OpenAI提供大模型的提示缓存(Prompt Caching):GPT-4o系列模型输入价格下降一半,访问速度提升80%
本文原文来自DataLearnerAI官方博客:
https://www.datalearner.com/blog/1051734484275280
在大模型的应用中,处理复杂请求往往伴随着较高的延迟和成本,尤其是当请求内容存在大量重复部分时。这种“慢请求”的问题,特别是在长提示和高频交互的场景中,显得尤为突出。为了应对这一挑战,OpenAI 最近推出了 提示缓存(Prompt Caching) 功能。这项新技术通过缓存模型处理过的相同前缀部分,避免了重复计算,从而大幅减少了请求的响应时间和相关成本。特别是对于包含静态内容的长提示请求,提示缓存能够显著提高效率,降低运行开销。本文将详细介绍这项功能的工作原理、支持的模型,以及如何通过合理的提示结构优化缓存命中率,帮助开发者提升大模型的使用体验。
什么是大模型提示缓存(Prompt Caching)?
提示缓存(Prompt Caching)机制,用于减少在处理重复内容的长提示时的延迟和计算成本。这里的“提示”指的是你向模型发送的输入内容。在请求过程中,系统并不会每次都重新计算提示的前N个输入tokens,而是缓存先前的计算结果。这样,对于后续具有相同提示前缀的请求,系统就能够重用这些缓存数据,从而加速处理,减少延迟,并节省成本。
简单来说,提示缓存的工作原理如下:
- 缓存前1024个标记:系统会检查提示内容的前1024个标记是否与之前的请求相同,如果相同,就缓存这些标记的计算结果。
- 缓存命中:当新的请求与缓存的提示内容匹配时,我们称之为“缓存命中”。此时,响应中会包含关于缓存标记的详细信息,帮助减少计算时间和成本。
- 降低成本:在 标准部署类型 中,缓存的标记将以折扣价计费;而在 预配置部署类型 中,缓存标记甚至可以获得100%的折扣。
官方给出了一个非常形象的提示缓存原理图:
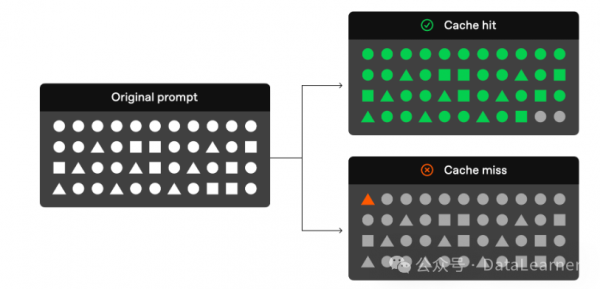
从上图可以看出来,如果你的原始请求中前面的tokens与此前的请求相同,那这部分请求可以不通过模型解决,而直接通过缓存结果读出来即可。
当前,OpenAI官方提供的可缓存的模型如下:
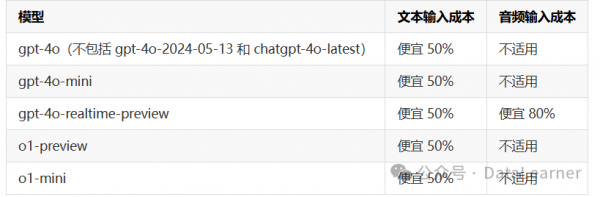
当前支持提示缓存的模型(如 gpt-4o、gpt-4o-mini、gpt-4o-realtime-preview 等)均能有效降低文本输入成本,特别是 50% 的成本折扣,而 gpt-4o-realtime-preview 模型在处理音频输入时甚至能享受 80% 的成本折扣。这些模型的支持不仅提高了模型的响应效率,还为开发者提供了一个低成本、高性能的解决方案,特别适用于那些需要频繁重复请求或包含大量静态内容的场景。
提示缓存的工作方式
根据当前OpenAI官方提供的文档,如果你的请求要使用到缓存,必须满足如下条件:
- 提示的长度必须至少为 1024 个标记。
- 提示的 前 1024 个标记 必须在后续请求中 完全相同。
此外,还需要注意的是,官方说起始1024个tokens是最少可以缓存的长度,但是后面命中的增量式128个tokens,也就是说缓存的长度都是1024、1152、1280、1408这样以1024个tokens为最低,128个tokens递增的方式保存。
当发生“缓存命中”时,API 响应将包含 cached_tokens,表示有多少标记来自缓存。例如,发送给 o1-preview-2024-09-12 模型的请求可能会返回如下响应:
-
{ -
"created":1729227448, -
"model":"o1-preview-2024-09-12", -
"object":"chat.completion", -
"usage":{ -
"completion_tokens":1518, -
"prompt_tokens":1566, -
"total_tokens":3084, -
"completion_tokens_details":{ -
"reasoning_tokens":576 -
}, -
"prompt_tokens_details":{ -
"cached_tokens":1408 -
} -
} -
}
在这个例子中,1408个标记是从缓存中获取的,显著减少了处理时间和成本。
提示缓存命中后的保存时间
OpenAI官方说,模型不会一直保存缓存信息。目前GPT系列模型的提示缓存的相关机制如下:
- 缓存持续时间:缓存会在 5-10分钟的非活动状态后清除。如果缓存的最后一次使用超过一小时未被访问,则会被完全移除。
- 缓存未命中:如果提示的前1024个标记中有一个字符不同,就会导致 缓存未命中,此时
cached_tokens的值将为 0。 - 缓存不可共享:提示缓存不会在不同的订阅之间共享。每个订阅都有自己的缓存。
支持的缓存内容类型
提示缓存的功能根据所使用的模型有所不同。例如,o1 系列模型仅支持文本,不支持系统消息、图像、工具调用或结构化输出,因此其缓存功能主要适用于用户消息部分。而 gpt-4o 和 gpt-4o-mini 模型支持更多内容类型的缓存,包括:
- 消息:完整的消息数组,包括系统消息、用户消息和助手消息。
- 图像:用户消息中包含的图像(无论是链接还是 base64 编码数据),只要
detail参数一致。 - 工具调用:包括消息数组和工具定义的缓存。
- 结构化输出:附加到系统消息的结构化输出模式。
为了增加缓存命中的概率,建议将重复内容放在消息数组的前面。
提示缓存支持的OpenAI的API版本
提示缓存功能首次在 API 版本 2024-10-01-preview 中提供支持。对于 o1 模型系列,API 响应中现已加入了 cached_tokens 参数,用于显示缓存命中的标记数。
启用提示缓存的步骤:
- 最小长度:确保提示的长度至少为 1024 个标记。
- 一致的前缀:确保提示的前1024个标记在不同请求中保持一致。
- API 响应:在缓存命中时,API 响应中会显示
cached_tokens,指出缓存了多少标记。
是否可以禁用提示缓存?
提示缓存在所有支持的模型中 默认启用,并且目前 没有禁用选项。这意味着,如果你使用的是支持的模型,缓存会自动启用,前提是请求符合条件。
为什么提示缓存如此重要?
提示缓存带来了两大主要好处:
- 减少延迟:通过避免重复处理相同内容,缓存显著加快了响应时间。
- 节省成本:缓存减少了需要处理的标记数,从而降低了整体计算成本,尤其适用于重复内容较多的长提示。
对于那些经常需要处理相同数据或提示的应用场景,如对话式 AI 系统、数据提取和重复查询等,提示缓存的优势尤为明显。
OpenAI提示缓存的最佳实践
为了提高缓存命中的概率,OpenAI也给出了一些官方建议:
- 结构化提示:将静态或重复内容放在提示的前面,将动态内容放在提示的后面。
- 监控缓存指标:通过监控缓存命中率、延迟和缓存标记百分比,优化提示和缓存策略。
- 利用长提示和非高峰时段:使用更长的提示并在非高峰时段发起请求,以增加缓存命中的机会,因为在高峰期,缓存会更频繁地被清除。
- 保持一致性:通过定期使用相同前缀的提示请求,减少缓存被清除的可能性。
OpenAI的提示缓存技术常见的问题和答案
- 缓存如何确保数据隐私? 提示缓存不会在不同组织之间共享。只有同一组织中的成员才能访问相同提示的缓存。
- 提示缓存是否会影响输出标记或最终响应?
提示缓存不会影响模型的输出结果。无论是否使用缓存,生成的输出始终是相同的。因为只有提示本身被缓存,实际的响应是每次基于缓存的提示重新计算的。
是否可以手动清除缓存?
目前不支持手动清除缓存。长时间未被使用的提示会自动从缓存中移除。通常,缓存会在 5-10 分钟 的非活动期后清除,但在流量较少的时段,缓存最多可能持续 一小时。
使用提示缓存需要支付额外费用吗?
不需要。缓存是自动启用的,用户不需要额外操作或支付额外费用。
缓存的提示是否会计入 TPM 限制?
是的,缓存不影响速率限制,缓存命中仍会计入请求的总数量。
在 Scale Tier 和批量 API 中可以使用提示缓存折扣吗?
提示缓存折扣不适用于批量 API,但在 Scale Tier 中适用。通过 Scale Tier,溢出的令牌也会受到缓存优惠。
提示缓存是否适用于零数据保留请求?
是的,提示缓存符合现有的零数据保留政策。
总结
Azure OpenAI 的提示缓存功能为处理长提示和重复请求提供了一个非常有价值的优化方案。它通过减少计算延迟和成本,显著提高了模型的效率。
随着更多模型的支持以及提示缓存功能的不断优化,预计 Azure OpenAI 用户将能够享受到更高效、更经济的服务体验。
好文章,需要你的鼓励


Android 2026年5月谷歌系统更新新增功能一览
谷歌每月发布"Google系统更新说明",涵盖Play服务、Play商店及Play系统更新的最新变化,适用于Android手机、平板、Wear OS、Google/Android TV、Auto及PC等平台。本次5月更新涉及账户管理、开发者服务、设备连接、安全与隐私、钱包及实用工具等多个模块,部分功能面向终端用户,部分面向开发者。需注意,更新日志中出现的功能并不代表已全面上线,部分功能可能仍处于实验阶段。

宾夕法尼亚大学:为什么给AI训练的每一层都配上“专属教练“,效果会更好?
宾夕法尼亚大学研究发现,针对神经网络不同类型参数的内在对称性设计专属优化器,比用同一个Adam算法优化所有参数,能稳定提升大语言模型预训练的最终性能。

欧盟据报道计划就搜索业务对谷歌开出创纪录罚款
欧盟委员会计划依据《数字市场法》(DMA)对谷歌开出史上最高罚款,金额或达九位数。欧盟监管机构认为,谷歌在搜索结果中优先展示自家服务(如谷歌购物),对第三方竞争网站构成不公平竞争。此前谷歌提出的整改方案被认为力度不足。此外,欧盟还在对谷歌Play商店及搜索引擎AI功能展开独立调查,审查其是否妨碍市场公平竞争。

AI“考官“打分竟然有偏心?佛罗里达大学揭开多模态大模型在临床评分中的隐藏缺陷
研究发现顶尖AI在医学画钟测试评分中存在系统性"打分保守"问题,总爱把极端分数往中间靠,可能导致严重认知障碍患者被漏检。
2024
12/19
17:04
分享
点赞