ЮЂШэЗЂВМЕкЫФДњPhiЯЕСаДѓФЃаЭЃЌ140вкВЮЪ§ЕФPhi-4 14BФЃаЭЪ§бЇЭЦРэЗНУцЦРВтНсЙћГЌЙ§GPT 4oЃЌИДдгЭЦРэФмСІДѓЗљдіЧП
PhiДѓгябдФЃаЭЪЧЮЂШэЗЂВМЕФвЛЯЕСааЁЙцФЃДѓгябдФЃаЭЃЌЦфжївЊЕФФПБъЪЧгУНЯаЁЙцФЃВЮЪ§ЕФДѓгябдФЃаЭДяГЩНЯДѓВЮЪ§ЙцФЃЕФДѓгябдФЃаЭЕФФмСІЁЃОЭдкНёЬьЃЌЮЂШэЗЂВМСЫPhi4-14BФЃаЭЃЌВЮЪ§ЙцФЃНі140вкЃЌЕЋЪЧЪ§бЇЭЦРэФмСІДѓЗљдіЧПЃЌдкЖрИіЦРВтЛљзМЩЯЩѕжСНгНќGPT-4oЕФФмСІЁЃ
- Phi-4-14BФЃаЭМђНщ
- Phi-4-14BФЃаЭЕФЦРВтаЇЙћ
- Phi-4-14BЕФЪЕМЪбљР§
- Phi-4-14BФЃаЭЕФПЊдДЧщПі
Phi-4-14BФЃаЭМђНщ
ЮЂШэНЋДѓгябдФЃаЭЗжЮЊСНРрЃЌВЮЪ§НЯаЁЕФЙцФЃБЛГЦЮЊаЁгябдФЃаЭЃЈSmall Language ModelsЃЌ SLMsЃЉЁЃЮЂШэШЯЮЊЃЌЪЙгУИпжЪСПЕФЪ§ОнМЏбЕСЗаЁЙцФЃВЮЪ§гябдФЃаЭЃЌвдДяГЩИќИпЕФЭЦРэФмСІЪЧКмживЊЕФвЛИіЗНЯђЁЃЮЊДЫЃЌЮЂШэЗЂВМСЫPhiЯЕСаЕФДѓгябдФЃаЭЁЃ
дк2023Фъ6дТЗнЃЌЮЂШэПЊдДСЫЕквЛДњPhiФЃаЭЃЌетИіФЃаЭВЮЪ§ЙцФЃНіга13вкЃЌетЪЧвЛИіДПДтЕФБрГЬДѓФЃаЭЃЌЕЋЪЧаЇЙћВЛДэЃЌШ§ИідТКѓЃЌЮЂШэЗЂВМPhi-1.5ФЃаЭЃЌдкPhi-1ДњТыВЙШЋЕФЛљДЁЩЯдіМгСЫФЃаЭЭЦРэФмСІКЭгябдРэНтЕФФмСІЃЌВЮЪ§СПВЛБфЁЃЫцКѓЃЌ2023ФъФъЕзЮЂШэПЊдДСЫPhi-2ФЃаЭЃЌетИіФЃаЭЕФВЮЪ§діГЄЕН27вкЃЌЕЋЪЧMMLUЦРВтНсЙћГЌЙ§СЫLLaMA2 13BЃЌШУДѓМвЪЎЗжОЊЬОЁЃ2024Фъ4дТЗнЃЌЮЂШэЗЂВМСЫPhi-3ЯЕСаSLMЃЌзюИпВЮЪ§ДяЕН140вкЃЌадФмНгНќMixtral-8×22B-MoEетбљИќДѓЙцФЃВЮЪ§ЕФФЃаЭЁЃ2024Фъ8дТЗнЃЌЮЂШэЗЂВМСЫPhi-3.5ЯЕСаФЃаЭЃЌдіМгСЫЖрФЃЬЌКЭЛьКЯзЈМвМмЙЙЃЌФЃаЭФмСІИќЧПЁЃЖј4ИідТКѓЕФНёЬьЃЌЮЂШэЗЂВМСЫШЋаТЕФPhi 4 - 14BФЃаЭЃЌДѓЗљдіЧПСЫЪ§бЇЭЦРэФмСІЁЃ
Phi-4-14BФЃаЭЕФВЮЪ§ЙцФЃ140вкЃЌЩЯЯТЮФГЄЖШЃЈcontext lengthЃЉдкдЄбЕСЗНзЖЮЪЧ4096ЁЃдкдЄбЕСЗжЎКѓЕФжаЦкбЕСЗЃЈmidtrainingЃЉНзЖЮЃЌЩЯЯТЮФГЄЖШБЛРЉеЙЕНСЫ16384ЃЈМД16KЃЉЁЃ
Phi-4 ЪЧвЛПюдкЪ§бЇЭЦРэЗНУцБэЯжГіЩЋЕФЯШНјФЃаЭЃЌГЌдНСЫЭЌРрКЭИќДѓЙцФЃЕФФЃаЭЁЃЦфГЩЙІЙщЙІгкМИИіЙиМќДДаТЃК
КЯГЩЪ§ОнгУгкдЄбЕСЗКЭжаЦкбЕСЗЃЈSynthetic Data for Pretraining and MidtrainingЃЉЃК
- phi-4ЕФбЕСЗЙ§ГЬжаДѓСПЪЙгУСЫКЯГЩЪ§ОнЃЌетаЉЪ§ОнЭЈЙ§ЖржжММЪѕЩњГЩЃЌАќРЈЖрДњРэЬсЪОЃЈmulti-agent promptingЃЉЁЂздЮваоЖЉЙЄзїСїГЬЃЈself-revision workflowsЃЉКЭжИСюЗДзЊЃЈinstruction reversalЃЉЁЃетаЉЗНЗЈФмЙЛЙЙНЈГіФмЙЛМЄЗЂФЃаЭИќЧПЭЦРэКЭЮЪЬтНтОіФмСІЕФЪ§ОнПтЃЌНтОіСЫДЋЭГЮоМрЖНЪ§ОнМЏжаЕФвЛаЉШѕЕуЁЃ
- КЯГЩЪ§Ондкphi-4ЕФдЄбЕСЗКЭжаЦкбЕСЗжаеМОнСЫжїЕМЕиЮЛЃЌВЂЧвОЙ§ОЋаФЩшМЦвдШЗБЃЖрбљадКЭЯрЙиадЃЌвдЬсИпФЃаЭдкЭЦРэКЭЮЪЬтНтОіЗНУцЕФадФмЁЃ
ОЋбЁКЭЙ§ТЫИпжЪСПгаЛњЪ§ОнЃЈCuration and Filtering of High-Quality Organic DataЃЉЃК
- баОПЭХЖгОЋаФЬєбЁКЭЙ§ТЫгаЛњЪ§ОндДЃЈОЭЪЧЪЕМЪздШЛДцдкЕФЪ§ОнЃЉЃЌАќРЈЭјТчФкШнЁЂЪкШЈЪщМЎКЭДњТыПтЃЌвдЬсШЁгУгкКЯГЩЪ§ОнЙмЕРЕФжжзгЃЌетаЉжжзгЙФРјЩюЖШЭЦРэВЂгХЯШПМТЧНЬг§МлжЕЁЃ
- Г§СЫжБНггУгкдЄбЕСЗЕФИпжЪСПЪ§ОнЭтЃЌЛЙЙ§ТЫЭјТчвдбАевИпжЪСПЪ§ОнЃЈвджЊЪЖКЭЭЦРэЮЊвРОнЃЉЃЌжБНггУгкдЄбЕСЗЁЃ
КѓбЕСЗЃЈPost-TrainingЃЉЃК
- phi-4ЕФКѓбЕСЗНзЖЮЭЈЙ§ДДНЈаТЕФSFTЃЈSupervised Fine-TuningЃЉЪ§ОнМЏКЭПЊЗЂЛљгкЙиМќСюХЦЫбЫїЕФDPOЃЈDirect Preference OptimizationЃЉЖдММЪѕЃЌНјвЛВНЬсЩ§СЫФЃаЭадФмЁЃ
- КѓбЕСЗЕФФПБъЪЧНЋдЄбЕСЗЕФгябдФЃаЭзЊБфЮЊгУЛЇПЩвдАВШЋНЛЛЅЕФAIжњЪжЃЌЭЈЙ§ЖдЦывЛТжSFTКЭDPOРДЪЕЯжЃЌЦфжаАќРЈЛљгкЙиМќСюХЦЫбЫїЗНЗЈЩњГЩЕФDPOЖдЁЃ
етШ§ИіЙиМќММЪѕЙВЭЌжЇГХСЫphi-4дкБЃГжВЮЪ§Ъ§СПЯрЖдНЯЩйЕФЭЌЪБЃЌЪЕЯжСЫгыИќДѓФЃаЭЯрцЧУРЕФадФмЃЌгШЦфЪЧдкSTEMЃЈПЦбЇЁЂММЪѕЁЂЙЄГЬКЭЪ§бЇЃЉСьгђЕФЮЪД№ФмСІЩЯЁЃЭЈЙ§етаЉЗНЗЈЃЌphi-4дкЪ§ОнжЪСПЁЂФЃаЭМмЙЙКЭКѓбЕСЗММЪѕЗНУцШЁЕУСЫЯджјНјВНЃЌДгЖјдкИїжжЛљзМВтЪджаБэЯжГіЩЋЁЃ
Phi-4-14BФЃаЭЕФЦРВтаЇЙћ
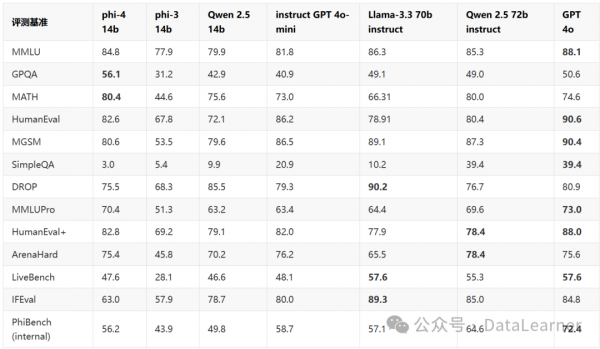
дкЖрИіЦРВтЛљзМжаеЙЯжСЫЯджјгХЪЦЃЌЬиБ№ЪЧдкЪ§бЇЭЦРэЁЂЩњГЩЮЪД№ЁЂвдМАДњТыЩњГЩШЮЮёжаЃЌГЌдНСЫаэЖрЭЌРрКЭИќДѓЙцФЃЕФФЃаЭЁЃЫќЕФгХЪЦдкгкЦфдкЪ§бЇКЭЭЦРэШЮЮёЩЯЕФИпаЇадЃЌЭЌЪБЭЈЙ§ЖдИпжЪСПЪ§ОнЕФОЋаФВпЛЎЃЌЭЦЖЏСЫФЃаЭдкИїРрШЮЮёЩЯЕФзлКЯБэЯжЁЃОЁЙмдкФГаЉШЮЮёЃЈШчSimpleQAЃЉЩЯЕФБэЯжНЯШѕЃЌЕЋзмЬхРДЫЕЃЌPhi-4ЪЧвЛПюИпадФмЁЂОљКтЕФФЃаЭЃЌЪЪгУгкЖржжгІгУГЁОАЃЌгШЦфЪЧдкашвЊОЋШЗЭЦРэКЭЩњГЩФмСІЕФСьгђЁЃ
ЯТЭМеЙЪОСЫPhi-4-14BФЃаЭЕФФмСІЬсЩ§ЧщПіЃК
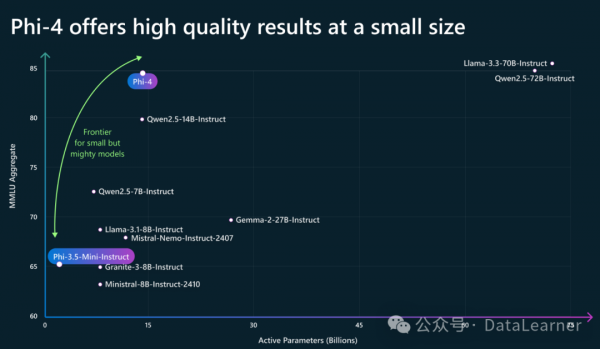
ПЩвдПДЕНЃЌдк150вкзѓгвВЮЪ§ЙцФЃЕФФЃаЭЩЯЃЌPhi-4-14BЕФадФмвЛЦяОјГОЁЃPhi-4-14BЕФЯъЯИЦРВтНсЙћШчЯТБэЫљЪОЃК
ИљОнDataLearnerAIЪеМЏЕФШЋЧђДѓФЃаЭЦРВтНсЙћХХааАёЃЌдкMATHЪ§бЇЦРВтЩЯЃЌPhi-4-14BФЃаЭШЋЧђХХУћЕкЫФЃЌЖјЧАУцШ§ИіФЃаЭЃЌЗжБ№ЪЧЭЦРэДѓФЃаЭDeepSeek-R1-Lite-PreviewЁЂGoogleзюаТЗЂВМЕФGemini 2.0 Flash ExperimentalФЃаЭвдМААЂРяЗЂВМЕФЪ§бЇзЈгаФЃаЭQwen2.5-Math-72BЁЃПЩвдПДЕНЃЌPhi-4-14BдкЪ§бЇЭЦРэЩЯЗЧГЃЧПКЗЃЁ
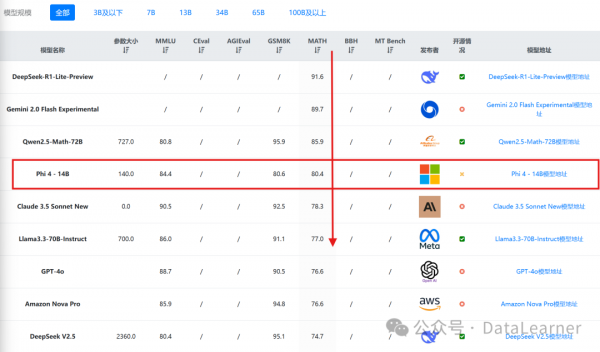
Ъ§ОнРДдДЃКhttps://www.datalearner.com/ai-models/leaderboard/datalearner-llm-leaderboard
ШЛЖјЃЌPhi-4-14BдкМђЕЅЮЪД№КЭФГаЉМЋЖЫЭЦРэШЮЮёжаБэЯжВЛШчдЄЦкЃЌПЩФмЙ§ЖШвРРЕИпжЪСПЕФЪ§ОнЁЃДЫЭтЃЌКѓбЕСЗгХЛЏЕФВпТдвВПЩФмЯожЦЦфдквЛаЉПьЫйБфЛЏЕФгІгУГЁОАжаЕФЪЪгУадЁЃР§ШчЃЌSimpleQAЕУЗжНіЮЊ3.0ЃЌдЖЕЭгкЦфЫћФЃаЭЃЈР§ШчQwen 2.5ЕФ9.9ЃЉЃЌетБэУїPhi-4дкУцЖдНЯЮЊМђЕЅКЭжБНгЕФЮЪД№ШЮЮёЪБПЩФмДцдкВЛзуЁЃЫфШЛФЃаЭдкИДдгШЮЮёжаБэЯжЭЛГіЃЌЕЋдкДІРэМђЕЅЮЪЬтЪБПЩФмУЛгаДяЕНдЄЦкЕФаЇТЪЛђзМШЗадЁЃ
Phi-4-14BФЃаЭЕФПЊдДЧщПі
ФПЧАPhi-4-14BЕФФЃаЭвбОПЩвддкЮЂШэЙйЭјЪЙгУЁЃЯТжмЮЂШэНЋЛсПЊдДPhi-4-14BетИіФЃаЭЃЌЕЋЪЧПЊдДавщЪЧЮЂШэЕФПЊдДбаОПавщЃЌетИіавщЪЧВЛдЪаэЩЬгУЕФЃЌЪЎЗжПЩЯЇЁЃ
ЙигкPhi-4-14BФЃаЭВЮПМDataLearnerAIФЃаЭЕФаХЯЂПЈЃКhttps://www.datalearner.com/ai-models/pretrained-models/phi-4-14b
РДдДЃКDataLearner
КУЮФеТЃЌашвЊФуЕФЙФРј


АТдЫМЖБ№ЕФХЌСІЃКЪзЯЏаХЯЂЙйЮЊ2026ФъAIЕпИВзізМБИ
AIЕпИВдЄМЦНЋдк2026ФъГжајЃЌЭЦЖЏЦѓвЕЪЪгІВЛЖЯбнНјЕФММЪѕВЂРЉДѓЙцФЃЁЃЙњМЪАТЮЏЛсЁЂModernaКЭSportradarЕФСьЕМепдкХІдМТЗЭИЩчЗхЛсЩЯЗжЯэСЫЫћУЧЕФAIВпТдЁЃЬжТлНЙЕуАќРЈздНЈAIгыЙКТђЕкШ§ЗНзЪдДЕФбЁдёЃЌAIдкФкВПСїГЬгХЛЏКЭЭтВПВњЦЗПЊЗЂжаЕФгІгУЃЌвдМАаЁаЭФЃаЭдкШеГЃгІгУжаЕФЧБСІЁЃзЈМвНЈвщЃЌЦѓвЕгІНЋAIНЈЩшШкШыЦѓвЕЮФЛЏЃЌвдДДаТЖјЗЧГЩБОНкдМЮЊЧ§ЖЏСІЁЃ

зжНкЬјЖЏЗЂВМGARЃКШУAIФмЯёШЫРрвЛбљОЋзМРэНтЭМЯёШЮКЮЧјгђЕФЭЛЦЦадММЪѕ
зжНкЬјЖЏЕШЛњЙЙСЊКЯЗЂВМGARММЪѕЃЌШУAIФмЭЌЪБРэНтЭМЯёЕФШЋОжКЭОжВПаХЯЂЃЌЪЕЯжЖдЖрИіЧјгђМфИДдгЙиЯЕЕФзМШЗЗжЮіЁЃИУММЪѕЭЈЙ§RoIЖдЦыЬиеїжиЗХЗНЗЈЃЌдкБЃГжШЋОжЪгвАЕФЭЌЪБЬсШЁОЋШЗЯИНкЃЌдкЖрЯюВтЪджаБэЯжГіЩЋЃЌЩѕжСдкФГаЉжИБъЩЯГЌдНСЫЬхЛ§ИќДѓЕФФЃаЭЃЌЮЊAIЪгОѕРэНтФмСІДјРДживЊЭЛЦЦЁЃ

SpotifyЭЦГіAIВЅЗХСаБэЙІФмШУгУЛЇеЦПиЭЦМіЫуЗЈ
SpotifyдкаТЮїРМВтЪдЭЦГіAIЬсЪОВЅЗХСаБэЙІФмЃЌгУЛЇПЩЭЈЙ§ЮФзжУшЪіашЧѓШУAIИљОнжИСюКЭЬ§ИшРњЪЗЩњГЩИіадЛЏВЅЗХСаБэЁЃИУЙІФмдЪаэгУЛЇЩшжУЖЈЦкЫЂаТЃЌЯрЕБгкДДНЈПЩПижЦЫуЗЈЕФУПжмЗЂЯжВЅЗХСаБэЁЃетЪЧSpotifyИГгшгУЛЇИќЖрПижЦШЈХЌСІЕФвЛВПЗжЃЌДЫЧАЦфAI DJЙІФмвВдіМгСЫгявєЬсЪОбЁЯюЃЌЗДгГСЫИїЦНЬЈШУгУЛЇИќКУПижЦЫуЗЈЭЦМіЕФЧїЪЦЁЃ

Inclusion AIЭЦГіЭђвкВЮЪ§ЫМЮЌФЃаЭRing-1TЃКЪзИіПЊдДЕФГЌДѓЙцФЃЭЦРэв§ЧцШчКЮжиЫмAIЫМПМБпНч
Inclusion AIЭХЖгЭЦГіЪзИіПЊдДЭђвкВЮЪ§ЫМЮЌФЃаЭRing-1TЃЌЭЈЙ§IcePopЁЂC3PO++КЭASystemШ§ЯюКЫаФММЪѕЭЛЦЦЃЌНтОіСЫГЌДѓЙцФЃЧПЛЏбЇЯАбЕСЗЕФЮШЖЈадКЭаЇТЪФбЬтЁЃИУФЃаЭдкAIME-2025ЛёЕУ93.4ЗжЃЌIMO-2025ДяЕНвјХЦЫЎЦНЃЌCodeForcesЛёЕУ2088ЗжЃЌеЙЯжГізПдНЕФЪ§бЇЭЦРэКЭБрГЬФмСІЃЌЮЊAIЭЦРэФмСІЗЂеЙЪїСЂСЫаТЕФРяГЬБЎЁЃ
2024
12/16
16:04
ЗжЯэ
Еудо