
突破算力限制!Meta开源“记忆层”,重塑Transformer架构大模型
今天凌晨3点,全球社交巨头Meta分享了一个创新研究——Memory layers(记忆层)。
目前,Transformer架构的预训练大模型在存储、查询数据时,随着参数的变大对算力的需求呈指数级增长。“记忆层”提出了新的高效查询机制替代了传统的查询方法,通过比较查询键与两个较小集合中的键,可以快速找到最相关的键,而无需遍历模型的整个记忆层。
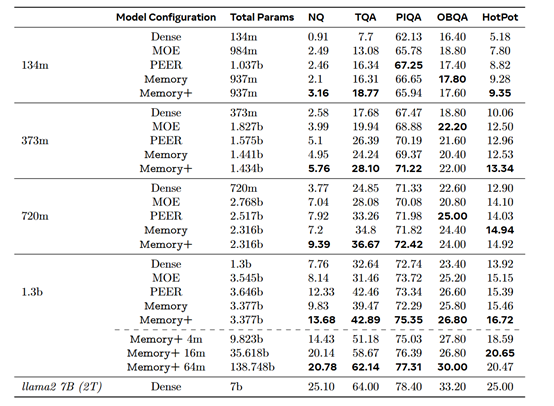
这也就是说,可以在不增加算力的情况下显著增加大模型的参数。例如,研究人员在仅有1.3亿参数的模型中添加了128亿额外的记忆参数,其性能与Meta开源的Llama 2- 70相当,而算力却比它低了10倍左右。
开源地址:https://github.com/facebookresearch/memory

Product - Key Lookup
在传统的键值查找中,每个查询都需要与记忆层中的每个键进行比较,以找到最匹配的值。该方法在键的数量较少时是可行的,但随着记忆层规模的增长,这种暴力搜索的方式变得非常低效,需要消耗巨大算力和时间。
给大家举一个简单的例子,你想在一个巨大的图书馆里找一本书。这个图书馆有成千上万本书,每本书都有一个唯一的编号(相当于记忆层中的“键”)。如果你要找到一本特定的书(相当于查询),传统的方法是逐个检查每一本书的编号来查找你要的那一本。
这种方法在图书馆只有几百本本书时可能还行得通,当图书馆藏书量达到数万时,逐本查找方法就变得极其耗时和低效了。
Product - Key Lookup是“记忆层”的核心算法之一,使用了一种分而治之的策略,将传统的单一键集合分解为两个较小的键集合,通过两个阶段的查找来减少必要的比较次数,从而提高查找效率。
首先,查询键被分割为两个子查询,每个子查询分别与两个半键集合进行比较。由于每个半键集合的大小只有原始键集合的平方根大小,因此这个阶段的计算量大幅减少。在第一阶段,每个半键集合中找到与子查询最相似的k个键,这个过程称为top-k查找。
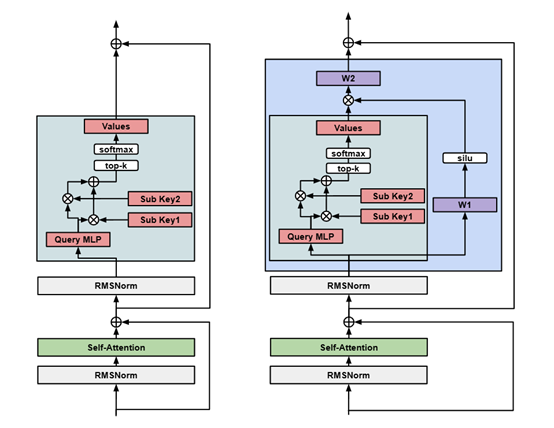
在第二阶段,两个半键集合中找到的top-k键被合并,以确定最终的top-k键。这一步骤涉及到对两个半键集合中找到的键进行综合评分,以确定它们与原始查询键的整体相似度。需要考虑到两个半键集合中的键的组合,以找到最佳的匹配。
除了计算效率之外,Product-Key Lookup模块还优化了内存和带宽的使用。由于每个GPU只需要处理一半的键,因此内存的使用量减少了一半。由于每个GPU只需要返回与自己处理的键相关的值,所以内存带宽的需求也得到了优化。
Product-Key Lookup算法不仅提高了记忆层的查询效率,还为记忆层的应用开辟了新的可能性,使得记忆层可以被应用于更大规模的数据集和更复杂的任务中,包括大规模知识图谱的查询、长文本的语义检索等。
并行记忆层和共享记忆参数
并行记忆层主要是用于对硬件GPU的优化。在传统的Transformer架构模型中,随着模型规模的增加,计算和内存需求也随之增长。特别是在处理大规模数据集时,单一的计算单元很难满足这种需求。并行记忆层通过在多个GPU之间分配任务,有效解决这一难题。
在并行记忆层的设计中,每个计算单元只负责处理一部分数据,这样可以减少单个计算单元的负担,同时提高整体的处理速度。这种设计允许模型在保持单个计算单元负载合理的同时,处理更大规模的记忆层。使得模型可以扩展到数十亿甚至数百亿的参数,而不会受到单个计算单元性能的限制。
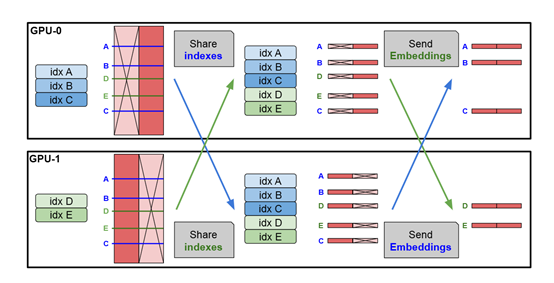
共享记忆参数则是另外一个重要优化方法,允许不同层的记忆层共享同一个参数集合。这种设计的优势在于,它减少了模型的总参数数量,同时提高了参数的利用率。
当一个记忆层接收到输入后,它会先从共享记忆池中查找最相似的记忆单元,然后根据查询结果生成输出。由于所有记忆层都指向同一个记忆池,因此它们可以在不影响彼此的情况下同时进行操作。
为了应对训练期间可能出现的变化,研究人员开发了一套动态调整策略。每当有新的键加入或旧有的键被更新时,系统会自动调整相应的子集,而无需对整个记忆池进行全面改造。这样的设计既简化了维护流程,又提高了系统的灵活性和适应性。
好文章,需要你的鼓励



Meta开发的AI编程助手,真的懂你吗?还是需要你反复“纠正“它才能干活?
Meta团队推出SWE-Together评测框架,将真实用户与AI编程的多轮对话转化为可复现的测试题,首次将"用户需要纠正AI多少次"纳入评分体系。

亚马逊 Mechanical Turk 将停止接受新用户注册
亚马逊宣布,其众包服务Mechanical Turk将于2026年7月30日停止接受新用户注册。现有用户可继续正常使用,AWS也将持续维护安全性,但不再引入新功能。该平台自2005年上线以来,曾是人工标注数据的重要来源,并在AI训练领域发挥过关键作用。然而近年来平台逐渐衰退,2023年研究显示33%至46%的任务已由大语言模型完成,平台价值受到质疑。业界普遍认为该服务已名存实亡。

AI模型的“肌肉记忆“:阿联酋人工智能大学揭示为何安全训练会被无害微调悄悄抹去
阿联酋MBZUAI研究团队发现,AI安全对齐后的"引力回归"现象:良性微调会沿着可预测的几何方向使模型悄悄恢复危险行为,且该方向可被测量和干预。
2025
01/06
14:04
分享
点赞

