
Meta研究人员做出AI新尝试:机器人无需地图或训练实现自主导航

Meta Platforms公司人工智能部门日前表示,他们正在教AI模型如何在少量训练数据支持下学会在物理世界中行走,目前已经取得了快速进展。
这项研究能够显著缩短AI模型获得视觉导航能力的时间。以前,实现这类目标要需要利用大量数据集配合重复“强化学习”才能实现。
Meta AI研究人员表示,这项关于AI视觉导航的探索将给虚拟世界带来重大影响。而项目的基本思路并不复杂:帮助AI像人类那样,单纯通过观察和探索实现在物理空间导航。
Meta AI部门解释道,“比如,如果要让AR眼镜指引我们找到钥匙,就必须想办法帮助AI理解陌生的、不断变化的环境布局。毕竟这是非常细化的小需求,不可能永远依赖于极占算力资源的高精度预置地图。人类不需要了解咖啡桌的确切位置或长度就能不产生任何碰撞、轻松绕着桌角走动。”
为此,Meta决定将精力集中在“具身AI”身上,即通过3D模拟中的交互机制训练AI系统。在这一领域,Meta表示已经建立起一套值得期待的“点目标导航模型”,无需任何地图或GPS传感器即可在新环境中导航。
该模型使用一种名为视觉测量的技术,允许AI根据视觉输入跟踪自身当前位置。Meta表示,这项数据增强技术能够快速训练出有效的神经模型,且无需人工数据注释。Meta还提到,他们已经在自家Habitat 2.0具身AI训练平台(利用Realistic PointNav基准任务运行虚拟空间模拟)上完成了测试,成功率达到94%。
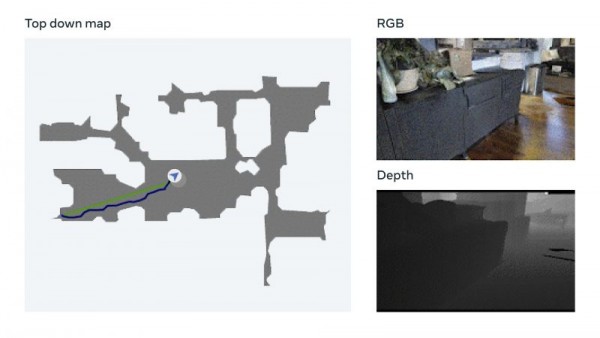
Meta方面解释道,“虽然我们的方法还没有完全解决数据集中的所有场景,但这项研究已经初步证明,现实环境的导航能力不一定需要显式映射来实现。”
为了在不依赖地图的情况下进一步完善AI导航训练,Meta建立了一套名为Habitat-Web的训练数据集,其中包含10万多种由人类演示的不同对象-目标导航方法。通过运行在网络浏览器上的Habitat模拟器就能顺利接入Amazon.com的Mechanical Turk服务,用户能够以远程方式安全操作虚拟机器人。Meta表示,由此产生的数据将作为训练素材,帮助AI代理获得“最先进的结果”。扫视房间了解整体空间特点、检查角落是否有障碍物等,都是值得AI向人类学习的高效对象搜索行为。
此外,Meta AI团队还开发出所谓“即插即用”模块化方法,可以通过一套独特的“零样本体验学习框架”帮助机器人在多种语义导航任务和目标模式中实现泛化。通过这种方式,AI代理在缺少资源密集型地图和训练的前提下仍可获得基本导航技能,无需额外调整即可在3D环境中执行不同任务。
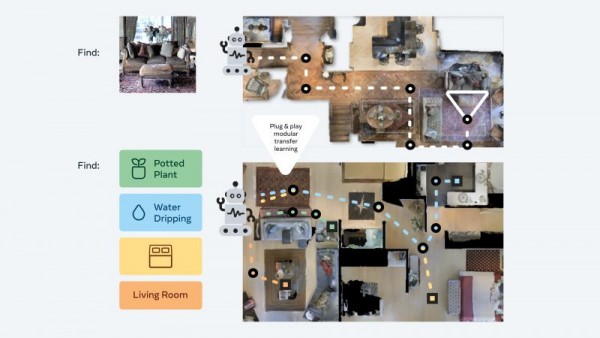
Meta公司解释道,这些代理在训练中会不断搜索图像目标。它们会收到一张在环境中随机位置拍摄的照片,然后通过自主导航尝试找到拍摄点位。Meta研究人员们表示,“我们的方法将训练数据削减至1/12.5,成功率则比最新的迁移学习技术还高出14%。”
Constellation Research公司分析师Holger Mueller在采访中表示,Meta的这项最新进展有望在其元宇宙发展计划中发挥关键作用。他认为,如果未来虚拟世界能够成为常态,那AI必须有能力理解这个新空间,而且理解的成本还不能太高。
Mueller补充道,“AI理解物理世界的能力需要由基于软件的方法获得扩展。Meta目前走的就是这条路,而且在具身AI方面取得了进步,开发出无需训练即可自主理解周边环境的软件。我很期待看到这方面成果在实践层面的早期应用。”
这些现实用例可能已经离我们不远了。Meta公司表示,下一步计划就是把这些成果从导航推进到移动操作,开发出能够执行特定任务的AI代理(比如识别出钱包并将其交还给主人)。
好文章,需要你的鼓励


AI推动KubeCon NA 2025平台工程复兴浪潮
在2025年KubeCon/CloudNativeCon北美大会上,云原生开发社区正努力超越AI炒作,理性应对人工智能带来的风险与机遇。随着开发者和运营人员广泛使用AI工具构建AI驱动的应用功能,平台工程迎来复兴。CNCF推出Kubernetes AI认证合规程序,为AI工作负载在Kubernetes上的部署设定开放标准。会议展示了网络基础设施层优化、AI辅助开发安全性提升以及AI SRE改善可观测性工作流等创新成果。

意大利ISTI研究院推出Patch-ioner:一个神奇的零样本图像描述框架,让电脑像人一样描述任何图像区域
意大利ISTI研究院推出Patch-ioner零样本图像描述框架,突破传统局限实现任意区域精确描述。系统将图像拆分为小块,通过智能组合生成从单块到整图的统一描述,无需区域标注数据。创新引入轨迹描述任务,用户可用鼠标画线获得对应区域描述。在四大评测任务中全面超越现有方法,为人机交互开辟新模式。

DeepL CEO:专业翻译服务如何在ChatGPT时代保持竞争优势
DeepL作为欧洲AI领域的代表企业,正将业务拓展至翻译之外,推出面向企业的AI代理DeepL Agent。CEO库蒂洛夫斯基认为,虽然在日常翻译场景面临更多竞争,但在关键业务级别的企业翻译需求中,DeepL凭借高精度、质量控制和合规性仍具优势。他对欧盟AI法案表示担忧,认为过度监管可能阻碍创新,使欧洲在全球AI竞争中落后。

MIT团队重磅发现:不配对的多模态数据也能让AI变得更聪明
MIT研究团队发现,AI系统无需严格配对的多模态数据也能显著提升性能。他们开发的UML框架通过参数共享让AI从图像、文本、音频等不同类型数据中学习,即使这些数据间没有直接对应关系。实验显示这种方法在图像分类、音频识别等任务上都超越了单模态系统,并能自发发展出跨模态理解能力,为未来AI应用开辟了新路径。
2022
06/17
17:41
分享
点赞

DeepL CEO:专业翻译服务如何在ChatGPT时代保持竞争优势
提示工程迎来协作提示新技术,让AI成为你的合作伙伴
益博睿的悄然转型:从信用评级到云端AI
特斯拉首次发布更诚实的FSD碰撞数据
GPU巨头正在吞噬超级计算领域,传统存储难以满足需求
MinIO推出EB级ExaPOD存储方案保持AI GPU高效运行
Quantum推出ActiveScale部分对象恢复功能显著提升磁带检索速度
英国国民储蓄投资银行数字化转型预算超支13亿英镑
卡塔尔航空部署SD-WAN网络提升运营效率
诺基亚升级数据中心网络设备应对AI时代挑战
“春雨赋智 共筑未来” AMD高校春雨计划在京启动,携手生态链以AI赋能教育新生态
人工智能落地“最后一公里”,戴尔工作站助力AI应用提速
