
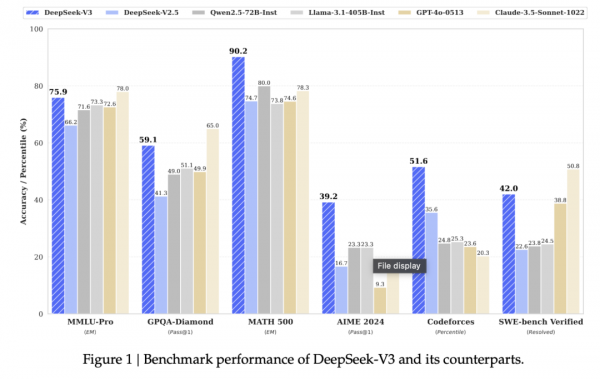
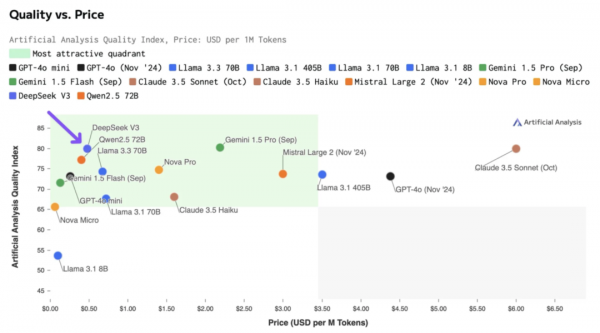
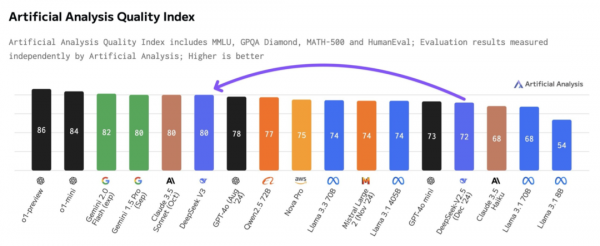
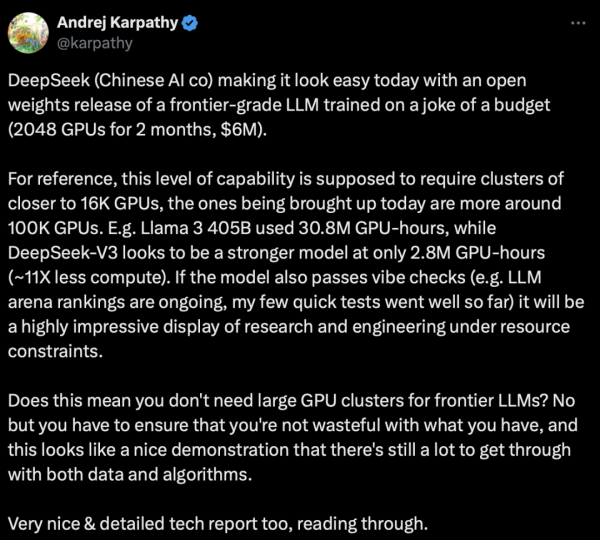
国产开源之光:DeepSeek-V3划重点
DeepSeek-V3 采用了 671B 参数 MoE 架构,配备约 37B 激活单元,训练使用14.8T Token数据。





好文章,需要你的鼓励


AI新加坡联手阿里云推出东南亚大语言模型Sea-Lion v4
新加坡人工智能机构与阿里云发布全新大语言模型Qwen-Sea-Lion-v4,专门针对东南亚语言和文化特色进行优化。该模型结合阿里云Qwen3-32B基础模型和大量东南亚地区数据集,在东南亚语言模型评估榜单中位居开源模型首位。模型支持119种语言,能在32GB内存的消费级笔记本上运行,采用字节对编码技术更好处理非拉丁文字,并具备3.2万词元上下文长度,可执行文档级推理和摘要任务。

中科大联手快手:AI视频评判员学会了“边看边想“,彻底解决视频生成质量难题
中科大联合快手等机构推出VR-Thinker技术,首次实现AI视频评判员的"边看边想"能力。该系统通过主动选择关键画面、智能记忆管理和三阶段训练,在视频质量评估准确率上达到75%-82%,特别擅长处理长视频场景,为AI视频生成的质量控制提供了突破性解决方案。

5个将在2026年改变任何企业的惊人智能体应用案例
AI智能体是下一代业务自动化工具,不仅能对话交流,还能执行复杂任务。与ChatGPT聊天机器人不同,它们可在最少人工干预下规划并完成工作。文章介绍了五个高影响力应用:自动化客户服务解决方案、销售CRM管理、合规自动化、招聘筛选与排程、市场情报报告。这些应用都具有重复性工作流程、依赖结构化数据、遵循可预测规则等特点,能够释放员工宝贵时间用于更有价值的工作。

微软研究院发布BitDistill:让大型语言模型轻松瘦身却不丢性能的魔法
微软研究院发布BitDistill技术,通过三阶段优化将大型语言模型压缩至1.58位精度,在保持性能的同时实现10倍内存节省和2.65倍速度提升。该技术包括模型结构稳定化、持续预训练适应和知识蒸馏传承三个关键步骤,解决了模型量化中的性能衰减和规模化问题,为AI模型在资源受限设备上的高效部署提供了新方案。
2024
12/30
11:04
分享
点赞

