
NJU联合腾讯提出VITA-1.5!GPT-4o级别的实时视觉语音交互框架!

论文名:VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
论文链接:https://arxiv.org/pdf/2501.01957
开源代码:https://github.com/VITA-MLLM/VITA

导读
最近在多模态语言模型(MLMs)方面的进展显著,特别是在视觉和文本模态的整合方面取得了重大进步。将视觉信息引入语言模型显著增强了模型在一系列多模态任务中的能力。然而,随着人机交互吸引力的增加,语音模态的作用变得越来越突出,尤其是在多模态对话系统中。在这样的系统中,语音不仅是信息传输的关键媒介,而且极大地提高了交互的自然性和便利性。因此,整合视觉和语音模态以实现高性能的多模态交互已成为一个关键的研究焦点。
简介
本文提出了一种精心设计的分阶段训练方法,逐步训练大型语言模型以理解视觉和语音信息,最终实现流畅的视觉和语音交互。我们的方法不仅保留了强大的视听能力,而且无需单独的自适应语音识别(ASR)和文本到语音(TTS)模块,就能实现高效的语音转语音对话能力,显著加快了多模态端到端的响应速度。通过将我们的方法与图像、视频和语音任务的最新技术进行基准测试对比,我们证明了我们的模型具备强大的视觉和语音能力,能够实现接近实时的视觉和语音交互。
方法与模型
3.1 模型架构
VITA-1.5 的整体架构如图 2 所示。输入端与 VITA-1.0 版本相同,即采用“多模态编码器-适配器-大型语言模型”的配置。它将视觉/音频变换器和多层连接器与大型语言模型结合起来进行联合训练,旨在提升对视觉、语言和音频的统一理解。至于输出端,VITA-1.5 拥有自己的端到端语音模块,而不是像原始 VITA-1.0 版本那样使用外部文本到语音模型。
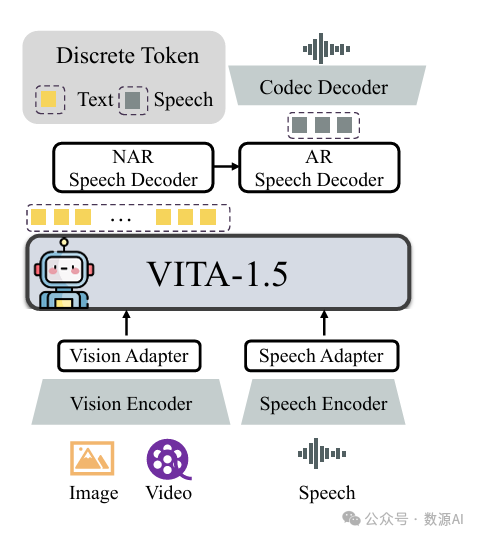
3.1.1 视觉模态
视觉编码器。VITA-1.5 采用 InternViT-300M1 作为视觉编码器,输入图像大小为 448x448 像素,每张图像生成 256 个视觉令牌。对于高分辨率图像,VITA-1.5 采用动态分块策略来捕捉局部细节,提高图像理解的准确性。
视频处理。视频被视为一种特殊类型的多图像输入。如果视频时长短于 4 秒,则均匀采样 4 帧;对于 4 到 16 秒之间的视频,每秒采样一帧;对于超过 16 秒的视频,则均匀采样 16 帧。不对视频帧应用动态拼接,以避免过多的视觉标记干扰处理效率。
视觉适配器。使用两层多层感知机(MLP)将视觉特征映射为适合后续由大型语言模型理解的视觉标记。
3.1.2 音频模态
语音编码器。与[56]类似,我们的音频编码模块由多个下采样卷积层(下采样 4 倍)和 24 个 Transformer 块(隐藏大小为 1024)组成。下采样层有助于降低音频特征的帧率,提高大型语言模型的处理速度。音频编码器大约有 3.5 亿个参数,输出帧率为 12.5 赫兹。使用梅尔滤波器组特征作为音频编码器的输入,窗口大小为 25 毫秒,移位为 10 毫秒[56]。
语音适配器。它由多个带有 2 倍下采样的卷积层组成。
语音解码器。使用 TiCodec[45] 作为我们的编解码器模型,定制一个大小为 1024 的单个码本。这种单码本设计简化了推理阶段的解码过程。编解码器模型负责将连续的语音信号编码成离散语音标记,频率为 40 赫兹,并且同时能够将其解码回采样率为 24000 赫兹的语音信号。
当前的 LLM 只能输出文本令牌,而语音生成能力要求 LLM 能够输出语音令牌。为此,我们在文本令牌后按照[56]添加了两个语音解码器:1)非自回归(NAR)语音解码器,它全局处理文本令牌并模拟语义特征,目的是生成语音令牌的初始分布;2)自回归(AR)语音解码器基于 NAR 解码器生成的语音信息逐步生成更高质量的语音令牌。然后使用编解码器模型的语音解码器将语音令牌序列解码成连续的语音信号流(波形)。我们对 NAR 和 AR 语音解码器都采用了 4 层 LLaMA 解码器,隐藏大小为 896,参数大小约为 120M。
3.2 训练数据
如表 1 所示,多模态指令调优的训练数据涵盖广泛的类别,例如中文和英文的标题数据和问答数据。在不同的训练阶段,有选择性地对整体数据集的子集进行采样,以服务于不同的目标。具体来说,数据集分类如下:
-
图像字幕数据:使用 ShareGPT4V[9]、ALLaVA-Caption[6]、SharedGPT4o-Image2 以及合成数据等数据集来训练模型,使其能够为图像生成描述性语言。
-
图像问答数据:使用 LLaVA-150K3、LLaVA-Mixture-sample[31]、LVIS-Instruct[55]、ScienceQA[38]、ChatQA[35] 等数据集。从 LLaVA-OV[26] 中抽样的子集,如通用图像问答和数学推理数据集,被用来训练模型以回答基于图像的问题和执行视觉推理任务。
-
光学字符识别(OCR)和数据图表数据:该类别支持模型理解 OCR 和数据图表内容,使用诸如 Anyword-3M[54]、ICDAR2019-LSVT4、UReader[58]、SynDOG5、ICDAR2019-LSVT-QA6 等数据集,以及从 LLaVA-OV 抽样的相应数据。
-
视频数据:像 ShareGemini[47] 这样的数据集和合成数据被用来训练模型处理视频输入并执行诸如字幕生成和视频问答之类的任务。
-
纯文本数据:这一类别增强了模型理解和生成语言的能力,促进基于文本的问答任务。
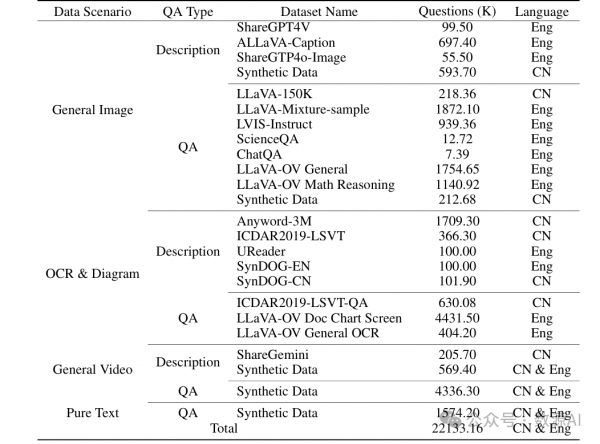
除了表 1 中列出的图像和视频数据外,还纳入了 110,000 小时的内部语音转录配对自动语音识别(ASR)数据,涵盖中文和英文,用以训练音频编码器并将音频编码器与大型语言模型对齐。此外,使用由 TTS 系统生成的 3,000 小时文本语音配对数据来训练语音解码器。
3.3 三阶段训练策略
为了确保 VITA-1.5 在涉及视觉、语言和音频的任务中表现良好,我们必须面对一个关键挑战,即不同模态之间的训练冲突。例如,添加语音数据可能会对视觉数据的理解产生负面影响,因为语音的特征与视觉特征显著不同,在学习过程中会造成干扰。为了应对这一挑战,我们设计了一个三阶段的训练策略,如图 3 所示。核心思想是逐步将不同的模态引入模型中,使其在增强新模态能力的同时保持现有模态的能力。
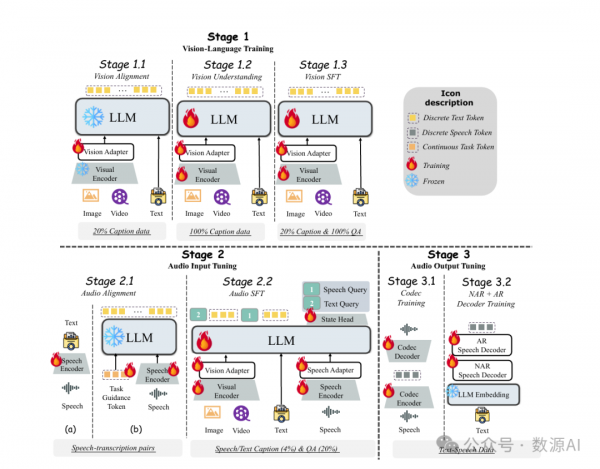
3.3.1 第一阶段:视觉-语言训练
阶段 1.1 视觉对齐:在本阶段,我们的目标是弥合视觉与语言之间的差距。前者的特征是从预训练的视觉编码器 InternViT-300M 中提取的,而后者通过大型语言模型(LLM)引入。我们使用表 1 中 20% 的描述性字幕数据进行训练,在此过程中,只有视觉适配器是可训练的,而其他模块则被冻结。这种方法允许 LLM 最初对齐视觉模态。
阶段 1.2 视觉理解:在这个阶段,我们的目标是教会大型语言模型转录图像内容。为此,我们使用表 1 中的所有描述性字幕数据。在此过程中,视觉模块的编码器和适配器以及大型语言模型都是可训练的。重点是让模型通过学习关于图像的描述性文本来建立视觉与语言之间的强联系,使其能够通过生成自然语言描述来理解图像内容。
阶段 1.3 视觉 SFT:继阶段 1.2 之后,模型已获得对图像和视频的基本理解。然而,指令遵循能力仍然有限,难以应对视觉问答任务。为了实现这一点,我们使用表 1 中的所有问答数据,同时保留 20% 的描述性字幕数据以增加数据集的多样性和任务的复杂性。
在训练过程中,视觉模块的编码器和适配器以及大型语言模型都是可训练的。此阶段的关键目标是使模型不仅能够理解视觉内容,而且能够根据指令回答问题。
3.3.2 第二阶段:音频输入调整
阶段 2.1 音频对齐:在完成第一阶段训练后,模型已在图像和视频理解方面打下了坚实的基础。在这个阶段,我们的目标是在第一阶段的基础上减少音频与语言之间的差异,使大型语言模型能够理解音频输入。训练数据包括 11000 小时的语音转录对。我们采用两步法:(a)语音编码器训练:我们采用通用的语音识别系统使用的训练框架,使用连接时序分类(CTC)损失函数[18]来训练语音编码器。其目的是让编码器从语音输入预测转录文本。此步骤确保音频编码器可以提取语音特征并将其映射到文本表示空间。(b)语音适配器训练:在训练完语音编码器后,我们将其整合到大型语言模型中,使用音频适配器将音频特征引入模型的输入层。此阶段的训练目标是使大型语言模型能够输出语音数据的转录文本。
此外,在步骤(b)中,我们引入特殊的可训练输入标记来指导语音理解过程。这些标记提供额外的上下文信息,指导用于问答任务的大型语言模型执行自动语音识别(ASR)任务。
阶段 2.2 音频 SFT:本阶段的焦点是引入带有语音问题和文本答案的问答功能。为实现这一目标,我们从表 1 中采样 4% 的字幕数据和 20% 的问答数据。在数据处理方面,大约一半的基于文本的问题会被随机替换成它们对应的语音版本,这些语音版本是使用 TTS 系统生成的。
在这个阶段,视觉编码器和适配器、音频编码器和适配器以及大型语言模型(LLM)都是可训练的,目的是提高模型对多模态输入的适应性。此外,我们在 LLM 的输出端增加了一个分类头。这个头用于区分输入是来自语音还是文本。因此,模型可以更准确地解释语音输入,并高效灵活地处理不同的模态。
3.3.3 第三阶段:音频输出调整
在前两个训练阶段,VITA-1.5 模型已经有效地开发了其多模态理解能力。然而,一个关键的能力,即语音输出,仍然缺失,这对于其作为交互式助理的角色至关重要。为了在不影响模型基本能力的前提下引入语音输出功能,我们借鉴了策略[56],使用 3000 小时的文语对数据,并采用两步训练方法(见图 3)。
3.1 编解码器训练:此步骤的目标是使用语音数据训练一个单一代码本的编解码器模型。该编解码器的编码器能够将语音映射到离散标记,而解码器则可以将离散标记映射回语音流。在 VITA-1.5 的推理阶段,仅使用解码器。
3.2 NAR+AR 解码器训练:此阶段的训练使用文语配对数据,其中文本输入到分词器和 LLM 的嵌入层以获取其嵌入向量,而语音输入到编解码器的编码器以获取其语音标记。文本嵌入向量被发送到 NAR 语音解码器以获取全局语义特征,然后将这些特征发送到 AR 语音解码器,后者预测相应的语音标记。注意,在此阶段 LLM 是冻结的,因此不会影响多模态性能。
实验与结果
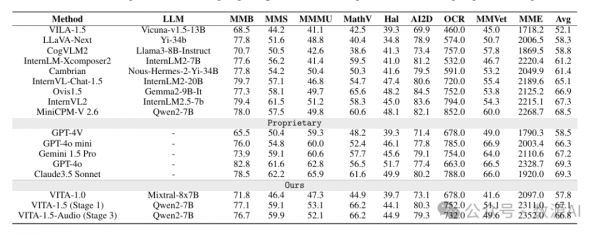
4.1 视觉-语言评估
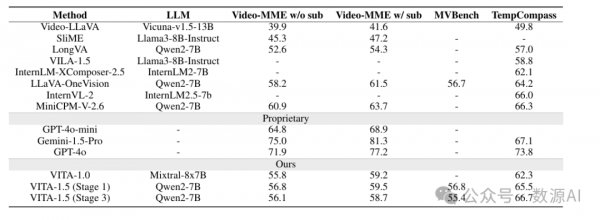
VITA-1.5 在多个图像理解基准测试中表现出色,与领先的开源模型和先进的闭源模型相比具有竞争力。具体来说,VITA-1.5 在 MMBench、MMStar、MMMU、MathVista、HallusionBench、AI2D、OCRBench 和 MMVet 等基准测试中均取得了良好的成绩。这表明 VITA-1.5 在图像-语言任务中具有强大的能力。
4.2 视频理解评估
尽管 VITA-1.5 在视频理解基准测试中仍落后于 GPT-4o 和 Gemini-1.5-Pro 等模型,但它与许多开源模型的表现相当。这表明 VITA-1.5 在视频理解方面仍有改进的空间,但其在视觉-语言能力上的保留令人印象深刻。
4.3 语音评估
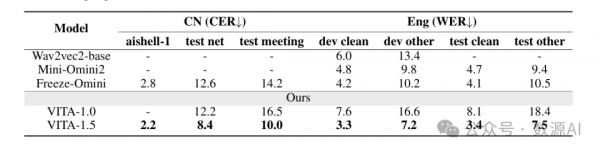
VITA-1.5 在普通话和英语自动语音识别(ASR)任务中表现出色,超过了专门的语音模型。在 Mandarin Evaluation Sets 和 English Evaluation Sets 上,VITA-1.5 的字符错误率(CER)和词错误率(WER)均优于其他基线模型。这证明了 VITA-1.5 成功地整合了先进的语音能力,支持多模态交互。
总结
在本文中,我们介绍了VITA-1.5,这是一个设计用于通过精心制定的三阶段训练策略整合视觉和语音的多模态大型语言模型(LLM)。通过缓解模态间的固有冲突,VITA-1.5 在视觉和语音理解方面都具备强大的能力,能够在不依赖独立的ASR或TTS模块的情况下实现高效的语音转语音交互。广泛的评估表明,VITA-1.5 在多模态基准测试中具有竞争力。我们希望VITA-1.5能够继承VITA-1.0的旗帜,继续推动实时多模态交互领域开源模型的进步。
好文章,需要你的鼓励


维科精密泰国基地启动小批量生产,3.10亿元加码汽车电子精密部件
今天讲的出海案例是维科精密,这家汽车电子与功率半导体精密部件厂商正在泰国建设总投资3.10亿元的生产基地。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

pgEdge推出ColdFront,加入OLTP与OLAP融合赛道以支持AI应用
随着AI智能体对实时数据访问需求激增,企业维护独立事务与分析系统的成本和复杂性日益凸显。Databricks、Snowflake、EDB等厂商纷纷推出融合架构。分布式PostgreSQL提供商pgEdge近日发布ColdFront测试版,采用冷热数据分层架构,自动将旧数据迁移至Apache Iceberg对象存储,同时保持PostgreSQL作为唯一应用接口。分析师指出,DuckDB正成为此类架构的事实标准嵌入式分析引擎,但由此产生的集中风险值得CIO关注。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2025
01/09
11:04
分享
点赞

