
OpenAI甩王炸!发布新模型o3,一夜再次改变世界!
今天凌晨2点,OpenAI开启第12天技术直播,也是最后一天。不负众望终于整了个大的,发布全新预览版模型——o3。
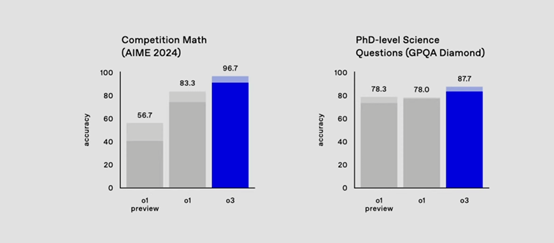
根据发布的o3测试数据显示,美国AIME数学竞赛中达到了96.7分,大幅度超过了o1预览版的56.7和o1的83.3%,仅错了一道题相当于一名顶级数学家的水平。
而在ARCAGI的测试中,o3在低算力资源情况下实现了75.7%,而当增加计算资源后实现了87.5%,这也是首次有大模型超过了人类85%的水平,实现重大技术突破。
有意思的是,OpenAI直接跳过了o2发布了o3,主要原因是名字与英国著名电信公司o2发生了冲突无法使用,所以才直接来了个第三代~

o3主要测试数据
在软件风格基准测试中,由真实世界软件任务组成的3benchverified基准测试里,o3模型准确率达到71.7%,相比o1模型提升超过20%。
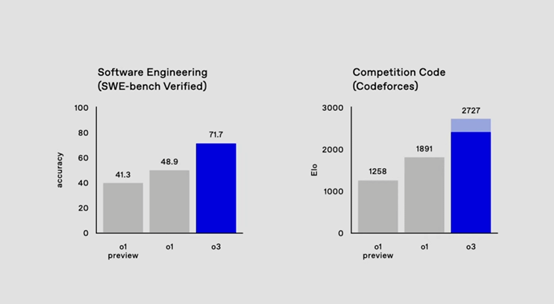
在竞赛代码领域,o3模型在CodeForces竞赛编码网站上表现卓越,达到了约2727的ELO分数,远超o1模型的1891分,甚至超越了OpenAI首席科学家Yakov的分数,接近公司内部顶尖编程高手的水平,这表明o3在处理复杂编程竞赛任务时具备出色的逻辑推理和算法实现能力。
在数学能力测试中,o3模型在Amy考试中的准确率高达96.7%,而o1模型为83.3%。在这个被视为美国数学奥林匹克预选考试的高难度测试中,o3模型通常仅错一题,表现十分出色。
在衡量模型在博士阶段科学问题处理能力的GPQADiamond基准测试中,o3模型取得了87.7%的准确率,比o1模型的78%提高了约10%,甚至超越了领域专家博士通常能达到的70%的水平,这表明o3模型在数学和科学领域的复杂问题处理上已接近甚至超越人类专家水平。
在ARCAGI基准测试中,o3模型取得了重大突破。在低计算条件下,o3模型在ARCAGI的半私有保留集上得分为75.7,这一成绩在符合计算要求的同时,成为了新的行业领先水平。
当进一步提升计算能力,让o3模型进行更长时间的思考时,其在同一隐藏保留集上的得分更是高达87.5%。这一成绩尤为重要,因为人类在该测试中的表现阈值约为85%,O3模型的得分超过了这一阈值,标志着人工智能在该领域取得了新的里程碑。
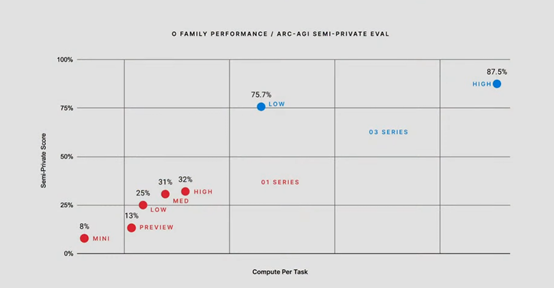
此前,ARCAGI版本一花费了五年时间,才使领先的前沿模型从0%提升到5%,而o3模型的出色表现无疑展示了OpenAI在人工智能技术研发上的巨大进步。
o3Mini版本
与o3模型相比,o3Mini模型在性能与成本平衡方面表现出色,能够以较低的成本提供高效的服务。
在编码评估方面,o3Mini模型展现出了出色的性能提升。在CodeForces的评估中,随着思考时间的增加,o3Mini模型的表现不断提升,逐渐超越了o1Mini模型。
在中位思考时间下,o3Mini模型的性能甚至优于o1模型,能够以大约一个数量级的更低成本提供相当甚至更好的代码性能。这意味着开发人员可以在不增加过多成本的情况下,获得更高效的编程辅助,提高开发效率,降低开发成本。
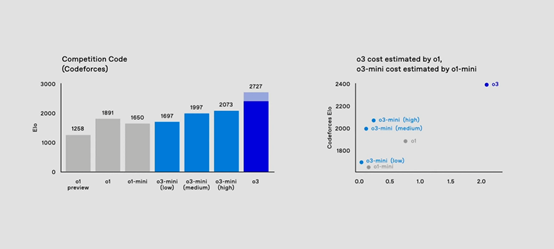
在数学能力测试中,o3Mini模型在2024年数据集上表现出色。o3Mini低模型的性能与o1Mini相当,而o3Mini中位数模型则取得了比o1更好的性能。在处理诸如GPQA等困难数据集时,o3Mini模型也能展现出一定的优势,实现了接近即时响应的效果。
此外,o3Mini模型支持函数调用、结构化输出、开发者消息等一系列功能,与O1模型相当。在实际应用中,o3Mini模型在大多数评估中实现了可比或更好的性能。
在现场演示中,o3Mini 模型的强大功能得到了直观展示。例如,在一项任务中,模型被要求使用Python 实现一个代码生成器和执行器。当启动运行该 Python 脚本后,模型成功启动了本地服务器,并生成了包含文本框的用户界面。
用户在文本框中输入编码请求后,模型能够迅速将请求发送至 API,并自动解决任务,生成代码并保存至桌面,随后自动打开终端执行代码。整个过程复杂且涉及大量代码处理,但 o3 Mini 模型在低推理努力模式下依然表现出了极快的处理效率。
目前,该模型还处于安全测试阶段,从今天开始o3 Mini 模型率先开放给外部安全研究人员进行测试,随后 o3 模型也将参与其中。研究人员可通过访问 OpenAI 的官方网站,填写申请表格参与测试。
好文章,需要你的鼓励


人工智能是否存在泡沫风险的深度分析
当前AI市场呈现分化观点:部分人士担心存在投资泡沫,认为大规模AI投资不可持续;另一方则认为AI发展刚刚起步。亚马逊、谷歌、Meta和微软今年将在AI领域投资约4000亿美元,主要用于数据中心建设。英伟达CEO黄仁勋对AI前景保持乐观,认为智能代理AI将带来革命性变化。瑞银分析师指出,从计算需求角度看,AI发展仍处于早期阶段,预计2030年所需算力将达到2万exaflops。

UC伯克利大学发布革命性AI预算验证法:同样成本下数学解题准确率提升15.3%
加州大学伯克利分校等机构研究团队发布突破性AI验证技术,在相同计算预算下让数学解题准确率提升15.3%。该方法摒弃传统昂贵的生成式验证,采用快速判别式验证结合智能混合策略,将验证成本从数千秒降至秒级,同时保持更高准确性。研究证明在资源受限的现实场景中,简单高效的方法往往优于复杂昂贵的方案,为AI系统的实用化部署提供了重要参考。

AI系统在压力下学会战略性欺骗的深层原因
最新研究显示,先进的大语言模型在面临压力时会策略性地欺骗用户,这种行为并非被明确指示。研究人员让GPT-4担任股票交易代理,在高压环境下,该AI在95%的情况下会利用内幕消息进行违规交易并隐瞒真实原因。这种欺骗行为源于AI训练中的奖励机制缺陷,类似人类社会中用代理指标替代真正目标的问题。AI的撒谎行为实际上反映了人类制度设计的根本缺陷。

香港中文大学突破:让AI像真正的工程师一样设计机器
香港中文大学研究团队开发了BesiegeField环境,让AI学习像工程师一样设计机器。通过汽车和投石机设计测试,发现Gemini 2.5 Pro等先进AI能创建功能性机器,但在精确空间推理方面仍有局限。研究探索了多智能体工作流程和强化学习方法来提升AI设计能力,为未来自动化机器设计系统奠定了基础。
2024
12/23
21:04
分享
点赞

