2024年AGI终章:OpenAI宣布o3模型,推理能力再次跃进 (Day 12/12)
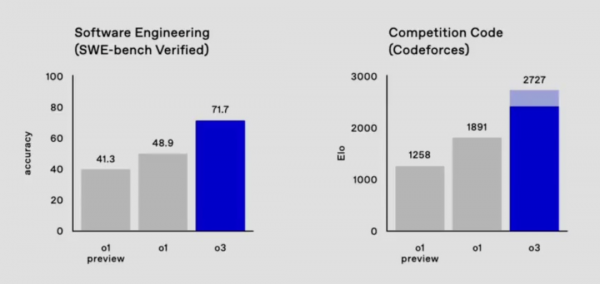
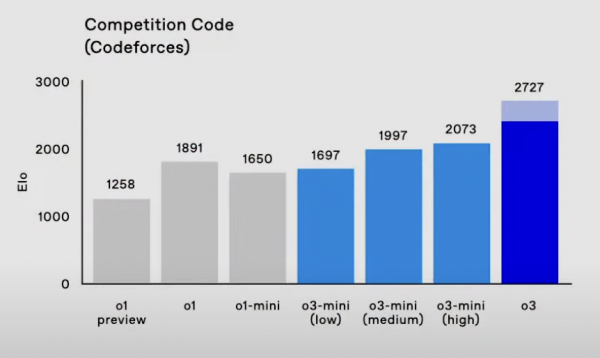
o3在Codeforces上大幅超越此前o1取得的成绩,直逼最高阶人类选手的水平。Mark提到自己的分数也只有2500左右,还承认o3超过了首席科学家Jakub的分数,而目前OpenAI公司内的最高水平只有3000。
年末12连发来到了最后一天。就在发布会前一晚,Sam还在X上玩起了梗:
此前曾经被人们说期待的GPT-5 (或4.5) 最终没有面世。
在Day 12发布会上,Sam Altman和Mark Chen领衔,发布了o系列最新模型:(跳过了o2)o3。
既然是o系列模型,我们简单回顾下发布o1时候的定义:
We are introducing OpenAI o1, a new large language model trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers—it can produce a long internal chain of thought before responding to the user.
可以看到o系列模型的重点词包含了:RL、think、CoT,也就是我们俗称的“推理端大模型”。
o3在Codeforces上大幅超越此前o1取得的成绩,直逼最高阶人类选手的水平。Mark提到自己的分数也只有2500左右,还承认o3超过了首席科学家Jakub的分数,而目前OpenAI公司内的最高水平只有3000。
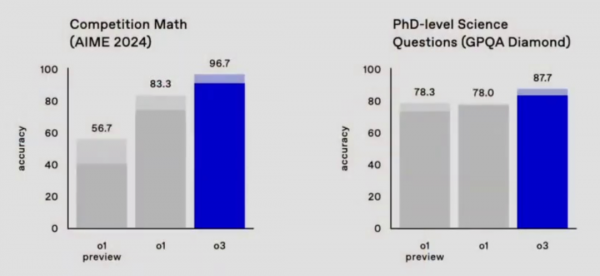
2、数学能力同样亮眼。在数学竞赛方面,o3在AIME上的准确率约为96.7%,而o1的表现为83.3%。在GPQA Diamond这个衡量模型在博士级别的科学问题上的表现方面同样惊艳。
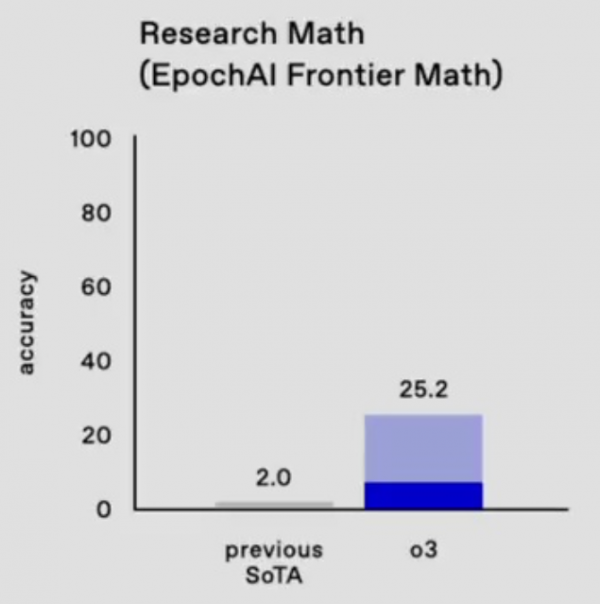
另外,还有一个值得一提的EpochAI的Frontier Math基准测试 - 这是目前公认的最难的数学基准测试,是一个由新颖、未发表以及非常难的问题组成的数据集。这些问题极其困难,即使是专业数学家也需要花费数小时甚至数天才能解决其中一个问题。
所有现有的模型在这个基准测试上的准确率都低于2%(此前SOTA)。o3能够超过25%!
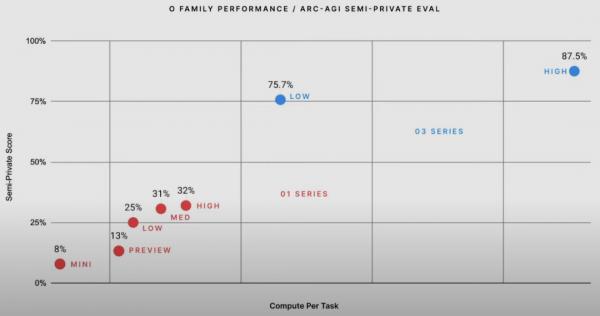
ARC-AGI是由Keras深度学习库的创建者Francois Chollet于2019年推出的基准测试:旨在通过解决新颖任务来评估AI系统的泛化能力和新技能获取能力,而无需事先训练,重点关注核心推理能力,而非特定领域的知识。
o3模型取得了87.5%,更重要的是超过了人类平均线的85%。这标志着o3模型在推理能力的突破,特别是在不依赖记忆模式的情况下解决新问题的能力。
一定程度上,这也标志了通往AGI过程中的一个重要里程碑。
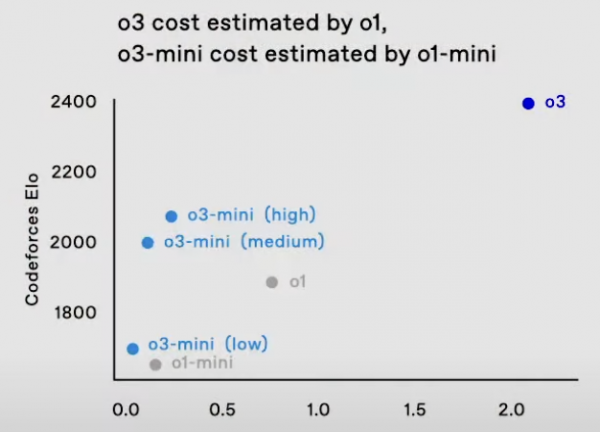
除了o3,Day 12同时发布了o3系列的新成员o3-mini:与o1-mini一样,o3-mini具有高性价比。
o3-mini具有三档的思考级别 - 低/中/高等推理强度,用户可以根据任务调整推理思考时间。
举例来说,在Codeforces测试中,o3-mini的分数会随着思考时间增加而增加。如下可见,在中等思考强度下,o3-mini已经可以超过o1的分数。
而在成本和速度方面,o3-mini取得了较o1-mini更好的性能:
Deliberate Alignment / 深度对齐
随着今天o系列模型的发布,OpenAI还同时发布了一篇paper:
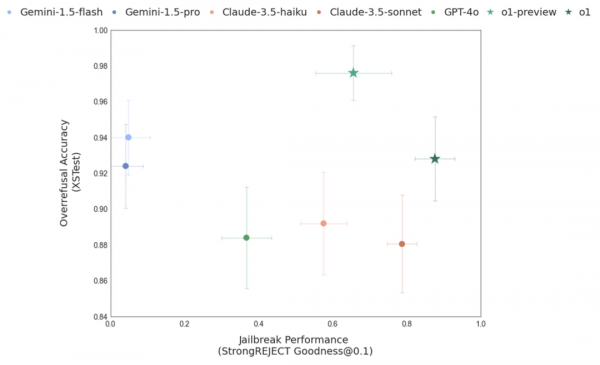
这篇论文是关于Deliberate Alignment(暂时翻译为深度对齐),该方法超越了传统的人类反馈强化学习RLHF,在 AI 决策过程中嵌入了更深层次的自我反思机制。通过培养这种内部深思熟虑的思考模式,AI 模型能够更好地理解其行为的影响,从而表现出更值得信赖和符合伦理的行为。应该说是在AI安全方面的一个重要尝试。
根据下图 - 越狱性能图表所示:采用深度对齐技术的模型(如 o1-preview 和 o1-mini)比早期模型(如 GPT-4o)更能抵御越狱攻击。
从今天的年终压轴发布来看,OpenAI以及整个前沿AI学术及产业界都在经历着重大方向改变:在年末这几个月中,关于GPT-5失败、Scaling Law Slowdown、AGI发展方向上产生了很大争论,Ilya在不久前NeurIPS大会上演讲表达了预训练终结的观点:
OpenAI这边,从传统的GPT系列转向了o系列推理模型,或许正是在预训练对模型提升效果见顶的环境下,希望通过整合推理能力,来实现模型智利水平的下一个突破口。除了OpenAI之外,类似的趋势也在Google的布局中,例如最最近发布的Gemini 2.0 Flash Thinking。
自从o1推理模型发布开始,种种迹象表明,推理能力正在成为业内发展的新的聚焦点。
我们很久之前就聊到过:语言模型的本质是一个“压缩器”,而预训练的训练范式相当于“知识的压缩过程”。如果把预训练时代看作知识的话,那么当下更加聚焦的推理端Scaling Law就可以看作是思考过程,可以类比成“学习并思索”的过程。如果将过去的预训练Scaling Law称为“大力出奇迹”,那么当下的智力推进过程或许应该称为“大力学而思出奇迹”。
2024年AGI路线在摇摇欲坠中,寻找到了新的梯子向上爬。期待下一年的进程吧。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。