强推理模型书生InternThinker开放体验:自主生成高智力密度数据、具备元动作思考能力
上海AI实验室的研究团队创新性地设计了元动作思考范式来引导模型的搜索空间,使模型更高效地习得和产生多样化的推理策略组合;基于通专融合的方式进行数据合成,并通过构建大规模沙盒环境获取反馈,在不依赖o1这类已有强推理模型的情况下,实现高质量思维链的独立构建,并大幅提升模型的复杂任务处理性能。

上海人工智能实验室(上海AI实验室)致力于通过“通专融合”路径探索开放、可控、可信的通用人工智能(AGI),其关键技术之一在于同步提升深度推理与专业泛化能力。
2024年11月25日,上海AI实验室展示了自主生成高智力密度数据、具备元动作思考能力的“模型”等一系列创新进展,并开放强推理模型书生InternThinker试用体验。该模型具备长思维能力,并能在推理过程中进行自我反思和纠正,从而在数学、代码、推理谜题等多种复杂推理任务上取得更优结果。
试用链接:https://internlm-chat.intern-ai.org.cn(点击文末“阅读原文”直达,登录后点击左侧InternThinker即可体验)。
在OpenAI o1模型发布之前,上海AI实验室就已开展了相关技术的独创性探索与实践:在训练数据侧,在国内率先开发出大规模合成数据技术;在任务场景侧,新模型在数学、代码、推理谜题等多种场景都能体现出较强的推理能力,并具备一定的任务泛化性。
上海AI实验室的研究团队创新性地设计了元动作思考范式来引导模型的搜索空间,使模型更高效地习得和产生多样化的推理策略组合;基于通专融合的方式进行数据合成,并通过构建大规模沙盒环境获取反馈,在不依赖o1这类已有强推理模型的情况下,实现高质量思维链的独立构建,并大幅提升模型的复杂任务处理性能。
强大的推理能力是迈向通用人工智能的重要基础,今年7月发布的书生·浦语2.5实现了开源模型中领先的推理能力,InternThinker则使大模型的推理能力再上新台阶。下一步,上海AI实验室将把相关技术融入下一代书生大模型,并继续沿着通专融合发展路径,通过开源与产学研各界共同推动技术进步。
为高效提升模型的推理能力,InternThinker采用了更接近人类学习方式的路径。
人在学习解决复杂推理任务时,并非从海量的样本中进行单点知识的学习,而是思维模式的学习——在解决问题的过程中,通过回忆相关知识点,对正确的解题过程进行理解、记忆,对错误解题等过程进行反思和修正,即对自我的认知过程进行觉察和调节——该能力也被称作元认知能力。元认知理论的相关研究发现,通过显式地引导和感知人在解决问题过程中的思想模式,可提升复杂任务的学习和解决效果。
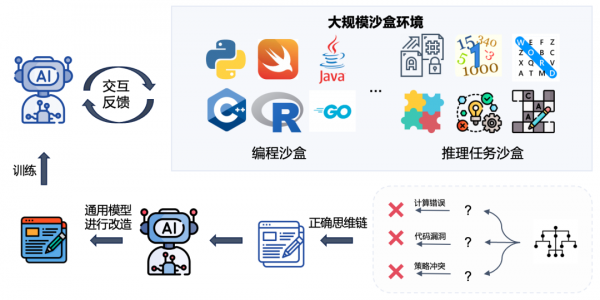
受元认知理论的启发,研究团队设计了一系列元动作来引导模型解决问题的过程,如对问题的理解、知识回忆、规划、执行、反思、总结等。模型在面对复杂任务时,会显式且动态地选择元动作,再进一步展开相关动作的具体思维过程。通过这种设计,利用部分训练任务,可强化模型对关键元动作组合的使用,显著提升模型学习效率。
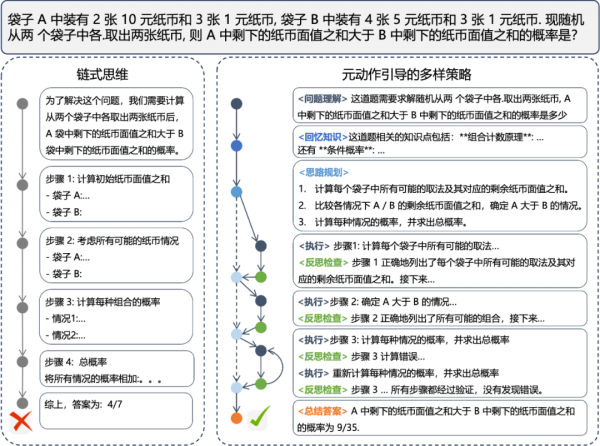
在未经元动作引导和学习的情况下,模型在解决问题时多采用链式推理策略(如下图左侧所示),难以解决更加复杂的任务并进行自我纠错。而经过元动作的引导和学习后,模型能够在解决复杂任务时自发使用“回忆知识-解答”,“执行-反思”等策略组合。
研究团队认为,模型在思考过程中能更灵活、多样、有效地使用元动作,是模型在推理阶段能够利用更多思考时间解决更复杂任务的重要原因。
高密度监督数据路径框架
获取已有强推理模型的思维链数据并进行蒸馏,是提升数学等榜单性能及复现强推理模型的“捷径”。
InternThinker则率先独创性地采用了基于通专融合的技术路线生产所需数据。研发团队设计了多种通用模型和专业模型的协作流程:首先基于专家模型搜索出针对复杂任务的正确解决轨迹(但这种轨迹数据并不直接适用于元动作思维能力的训练);进而由通用模型对复杂任务解决过程进行觉察、分析、改造和质量完善,基于正确轨迹提升思维链的格式规范性和可学习性,最终产出用于模型训练的数据。在此过程中,模型和数据会交替迭代,达到协同增强的效果。
面对丰富多样的推理任务,如何准确地获得过程和结果反馈尤为关键。为此,研究人员针对专业任务构建了大规模的沙盒环境,为可形式化验证的推理任务提供反馈信号,包括数十种编程语言的高效率代码执行编译环境,以及代码领域之外的通用推理任务沙盒。
通过自动化专家模型、人机协同策略生成等方法,构建了超过50种不同逻辑思维方式的推理任务思考过程,通过沙盒环境提供思考过程的反馈,形成自下而上对模型思维能力的构建,为模型的自主演进提供精准的反馈信号,从而高效地将专业任务的能力融合到InternThinker中。
下面是一道2024年9月全国高中生数学竞赛联赛的题目。模型会先回忆相关的知识点,然后逐步进行推理和计算,最终形成解答。
接下来是挑战类似“24点”但难度更高的问题。可以看到模型会先进行尝试,发现“此路不通”后当即会换一条路径,展现出了InternThinker的反思和修正能力。
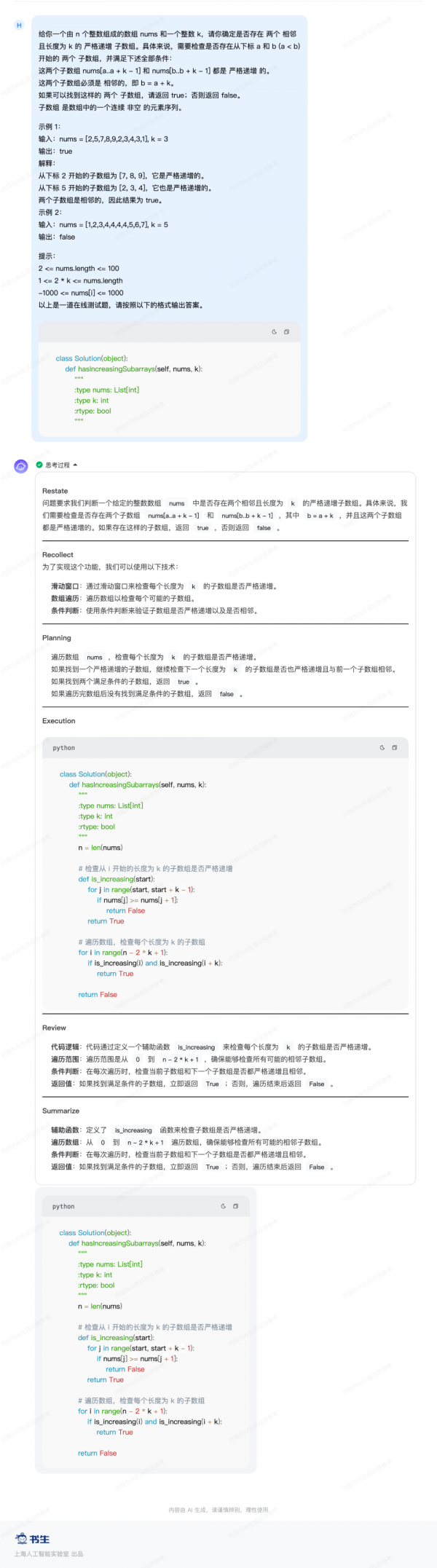
在Leetcode(面向全球 IT 人才的技能成长平台)本月新近的赛题中,InternThinker不仅很好地回答了问题,而且在编写完代码之后还进行了仔细的检查。
最后,给InternThinker提一个抽象的推理问题,让模型找到矩阵变换的规律(这里将矩阵渲染成方块便于可视化,不同数字用不同颜色表示,其中白色表示0)。
InternThinker同时也可以执行填字游戏任务。
InternThinker模型仍在持续迭代中,欢迎广大用户及开发者试用及反馈。试用链接:https://internlm-chat.intern-ai.org.cn(登录后点击左侧“InternThinker”即可体验)。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
“在中国公有云上,每产生两个tokens,就有一个是由火山引擎生产。”
Allen AI研究所联合多家顶尖机构推出SAGE智能视频分析系统,首次实现类人化的"任意时长推理"能力。该系统能根据问题复杂程度灵活调整分析策略,配备六种智能工具进行协同分析,在处理10分钟以上视频时准确率提升8.2%。研究团队创建了包含1744个真实娱乐视频问题的SAGE-Bench评估平台,并采用创新的AI生成训练数据方法,为视频AI技术的实际应用开辟了新路径。
联想推出新一代NVMe存储解决方案DE6600系列,包含全闪存DE6600F和混合存储DE6600H两款型号。该系列产品延迟低于100微秒,支持多种连接协议,2U机架可容纳24块NVMe驱动器。容量可从367TB扩展至1.798PiB全闪存或7.741PiB混合配置,适用于AI、高性能计算、实时分析等场景,并配备双活控制器和XClarity统一管理平台。
中科院团队首次系统评估了AI视觉模型在文本压缩环境下的理解能力,发现虽然AI能准确识别压缩图像中的文字,但在理解深层含义、建立关联推理方面表现不佳。研究通过VTCBench测试系统揭示了AI存在"位置偏差"等问题,为视觉文本压缩技术的改进指明方向。