
夸克健康大模型通过副主任医师考试,12门学科超合格线
5月27日,夸克健康大模型在12门国家副主任医师职称考试中成绩超过合格线,成为国内首个成功跨越这一门槛的大模型。这意味大模型在严肃医疗场景中迈出了从“知识记忆”向“临床推理”跃迁的关键一步。
此前,国内大模型多停留在临床执业医师资格考试阶段,只能拿到初级职称。夸克则实现了从初级到副高级职称的两级跳。夸克健康大模型以通义千问为基础,通过海量的高质量数据构建和多阶段后训练策略实现了此次突破。
全新的大模型能力已经可以直接通过夸克搜索调用。用户在使用中会发现,对于严肃医疗问题夸克会通过先分析后搜索,动态检索书籍、指南、药品说明书、医典论文等。这种高搜商的策略显著的提升了复杂病例的准确率。
此次副主任医师职称考试评测覆盖了12个常用学科,包括:全科医学、普通内科学、普通外科学、妇产科学、小儿内科学、肿瘤内科学、口腔医学、耳鼻咽喉科学、眼科学、皮肤与性病学、精神病学、麻醉学。在上述学科领域,夸克健康大模型均超过合格线,并在全科医学、肿瘤内科学、皮肤与性病学、精神病学4个学科达到主任医师及格线。
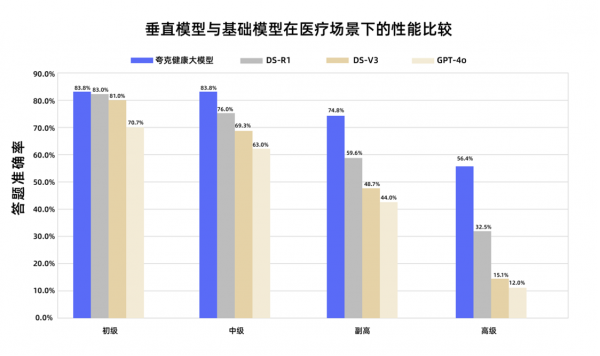
在初级与中级职称考试中,更小尺寸的夸克健康大模型相比满血版基础模型最高领先7分和10分左右。进入难度显著提高、强调临床综合运用的副高职称考试时,夸克最高领先幅度扩大至30分,在长链推理、诊疗路径规划上有显著提升。这项研究验证了垂直模型在性能提升上具备巨大潜力。
对题型维度的深入剖析显示,多选题与病例分析题是所有模型误判率最高的两类。个别通用基础模型在多选题上的正确率均不足60%,而夸克借助“医疗长思考”机制达到71%。在病例分析题中,夸克通过检索增强与分步推理组合策略,将正确率提升至53%。
夸克健康算法工程师徐健表示,“机器通过考试并不意味着可以替代医生,但它展示了在辅助诊疗决策、循证检索与患者沟通方面的巨大潜力。我们将不断强化模型能力,帮助医生和患者提升诊疗效率,为用户在居家场景下提供更多健康管理能力”。
好文章,需要你的鼓励


AI投资有望在2026年获得真正回报的原因解析
尽管全球企业AI投资在2024年达到2523亿美元,但MIT研究显示95%的企业仍未从生成式AI投资中获得回报。专家预测2026年将成为转折点,企业将从试点阶段转向实际部署。关键在于CEO精准识别高影响领域,推进AI代理技术应用,并加强员工AI能力培训。Forrester预测30%大型企业将实施强制AI培训,而Gartner预计到2028年15%日常工作决策将由AI自主完成。

北大学者革新软件诊断方式:让代码问题的“病因“无处遁形
这项由北京大学等机构联合完成的研究,开发了名为GraphLocator的智能软件问题诊断系统,通过构建代码依赖图和因果问题图,能够像医生诊断疾病一样精确定位软件问题的根源。在三个大型数据集的测试中,该系统比现有方法平均提高了19.49%的召回率和11.89%的精确率,特别在处理复杂的跨模块问题时表现优异,为软件维护效率的提升开辟了新路径。

2026年软件定价大洗牌:IT领导者必须知道的关键变化
2026年软件行业将迎来定价模式的根本性变革,从传统按席位收费转向基于结果的付费模式。AI正在重塑整个软件经济学,企业IT预算的12-15%已投入AI领域。这一转变要求建立明确的成功衡量指标,如Zendesk以"自动化解决方案"为标准。未来将出现更精简的工程团队,80%的工程师需要为AI驱动的角色提升技能,同时需要重新设计软件开发和部署流程以适应AI优先的工作流程。

德国达姆施塔特工业大学团队首次揭秘:专家混合模型AI的“安全开关“竟然如此脆弱
这项由德国达姆施塔特工业大学领导的国际研究团队首次发现,当前最先进的专家混合模型AI系统存在严重安全漏洞。通过开发GateBreaker攻击框架,研究人员证明仅需关闭约3%的特定神经元,就能让AI的攻击成功率从7.4%暴增至64.9%。该研究揭示了专家混合模型安全机制过度集中的根本缺陷,为AI安全领域敲响了警钟。
2025
05/27
11:12
分享
点赞

稚晖君发布全球最小全身力控人形机器人,上纬启元开启个人机器人时代
2026年软件定价大洗牌:IT领导者必须知道的关键变化
Linux 在 2026 年将势不可挡,但一个开源传奇可能难以为继
CES 2026趋势展望:全球最大科技展五大热门话题预测
人工智能时代为何编程技能比以往更重要
AI颠覆云优先战略:混合计算成为唯一出路
谷歌发布JAX-Privacy 1.0:大规模差分隐私机器学习工具库
谷歌量子AI发布新型优化算法DQI:量子计算优化领域的重大突破
缓解电动汽车里程焦虑:简单AI模型如何预测充电桩可用性
Titans + MIRAS:让AI拥有长期记忆能力
Gemini为STOC 2026大会理论计算机科学家提供自动化反馈
夸克AI眼镜持续升级:首次OTA,支持89种语言翻译
