
AI服务器核心部件产业链剖析(2024)
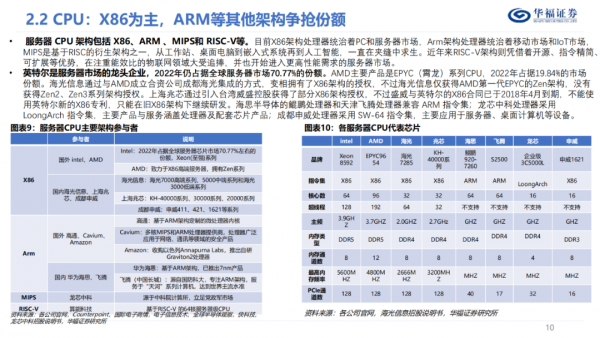
AI服务器产业链包括芯片CPU、GPU,内存DRAM和内存接口及HBM,本地存储SSD,NIC、PCle插槽、散热和等。服务器CPU架构包括X86、ARM、MIPS和RISC-V等。
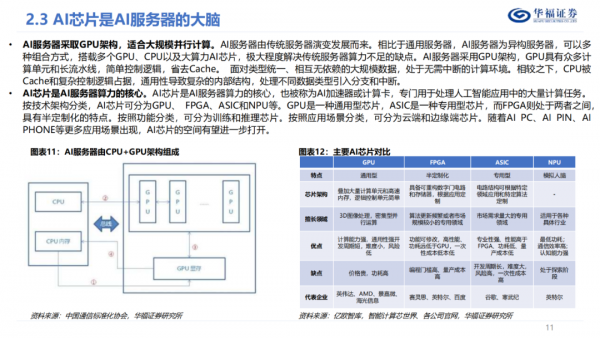
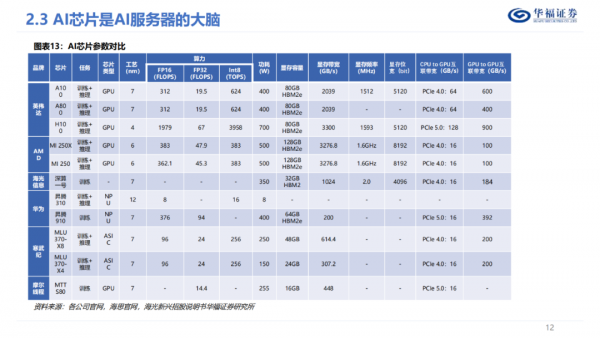
Al芯片是AI服务器算力的核心,专门用于处理人工智能应用中的大量计算任务,Al芯片按架构可分为GPU、FPGA、ASIC和NPU等。HBM作为内存产品的一种,已经成为高端GPU标配,可以理解为与CPU或SoC对应的内存层级,将原本在PCB板上的DDR和GPU芯片同时集成到SiP封装中,使内存更加靠近GPU,使用HBM可以将DRAM和处理器(CPU,GPU以及其他ASIC)之间的通信带宽大大提升,从而缓解这些处理器的内存墙问题。
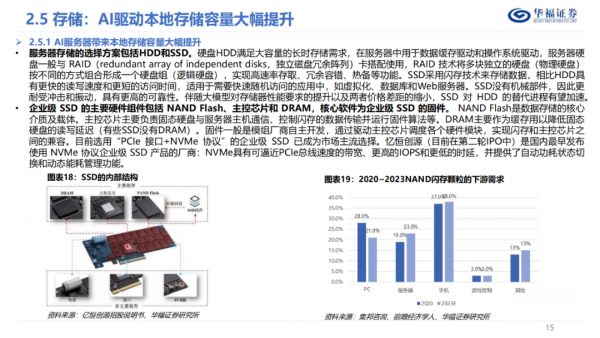
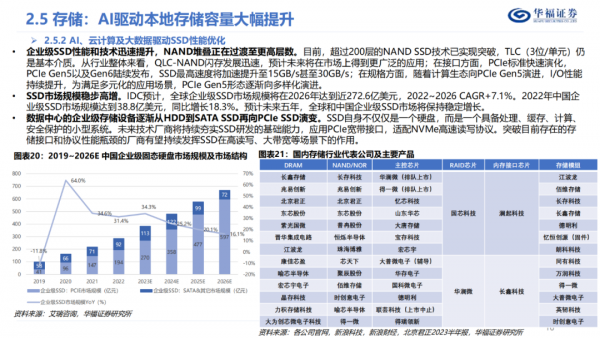
服务器本地存储的选择方案则包括HDD和SSD,SSD的主要硬件组件包括NAND Flash、主控芯片和DRAM,核心软件为企业级SSD的固件,数据中心级SSD已不再是一个硬盘,而是一个具备处理、缓存、计算、安全保护的小型系统,SSD渗透率有望逐渐提升。













好文章,需要你的鼓励


奥运级别的努力:首席信息官为2026年AI颠覆做准备
AI颠覆预计将在2026年持续,推动企业适应不断演进的技术并扩大规模。国际奥委会、Moderna和Sportradar的领导者在纽约路透社峰会上分享了他们的AI策略。讨论焦点包括自建AI与购买第三方资源的选择,AI在内部流程优化和外部产品开发中的应用,以及小型模型在日常应用中的潜力。专家建议,企业应将AI建设融入企业文化,以创新而非成本节约为驱动力。

字节跳动发布GAR:让AI能像人类一样精准理解图像任何区域的突破性技术
字节跳动等机构联合发布GAR技术,让AI能同时理解图像的全局和局部信息,实现对多个区域间复杂关系的准确分析。该技术通过RoI对齐特征重放方法,在保持全局视野的同时提取精确细节,在多项测试中表现出色,甚至在某些指标上超越了体积更大的模型,为AI视觉理解能力带来重要突破。

Spotify推出AI播放列表功能让用户掌控推荐算法
Spotify在新西兰测试推出AI提示播放列表功能,用户可通过文字描述需求让AI根据指令和听歌历史生成个性化播放列表。该功能允许用户设置定期刷新,相当于创建可控制算法的每周发现播放列表。这是Spotify赋予用户更多控制权努力的一部分,此前其AI DJ功能也增加了语音提示选项,反映了各平台让用户更好控制算法推荐的趋势。

Inclusion AI推出万亿参数思维模型Ring-1T:首个开源的超大规模推理引擎如何重塑AI思考边界
Inclusion AI团队推出首个开源万亿参数思维模型Ring-1T,通过IcePop、C3PO++和ASystem三项核心技术突破,解决了超大规模强化学习训练的稳定性和效率难题。该模型在AIME-2025获得93.4分,IMO-2025达到银牌水平,CodeForces获得2088分,展现出卓越的数学推理和编程能力,为AI推理能力发展树立了新的里程碑。
2024
11/06
21:04
分享
点赞

