
收藏:InfiniBand网络架构浅析
- 1、由于采用了基于总线的共享传输模式,在PCI总线上不可能同时传送两组以上的数据,当一个PCI设备占用总线时,其他设备只能等待;
- 2、随着总线频率从33MHz提高到66MHz,甚至133MHz(PCI-X),信号线之间的相互干扰变得越来越严重,在一块主板上布设多条总线的难度也就越来越大;
- 3、由于PCI设备采用了内存映射I/O地址的方式建立与内存的联系,热添加PCI设备变成了一件非常困难的工作。目前的做法是在内存中为每一个PCI设备划出一块50M到100M的区域,这段空间用户是不能使用的,因此如果一块主板上支持的热插拔PCI接口越多,用户损失的内存就越多;
- 4、PCI的总线上虽然有buffer作为数据的缓冲区,但是它不具备纠错的功能,如果在传输的过程中发生了数据丢失或损坏的情况,控制器只能触发一个NMI中断通知操作系统在PCI总线上发生了错误;
Infiniband的协议层次与网络结构
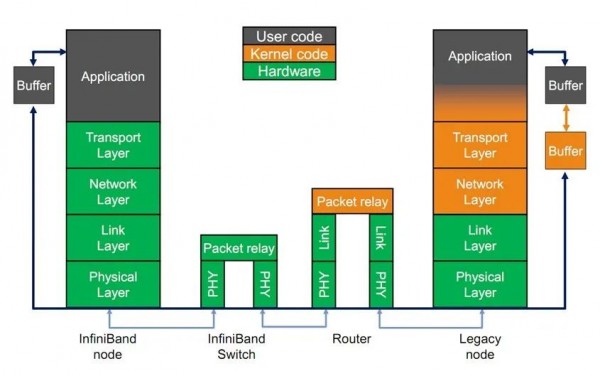
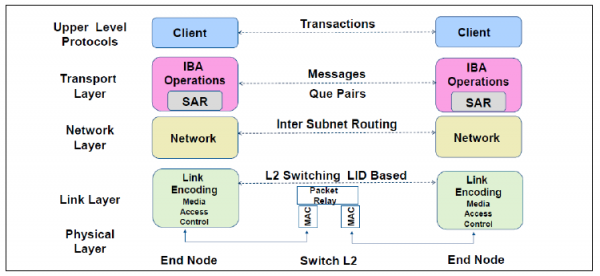
- 物理层:定义了电气特性和机械特性,包括光纤和铜媒介的电缆和插座、底板连接器、热交换特性等。定义了背板、电缆、光缆三种物理端口。
- 链路层:描述了数据包的格式和数据包操作的协议,如流量控制和子网内数据包的路由。链路层有链路管理数据包和数据包两种类型的数据包。
- 网络层:是子网间转发数据包的协议,类似于IP网络中的网络层。实现子网间的数据路由,数据在子网内传输时不需网络层的参与。
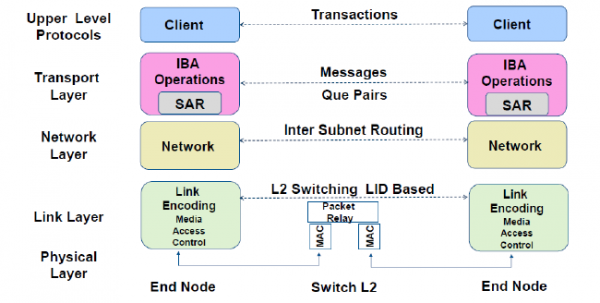
- 传输层:负责报文的分发、通道多路复用、基本传输服务和处理报文分段的发送、接收和重组。传输层的功能是将数据包传送到各个指定的队列(QP)中,并指示队列如何处理该数据包。当消息的数据路径负载大于路径的最大传输单元(MTU)时,传输层负责将消息分割成多个数据包。
- 上层网络协议:InfiniBand为不同类型的用户提供了不同的上层协议,提供应用程序与硬件驱动之间的Verbs接口,允许上层应用基于Verbs接口进行RDMA编程;并为某些管理功能定义了消息和协议。InfiniBand主要支持SDP、SRP、iSER、RDS、IPoIB和uDAPL等上层协议。
Infiniband网络拓扑结构
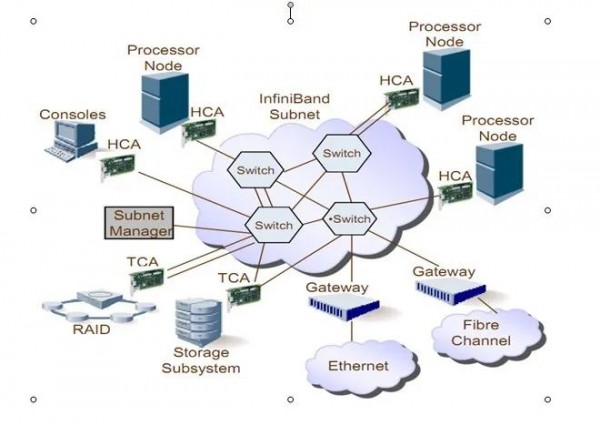
- (1)HCA(Host Channel Adapter),它是连接内存控制器和TCA的桥梁;
- (2)TCA(Target Channel Adapter),它将I/O设备(例如网卡、SCSI控制器)的数字信号打包发送给HCA;
- (3)Infiniband link,它是连接HCA和TCA的光纤,InfiniBand架构允许硬件厂家以1条、4条、12条光纤3种方式连结TCA和HCA;
- (4)交换机和路由器;
Omni-Path沿用了True Scale产品名称和技术(收购QLogic InfiniPath网络产品线,改名True Scale),主要的变化是在把物理层把速度从40G提到了100G。为了兼容更加开源的系统,Omni-Path也是基于开源标准的OFED架构(Mellanox也是采用该框架),并将API接口开放。
OPA组件
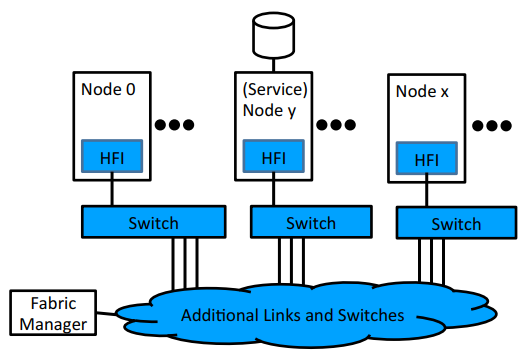
- HFI – Host Fabric Interface 提供主机,服务和管理节点的光纤连接
- Switches 提供大规模的节点之间的任意拓扑连接
- Fabric Manager 提供集中化的对光纤资源的provisioning 和监控
相比InfiniBand ,Intel Omni-Path Architecture 架构设计目标特性:
- 通过CPU/Fabric integration 来提高cost, power, and density
- Host主机端的优化实现来高速的MPI消息,低延迟的高扩展性的架构
- Enhanced Fabric Architecture 来提供超低的端到端延迟,高效的纠错和增强的QoS,并且超高的扩展性
RDMA技术

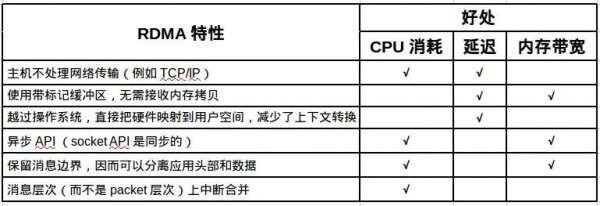
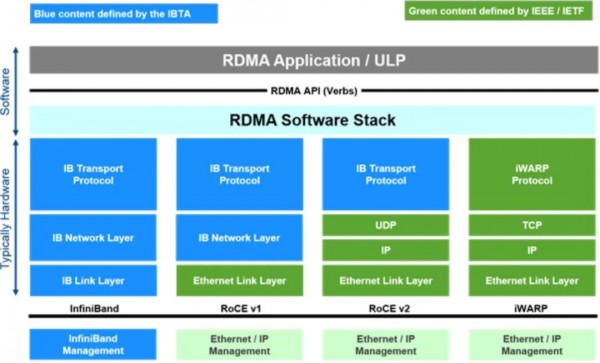

解析RDMA over TCP(iWARP)协议栈和工作原理
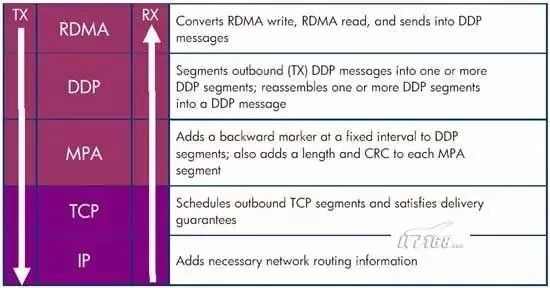
- 内存Verbs(Memory Verbs),也叫One-SidedRDMA。包括RDMA Reads, RDMA Writes, RDMA Atomic。这种模式下的RDMA访问完全不需要远端机的任何确认。
- 消息Verbs(Messaging Verbs),也叫Two-SidedRDMA。包括RDMA Send, RDMA Receive。这种模式下的RDMA访问需要远端机CPU的参与。
上层协议
- SDP(SocketsDirect Protocol)是InfiniBand Trade Association (IBTA)制定的基于infiniband的一种协议,它允许用户已有的使用TCP/IP协议的程序运行在高速的infiniband之上。
- SRP(SCSIRDMA Protocol)是InfiniBand中的一种通信协议,在InfiniBand中将SCSI命令进行打包,允许SCSI命令通过RDMA(远程直接内存访问)在不同的系统之间进行通信,实现存储设备共享和RDMA通信服务。
- iSER(iSCSIRDMA Protocol)类似于SRP(SCSI RDMA protocol)协议,是IB SAN的一种协议 ,其主要作用是把iSCSI协议的命令和数据通过RDMA的方式跑到例如Infiniband这种网络上,作为iSCSI RDMA的存储协议iSER已被IETF所标准化。
- RDS(ReliableDatagram Sockets)协议与UDP 类似,设计用于在Infiniband 上使用套接字来发送和接收数据。实际是由Oracle公司研发的运行在infiniband之上,直接基于IPC的协议。
- IPoIB(IP-over-IB)是为了实现INFINIBAND网络与TCP/IP网络兼容而制定的协议,基于TCP/IP协议,对于用户应用程序是透明的,并且可以提供更大的带宽,也就是原先使用TCP/IP协议栈的应用不需要任何修改就能使用IPoIB。
- uDAPL(UserDirect Access Programming Library)用户直接访问编程库是标准的API,通过远程直接内存访问 RDMA功能的互连(如InfiniBand)来提高数据中心应用程序数据消息传送性能、伸缩性和可靠性。
其中IPoIB
- IPoIB(IP-over-IB)是为了实现INFINIBAND网络与TCP/IP网络兼容而制定的协议,基于TCP/IP协议,对于用户应用程序是透明的,并且可以提供更大的带宽,也就是原先使用TCP/IP协议栈的应用不需要任何修改就能使用IPoIB。
- IPoIB的作用是在InfiniBand RDMA网络之上提供一个IP网络仿真层。
- 因为iWARP和RoCE/IBoE网络实际上都是基于RDMA的IP网络,所以它们不需要IPoIB。因此,内核将拒绝在iWARP或RoCE/IBoE RDMA设备之上创建任何IPoIB设备。
IPoIB局限性
- IPoIB为我们解决了很多问题。但是,与标准的以太网网络接口相比,它有一些局限性:
- IPoIB只支持基于ip的应用程序(因为以太网报头没有封装)。
- SM/SA必须随时可用,以便IPoIB发挥作用。
- IPoIB网络接口的MAC地址为20字节。
- 网络接口的MAC地址不能被用户控制。
- IPoIB网络接口的MAC地址在IPoIB模块的连续加载中可能会发生变化,而且它不是持久的(即接口的一个常量属性)。
- 在IPoIB网络接口中配置vlan需要了解对应的p_key的SM。
参考:
http://www.rdmamojo.com/2015/02/16/ip-infiniband-ipoib-architecture/
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/networking_guide/sec-configure_ipoib_using_a_gui
http://www.rdmamojo.com/2015/04/21/working-with-ipoib/
https://weibo.com/p/1001603936363903889917
来源:架构师技术联盟
好文章,需要你的鼓励


Decagon:让企业重掌客户关系主导权
多家企业通过Decagon的AI客服平台实现了显著成效:一家财富50强企业在三周内完成了九个月未竟的工作;一家航空公司从启动到全面上线仅用三周;一家音乐流媒体平台六个工作日即投入生产,AI处理率达71%。Decagon以"玻璃盒"而非"黑盒"理念构建,通过AOPs和Duet工具赋能企业运营者自主部署和迭代AI客服,真正将客户关系的主导权还给企业本身。

东南大学、南京大学、微软研究院联手打造:让机器人真正“看懂世界、动起来“的统一推理引擎
东南大学等机构联合推出Embodied.cpp,一个面向机器人AI的C++统一推理运行时,首次同时支持VLA和WAM两类模型的边缘部署与闭环控制。

2026年Q2芯片与AI硬件创投融资全景报告
2026年第二季度,AI硬件、量子计算及芯片制造领域融资持续火热。边缘AI芯片时隔多年重获投资者青睐,量子计算领域有21家公司完成融资,其中6家超亿美元。本季度共18家企业融资超1亿美元,涵盖SiFive(4亿美元)、Etched(5亿美元)、Nearfield Instruments(3.8亿美元)等重磅融资,日本Rapidus获政府补贴约9.43亿美元,80家企业合计融资逾60亿美元。

加州大学伯克利与多伦多大学联手破解:为什么“老方法“在高维数据搜索中反而越来越好用?
这项多校联合研究系统评测了多探针网格近似最近邻搜索算法,发现其在高维数据上的性能退化明显弱于主流方法,且建索引速度快约百倍,在高频重建场景下具有竞争力。
2024
12/09
11:04
分享
点赞

