
国产模型炸裂登场,国外赞不绝口!OpenAI-o1级性能,免费使用
昨晚,国产大模型平台DeepSeek发布了,全新推理模型DeepSeek-R1-Lite预览版。
这个模型的最大特色便是深度思维链推理,尤其是在数学、代码以及各种复杂推理任务上,可以生成数万字的推理流程,让用户深度了解模型生成内容的全过程。
例如,连GPT-4o等模型都搞错的9.11比9.9更大的“难题”,R1通过超长思维链推理可以轻松搞定。
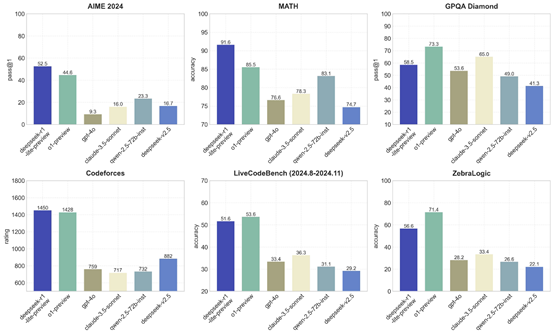
值得一提的是, R1在美国数学邀请赛AIME 2024、MATH和Codeforces的测试数据分别是52.5、91.6、1450击败了OpenAI的o1预览版,并且开源模型和API也将很快发布。
R1发布后得到了大量国外网友的赞扬。有网友表示,DeepSeek发布了R1,OpenAI将迎来劲敌,迫使他们尽快发布o1满血版。

了不起的工作!能超越 o1-preview 是一个巨大的成就!

这太不可思议了!如果你只是用这个推理模型来处理推理任务,并为其他事情使用传统的语言模型,那么一天 50 条消息对于普通人来说确实已经足够了。干得好,来自巴西的祝贺!

我刚刚用高度复杂的研究问题测试了 @deepseek_ai 发布的深度思考模型。它的思考和推理过程让我大为震撼!在我看来,这达到了高级博士水平,而且在某些情况下,它的推理远胜于 o1-preview!我感到敬畏。
非常好!期待你们的API。

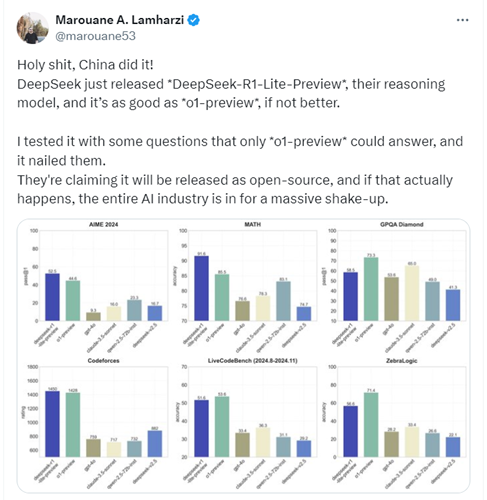
天啊,中国做到了!DeepSeek 刚刚发布了DeepSeek-R1-Lite-Preview,他们的推理模型,表现和 o1-preview* 一样好,甚至更好。
我用一些只有 o1-preview能回答的问题测试了它,它完美解决了。并且即将开源,如果真的发生,这将对整个AI行业产生巨大冲击。
能够看到 DeepSeek 的思维推理过程真的太好了。

我试用了这个模型,在某些任务的编码方面,似乎仍然不如 o1-preview。但我觉得它的数学能力更强。整体表现差不多,我真的希望OpenAI 现在发布 o1-full版本。
实时透明的思维过程非常重要!我们可以看到它的思考过程,这真是令人惊叹。

能有另一个大脑一起工作总是很棒的。干得好!

非常棒!
我非常震惊。可见的思维链对于开放式 AI 研究来说是一个重大突破。祝贺你们!

太疯狂了,什么时候开放API?

也有网友放上了R1的测试视频:由 @deepseek_ai 开源的 R1 模型轻松地‘思考’了 100 多秒,并生成了超过 7500 个连贯的tokens!
是时候认真对待开源模型了。DeepSeek 刚刚通过它的新模型 R1-lite 改变了游戏规则。通过像 o1 一样扩展测试时的计算,并且‘思考’时间更长(我试的时候大约 5 分钟),它在 MATH 基准测试中达到了 91.6% 的最先进水平!感觉都去试试吧!
目前,DeepSeek还没有开放R1的论文,但可以免费在线使用了,每天提供50次深度思维推理。就像上面网友说的,只要不是专门搞科研、编程开发,这足够用了。
「AIGC开放社区」体验了一下确实推理流程很强且透明化。我们就问一个非常经典,让无数大模型头疼的问题吧——9.11和9.9到底哪个大。
先试了一下GPT-4o mini,依然给出了9.11比9.9更大的错误答案,问多少次都这样。

在试试R1,在没开启超强思维链的情况下,就已经回答正确了9.9更大。
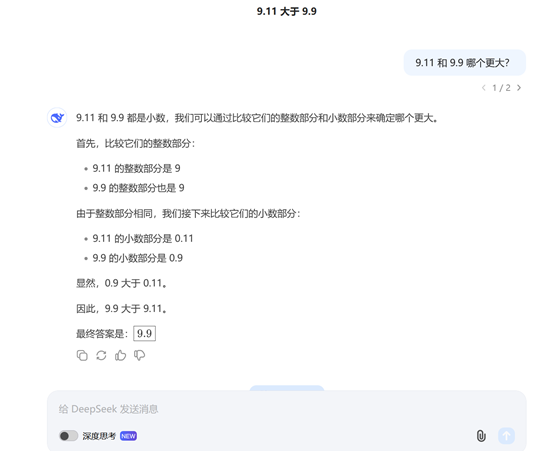
开启深度思考试一下,R1会把所有的思考和不断反思流程展现出来,非常长,最终结果还是9.9。



目前,R1每天免费提供50次深度思维链推理,有兴趣的小伙伴可以试试。
免费体验:https://chat.deepseek.com/a/chat/
好文章,需要你的鼓励


iOS 27 大幅重新设计 AirPods 设置界面,全新布局抢先看
苹果在WWDC上正式发布iOS 27,首个开发者测试版随即上线。新系统对AirPods设置界面进行了全面重构:原本冗长混乱的开关列表被整合为结构清晰的分类菜单,每个选项配有图标,便于快速识别。主设置页面也因此大幅精简。AirPods设置仍位于iPhone设置顶部,仅在设备连接时显示。此次改版显著提升了使用体验,但独立AirPods应用仍未出现。

上交大联手蚂蚁集团:让AI视频生成只需“一步“,告别卡顿与漂移的新方案
AAD-1由上交大、蚂蚁集团等机构联合提出,通过双向判别器与三阶段训练,实现了单步自回归视频生成,有效解决了动作崩溃与长期漂移问题。

丰田与雷克萨斯首款三排座纯电SUV即将上市
丰田大型纯电SUV Highlander BEV与雷克萨斯首款三排纯电SUV TZ计划于2026年底上市。两款车型均基于TNGA平台打造,搭载最大95.82kWh电池组,续航里程分别可达320英里和300英里。雷克萨斯TZ标配DIRECT4四驱系统,综合功率420马力,支持150kW快充,约35分钟可从10%充至80%,并内置NACS接口。预计Highlander BEV起售价约5万美元,TZ约6万美元。

浙江大学联合蚂蚁集团:AI“侦探“如何从不同角度认出同一个场景?
论文提出ReasonMatch-Bench基准评测AI跨视角空间匹配能力,并通过动态课程强化学习方法DCRL显著提升多模态大模型的宽基线匹配性能,超越多个顶尖商业AI。
2024
11/22
15:04
分享
点赞

