
NVIDIA GPUs H100 vs A100,该如何选?
—01 —
多维度解析 A100 vs H100:性能与演进之路
根据 NVIDIA 官方及其独立机构的基准测试和效率测试,H100 的计算速度是 A100 的两倍。即意味着模型训练和推理所需的时间缩短了一半,从而节省了大量的生产时间,加速了研发和部署周期。
虽然 H100 的成本约为 A100 的两倍,但如果 H100 能够以一半的时间完成任务,那么通过云模式的总支出可能相差无几。这是因为 H100 更高的价格与其更快的处理速度相抵消,单位时间内的计算成本可能更具优势。
NVIDIA 于 2020 年发布的 A100 是首款基于 Ampere 架构的 GPU,标志着 AI 计算领域的一个重要里程碑。在 H100 发布之前,A100 凭借其与 AI 任务的极佳兼容性,成为了模型开发者的首选平台。A100 在多个关键技术领域取得了显著突破,特别是在 Tensor Cores 性能提升、CUDA 核心数量与并行计算能力、更大内存与高带宽支持以及多实例 GPU(MIG)技术等多方面。更多内容可参考如下文章:
凭借这些创新,A100 一度被业界视为 AI 模型训练的标杆,是深度学习、图像识别、自然语言处理等任务中训练复杂神经网络的理想选择。特别是在推理相关的任务上,A100 同样表现出了极佳的效率和可靠性。
然而,直到 2022 年,NVIDIA 发布的 H100 GPU 才彻底改变了这一格局。作为基于 Hopper 架构的新一代 AI 专用芯片,H100 在性能和应用场景方面进行了全面升级,迅速成为众多 AI 开发者的首选。H100 相较于 A100,带来了以下显著的提升:
1、更高效的计算能力:H100 在多个领域的计算速度上超越了 A100,尤其是在处理大规模 AI 模型(如 GPT 类大语言模型)时,展现出了惊人的性能。
2、Transformer Engine 的优化:H100 配备了专为深度学习模型优化的 Transformer Engine,极大提升了训练速度,尤其是在需要处理大量并行计算和数据交换的任务中,表现尤为突出。
因此,尽管 A100 在发布初期被认为是训练 AI 模型的首选工具,H100 的推出让人们意识到,AI 专用 GPU 的技术水平还有更大的发展空间,推动了行业的技术革新。
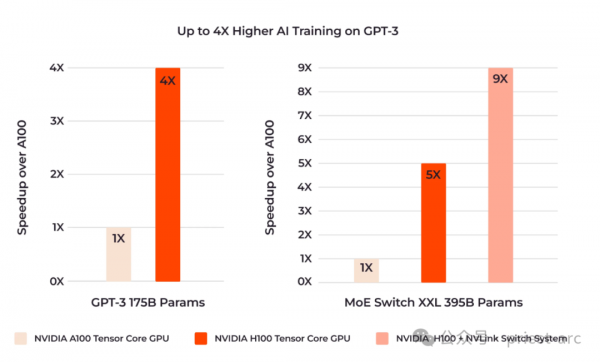
与 A100 相比,H100 提供了显著的性能改进:
1、FP8 任务的性能提升了六倍,能够达到 4 PetaFLOPS 的峰值性能。
2、内存容量增加了 50%,采用 HBM3 高带宽内存,速度高达 3 Tbps,通过外部连接甚至接近 5 Tbps,极大地提升了数据吞吐能力。
3、借助其全新的 Transformer Engine,可以将模型 Transformer 的训练速度提高多达六倍,显著加速了自然语言处理等任务的训练效率。
从哪些方面选择 A100 还是 H100 ?
在实际的业务应用场景中,选择合适的 GPU 进行任务处理和工作负载优化,通常并非简单直观的过程。为了做出最优决策,企业需要综合考虑多个因素,确保在性能与成本之间达到最佳平衡。以下是选购 GPU 时,应重点关注的几个关键因素:
1、成本效益分析
通常而言,GPU 的成本效益不仅仅体现在初期采购或租赁费用上,更应综合考虑其对整体业务运营的长远影响。以 A100 与 H100 为例,虽然 H100 在单次租赁成本上通常高于 A100,大约为 A100 的两倍,但如果 H100 能在相同工作负载下显著缩短计算时间,其带来的效益可能足以弥补这一价格差异。以下是评估成本效益时需要考虑的几个方面:
- 计算效率:
H100 在许多 AI 训练任务中能够显著加快计算速度,特别是在处理复杂模型(如大语言模型)时,H100 的性能提升通常可达到 2-3 倍。因此,虽然 H100 的初始租赁成本较高,但其较短的运行时间可节省大量的计算资源和电力消耗,最终可能带来成本上的优势。
- 任务运行时间
在高性能任务中,GPU 的运行效率对整体成本的影响巨大。H100 能够减少计算时间,尤其在大规模并行计算和 AI 模型训练时,这种时间的节省直接转化为成本的降低。
- 总体拥有成本(TCO)
在选择 GPU 时,除了考虑租赁成本外,还需要综合评估设备的维护、能源消耗以及升级周期等因素。通过对比 H100 与 A100 在多个维度上的表现,企业可以更准确地评估其长期投入的回报。
2、 许可成本和软件兼容性
另一个需要重点考虑的因素是与 GPU 配套使用的软件许可成本。许多企业在选择 GPU 时,往往忽视了与之绑定的软件许可证费用,而这一成本有时可能大大高于硬件本身的费用。
- GPU 型号与软件兼容性
部分专业软件(如深度学习框架、AI 训练工具、数据处理平台等)会根据 GPU 型号设定许可条款。这意味着,一些软件可能针对特定 GPU 型号(如 A100)提供优惠的许可费用,而对于较新或较高端的 GPU 型号(如 H100),其许可费用可能相对较高。
- 许可差异对成本的影响
在一些业务场景中,尤其是那些已经在使用 A100 并依赖特定软件的企业,软件的许可费用可能成为影响选择的关键因素。即使 H100 提供了更强的计算性能和更快的运行速度,但如果相应的软件许可费用大幅上升,综合计算后的总成本反而可能高于继续使用 A100。
- 许可条款灵活性
某些软件许可可能允许跨多个 GPU 型号使用,而有些则严格绑定于特定型号或架构。因此,在为企业选择 GPU 时,需要确保所选 GPU 与现有软件的兼容性,并尽量避免因硬件升级带来额外的许可成本。
3、 其他关键因素
除了成本效益和许可成本外,企业在选择适合的 GPU 时,还需考虑以下其他因素:
- 工作负载类型
不同 GPU 型号在不同类型的工作负载下表现差异显著。比如,H100 在 AI 模型训练和推理方面的优势较为明显,而 A100 在综合性能和多功能任务中依然具有较高的性价比。
- 灵活性与可扩展性
随着企业需求的变化,GPU 的灵活性和可扩展性变得尤为重要。选择能够适应未来扩展需求的 GPU,可以帮助企业更好地应对未来技术发展和工作负载变化。
- 技术支持与生态系统
选择 GPU 时,技术支持和生态系统的完整性也是重要考量因素。NVIDIA 在 AI 和数据中心领域提供了强大的技术支持和丰富的软件工具,企业应考虑这些附加值,以确保 GPU 的最大效能。
—03 —
为什么建议你选择 H100 ?
众所周知,H100 采用了革新性的芯片设计和多项新特性,使其与其前代产品 A100 存在较大差异,尤其是性能与安全方面,具体:
1、增强隐私性:机密计算
H100 的一项显著新增功能便是引入了机密计算(Confidential Computing,CC)。虽然静态数据加密和传输中数据加密是常见的安全措施,但 CC 将这种保护扩展到了使用中的数据。
这项功能对于处理敏感信息的行业(例如医疗保健和金融)尤其具有吸引力,在这些行业中,维护隐私和合规性至关重要。机密计算通过在硬件层面创建一个可信执行环境(TEE),确保即使在云环境中,数据在处理过程中也能得到保护,免受恶意软件或未经授权的访问。
2、优化性能:张量内存加速器
张量内存加速器(Tensor Memory Accelerator,TMA)是 H100 架构的一项突破性创新。它将内存管理任务从 GPU 线程中卸载,从而显著提升了性能。与简单地增加核心数量不同,TMA 代表着一次根本性的架构转变,通过专用硬件加速内存访问,减少了 CPU 和 GPU 之间的通信瓶颈,从而提高了整体计算效率。
此外,随着对训练数据需求的增长,TMA 在不增加计算线程负担的情况下无缝处理大型数据集的能力变得越来越有价值。此外,随着训练软件不断发展以充分利用此功能,H100 可能会成为大规模AI模型训练的首选,提供增强的未来适用性。这意味着企业在未来部署更大规模、更复杂的AI模型时,H100 仍然能够提供强大的支持。
Reference :
[1] https://exittechnologies.com/blog/tech-news/nvidia-h100-vs-a100/
[2] https://docs.nvidia.com/
好文章,需要你的鼓励


米拉·穆拉提重返公众视野,谨慎发声
穆拉蒂时隔18个月首次接受重大媒体采访,介绍其创立的Thinking Machines Lab正在开发的"交互模型"。该模型能以200毫秒间隔处理音频、文本和视频流,捕捉人类交流中的中断、修正和停顿。她还谈及OpenAI"政变周"经历,强调行业决策权过于集中的担忧,并回应了公司近期研究人员离职问题,表示这是初创实验室的正常波动。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
本期《Quick Charge》播客涵盖多个热点话题:特斯拉疑似试图删除FSD欺诈相关证据以规避巨额赔付;卡特彼勒持续推进建筑领域电气化布局;住宅太阳能30%税收抵免即将到期。此外,嘉宾Tom Pacheco就高压系统与电池技术培训展开探讨,强调电动车技术人才培养的紧迫性。节目同时提醒有意安装太阳能的用户尽快行动,可通过EnergySage平台比较多家安装商报价。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2025
01/20
11:04
分享
点赞

