
海光16核CPU首曝:多核性能如何?

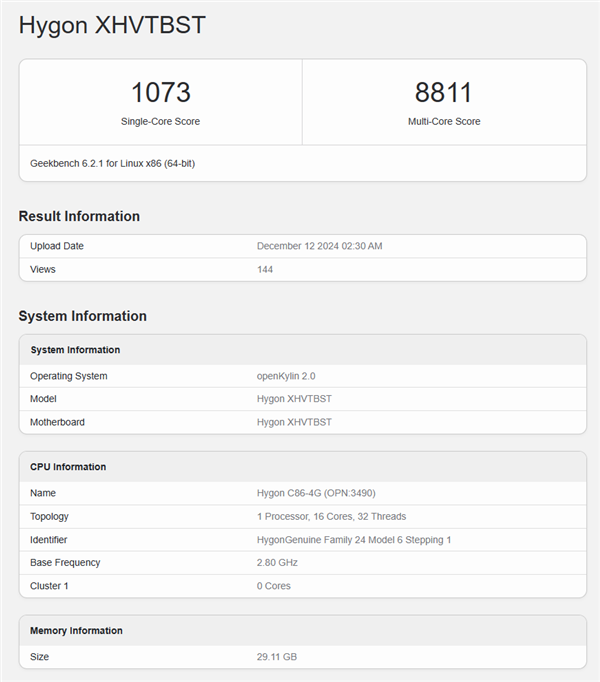
近日,GeekBench 6.2数据库里出现了一颗新的海光处理器,检测编号C86-4G,实际型号C86-3490,与现有8核心的C86-3350同样属于C86-3000系列,显然架构是相通的。
不过,C86-3490升级到了16核心,只是频率偏低,基准只有区区2.8GHz,搭配32GB内存。


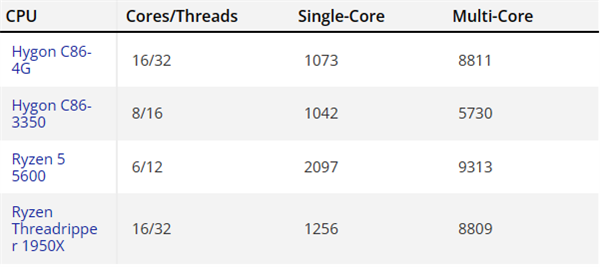
实测单核跑分1073,和8核心的几乎完全相同,证明架构没变。
但是,只有Zen3架构、3.9-4.4GHz频率的锐龙5 5600G的一半,毕竟架构、频率都差异巨大。
多核跑分8811,对比8核心的提升了超过50%,并不算很出色,而且还打不过少了10个核心的锐龙5 5600G。
不过,基本达到了同样初代Zen架构、同样16核心的线程撕裂者1950X的水平。
好文章,需要你的鼓励


Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。

Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber周三发布了一款基于现代Ioniq 5改装的数据采集原型车,搭载14个摄像头、8个固态激光雷达和9个雷达,通过英伟达双驱Thor计算机处理数据。Uber计划今年在全球部署500辆此类车辆,每月可采集200万英里高保真驾驶数据,供Avride、Waymo、WeRide等30余家自动驾驶合作伙伴使用。这是Uber自2020年出售自动驾驶部门以来首次自主组装车辆,也是其AV Labs部门的重要进展。

LMMs-Lab与NTU MMLab联手微软:让AI智能体“一句话自我进化“的秘密
SkillOpt-Lite通过将智能体技能优化形式化为零阶优化问题,提出极简流水线:把执行轨迹存为文本文件,让AI直接用文件系统工具翻日志、找规律、改技能,配合独立验证门控,比复杂的多智能体优化框架跑得更快效果更好,并自然延伸至执行框架自动优化(HarnessOpt),使轻量模型能够超越大模型。
2024
12/19
19:04
分享
点赞

