CommonsenseQA测试中,Hunyuan-Large 的准确率达到 92.9%,而 LLama3.1 - 70B 为 84.1%,LLama3.1 - 405B 为 85.8%。
在PIQA 测试中,Hunyuan-Large 的准确率为 88.3%,优于LLama3.1 - 405B的83.7%。在WinoGrande 测试中,Hunyuan-Large的准确率达到 88.7%,超过了LLama3.1 - 70B 的 85.3%和LLama3.1 - 405B的86.7%。
来源:AIGC开放社区
好文章,需要你的鼓励


依米康泰国接入数据中心温控交付,液冷生产线与焓差实验室补齐制造测试
今天讲的出海案例是依米康,这家数据中心温控与液冷设备厂商正在把泰国纳入海外交付体系,并用生产线、总装车间和焓差实验室承接算力设施订单。

人民大学、上海AI实验室等联合打造的“全能生物AI“:一个模型搞定分子、蛋白质和自然语言的终极尝试
BioMatrix是首个将分子序列、分子三维结构、蛋白质序列、蛋白质三维结构和自然语言统一在单一语言模型中的生物基础模型,在80项任务中77项达到最优或第二优。

Salesforce推出Help Agent,简化AI客服部署流程
Salesforce正式推出Help Agent,这是基于Agentforce平台的预封装AI客服智能体,可在数分钟内连接企业知识库、操作功能及网页、短信、语音等沟通渠道。该产品同步推出按解决率计费模式,每次成功自主解决客户问题收费2美元,无需按token或操作次数计费。Help Agent支持低代码构建,内置测试功能,并配备全新客户服务门户。该产品预计于2026年7月正式上线。

浙江大学研究团队打造“技能护栏“:让AI电脑助手在危险环境中也能安全学习和工作
浙江大学提出SKILLHARNESS框架,通过为AI电脑助手的每项技能附加安全边界,从成功、失败和风险三类经历中学习,使AI在动态危险环境中安全高效地完成任务。
2024
11/06
20:04
分享
点赞

