
微软发布Phi-4,最强小模型!参数极小、超GPT-4o
微软研究院发布了最强小参数模型——Phi-4。
Phi系列模型自今已经发布了5代,Phi-4也延续了之前的小参数模式只有140亿。
但在GPQA研究生水平、MATH数学基准中,分别达到了56.1和80.4超过了GPT-4o,同时也超过了同类型的开源模型Qwen 2.5 -14B和Llama-3.3-70B。
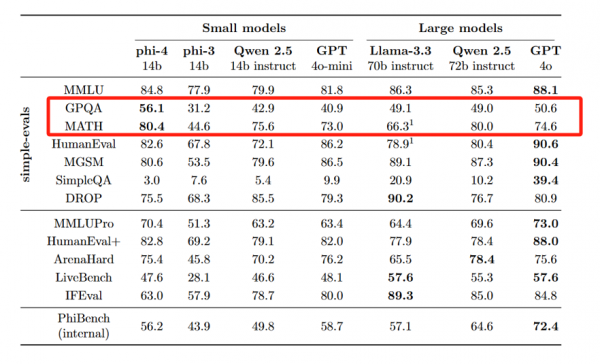
而在美国数学竞赛AMC的测试中,Phi-4达到了惊人的91.8分,再次超过了GeminiPro 1.5、GPT-4o、Claude 3.5 Sonnet、Qwen 2.5等知名开闭源模型,甚至整体性能可以与4050亿参数的Llama-3.1相媲美。
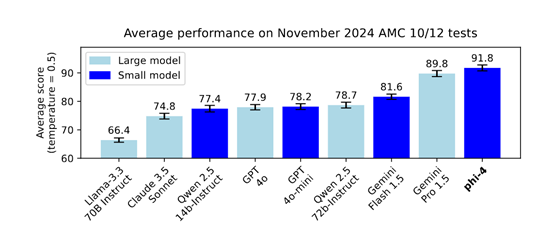
这也就是说,只要使用了高质量数据和创新训练方法,小参数模型同样可以战胜大参数,但在部署、应用和推理方面极大减少了对AI算力和环境的要求。

使用高质量合成数据
Phi-4能以如此小的参数获得巨大性能,使用高质量合成训练数据是关键环节之一。
传统的大模型通常依赖于从网络抓取或公开数据库获取的真实世界文本作为训练数据,这种方法虽然能够提供丰富的信息来源,但也容易受到噪声干扰和偏见影响。
Phi-4则使用了种子策划、多Agent提示、自我修订工作流、重写和增强以及指令反转等多种合成方法,有效解决了传统无监督数据集的缺点。

种子策划是合成数据生成的起点。Phi-4从多个领域提取高质量的数据种子,为合成数据生成打下坚实基础,使得能够创建针对模型训练目标的练习、讨论和推理任务。
策划的种子包括从网页、书籍和代码库中提取的文段和代码片段,这些内容展示了高复杂性、深度推理和教育价值。为了确保质量,采用了两阶段过滤过程:首先是识别具有强教育潜力的页面,然后是将选定的页面分割成段落,对每个段落进行事实和推理内容的评分。
此外,多Agent提示允许不同智能体之间进行交互对话,从而创造出更加多样化且贴近真实应用场景的交流场景;而自我修订工作流则鼓励模型参与到自身的编辑过程中,以此提高输出内容的质量和一致性。
通过改变任务描述的方式,指令反转可以增加模型处理不同类型问题的能力,进一步增强了其灵活性和适应性。
总体上,一共生成了50 种不同类型的合成数据集,涵盖广泛的主题和技能,总计约 400B未加权的高质量token数据。
创新训练方法
为了确保phi-4能在广泛的任务类型上表现出色,研究人员使用了一系列针对性创新训练方法,并根据实际需求调整各类数据的比例。尤其是针对长上下文理解能力的需求,phi-4增加了rope位置编码的基础频率至25万次,并相应地降低了最大学习率,以更好地适应更长的文本序列。
这种做法有效提升了模型对于复杂结构化信息的理解力,使其在面对需要综合分析多个段落甚至整篇文章的问题时也能游刃有余。phi-4还特别注重了不同类型数据之间的平衡,避免某类数据过多导致其他方面性能下降的情况发生。
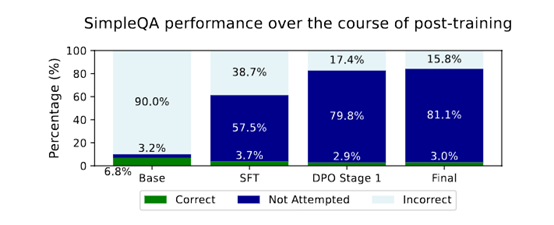
而在 phi-4 的后训练过程中,研究团队采用了两种形式的 DPO 数据对模型进行了强化训练。第一种是基于人工标注的 SFT数据,即由专家精心挑选并标记好的问答对;
第二种则是自动构建的 DPO 对,这种方法通过搜索重要的转折点,将原始对话片段拆分成多个选项,并让模型从中选择最优解。通过结合这两种方式,phi-4 不仅学会了如何产生更符合预期的回答,还能够在不同情境下灵活调整语气和风格,从而提供更加个性化的交互体验。
此外,phi-4还引入了一些创新性的后训练方法,以增强其在特定领域内的表现。例如,在 STEM领域问题解答方面,phi-4 利用了一个名为Math-Shepherd 的工具来进行验证和强化学习。Math-Shepherd 可以自动检查模型生成的答案是否正确,并且在必要时提供额外指导,帮助模型逐步掌握正确的解题思路。
这种方法有效地解决了传统无监督数据集中常见的逻辑不严密等问题,使得 phi-4 在数学竞赛类题目上的准确率达到了惊人的80.4%,远超其他同类产品。
此外,针对编程代码评估任务,Phi-4 也采取了类似的方法,通过对大量开源项目中的代码片段进行分析和总结,提升了其在该领域的执行效率和准确性。
值得一提的是,微软AI副总裁、phi系列模型的灵魂人物之一Sébastien Bubeck已经离开了微软加入了OpenAI。
好文章,需要你的鼓励


明阳电气马来西亚首个海外生产基地投产,输配电设备开始本地制造
今天讲的出海案例是明阳电气,这家输配电设备公司在马来西亚投产首个海外生产基地,并以 250 万林吉特子公司承接本地制造。

当AI搜索员越读越多,反而越读越蒙:UC San Diego等机构揭示“屏蔽旧信息“的隐藏规律
研究揭示AI搜索代理"屏蔽旧观测"策略的效果取决于检索质量与模型能力的匹配程度,存在三种截然不同的效果区间。

数学家发出警告:AI正威胁数学研究的自主性与学术标准
数学界发布《莱顿宣言》,由16位研究人员历时8个月起草,已获国际数学联盟背书。宣言指出,AI正威胁数学研究的核心价值:AI生成的错误证明难以识别、论文引用不规范、版权争议频发、科技公司主导研究议题,以及企业借新闻稿抢占话语权等问题日益严峻。宣言呼吁数学家透明披露AI使用情况,建议监管机构保护作者权利并规范AI产业,同时警告各方不要轻信科技公司对AI能力的夸大宣传。

机器人“听懂“指令却不知道该抓哪个——哈工大等机构联合揭示VLA模型的致命短板
多所高校与研究机构联合构建机器人语义接地测试平台RSB,发现主流VLA模型普遍存在"能抓但抓错"的致命缺陷,语义理解与动作生成之间存在严重断层。
2024
12/16
20:04
分享
点赞

