
单卡支持大模型 首个高稀疏率AI计算卡S100在浪潮内测中表现优异
2022年7月5日,墨芯人工智能首次发布SparseOne® S100在浪潮服务器中的测试数据, S100是全球首个高稀疏率AI计算卡,运行多个AI主流模型,性能表现为国际大厂主流AI推理卡的6倍。更重要的是,它不仅性能优秀,能效比、功耗和精度同样能给业界带来惊喜,并具有良好的通用性。
墨芯人工智能是稀疏化计算的全球引领者,以稀疏化算法为核心,打造云端和终端AI计算加速方案,可广泛应用于数据中心、互联网、运营商、生命科学等场景,推动稀疏化计算生态建设。浪潮是墨芯人工智能的战略投资者和生态合作伙伴。
S100单卡力挑T5-8B
可支持千亿级别大模型
该报告在以下测试环境中进行,测试结果仅对被测系统当时的状态有效。
测试环境
|
项目 |
明细 |
|
服务器型号 |
浪潮NF5468M6 |
|
操作系统 |
Ubntu18.04 |
|
内核版本 |
5.4.173-0504173-generic |
|
CPU/内存 |
Intel 4316 20C 150W 2.3GHz*2 |
|
内存 |
32G DDR4 RECC 3200 服务器内存*16 |
|
加速器 |
Moffett S100计算卡x1 700 MHz |
|
编译环境 |
Moffett模型编译器 |
|
运行环境 |
Runtime(ModelTester) |
报告中的实测数据显示,与国际大厂主流AI推理卡对比,S100运行多个AI主流模型如T5、BERT和ResNet-50,性能为后者6倍。
值得注意的是,这是墨芯首次披露S100运行能够实现单卡推理大模型,突破单卡难以满足高算力需求的瓶颈,有效解决业界对大模型,普遍采取多机多卡分布式的方式,完成推理所带来的时间长、功耗高、成本高等问题。
近年来新兴的NLP模型——T5,曾被称为“全新NLP SOTA预训练模型”,以其高参数量,让许多计算卡“望而却步”。但在本次测试中,S100在单机单卡环境下就能运行T5-8B模型,算力高达141.8 SPS。

除了高算力的优势,相较于当前国际大厂主流推理卡单卡只能支持百亿参数级别的模型,墨芯S100可以支持千亿参数级别的模型。
S100不仅运行大模型性能测试表现优秀,运行其他经典AI模型,如自然语言处理领军模型BERT、图像分类识别模型ResNet-50的性能数据也很亮眼,为国际大厂主流AI推理卡的6倍以上。
S100运行BERT模型,SST-2数据集,在单机单卡环境下,不影响精度的前提下,性能达12176 SPS。

S100运行ResNet-50模型,ImageNet数据集,在单机单卡环境下,不影响精度的前提下,性能达28260 FPS。
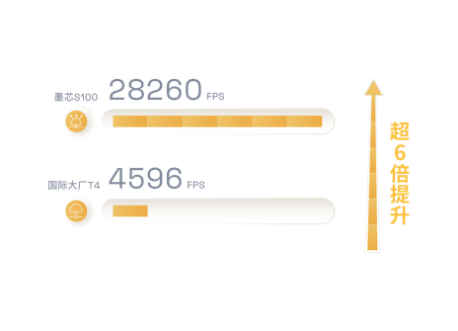
在主频800 MHz的测试环境中,S100运行ResNet-50模型时算力达33197 FPS。浪潮内测主频为700 MHz。
所有测试均是在实际环境中,意味着S100计算卡能够直接投入实际场景的使用,“实战能力”超群,拥有极高的应用价值。这意味着,S100不仅能够提供高性能,还能同时满足高能效比、低功耗和高精度,为企业大幅降低部署成本和运维成本。
稀疏化计算:不止于快
S100超高性能的秘密武器是稀疏化计算。简单来说,稀疏化的原理是指,在AI矩阵运算中,将无效元素剔除,极大加快计算速度,降低计算成本。它在需要海量数据处理的AI加速计算中优势尤为突出,能在提供高性能的同时,为企业提供高能效比、高精度和低功耗,为企业降本增效。
2021年8月,谷歌人工智能主管Jeff Dean在一次TED演讲中表示,稀疏化是下一代AI架构中最重要的趋势之一。他认为当前模型密集且效率低下,而谷歌的研发方向会把模型变得稀疏而高效。
如果说谷歌现在是稀疏化算法的推动者、稀疏化架构的倡导者,那么墨芯已是稀疏化产业实践者。早在2018年,墨芯即致力于稀疏计算的4产业化进程,采用软硬协同的设计创新方法,将稀疏化算法升级到计算层面,实现高性能和高能效。
现在,根据潜在客户的反馈,稀疏化计算成为极富有竞争力的AI计算解决方案,因为它既能够突破算力极限,又具有良好的通用灵活性,企业能够能以极低的迁移成本,一键式地将稀疏计算功能添加到现有的计算设施中。
因此,墨芯的稀疏化计算解决方案具有广阔的生态前景。墨芯人工智能创始人兼CEO王维表示,墨芯将构建涵盖软件、硬件、应用的AI计算平台,与研究人员、开发者、软件开发商等合作伙伴一起,为各行各业用户提供高性能AI计算服务,共同构筑场景丰富、生机勃勃的稀疏化生态。
来源:至顶网人工智能频道
好文章,需要你的鼓励


腾讯开源混元MT翻译模型系列
腾讯今日开源混元MT系列语言模型,专门针对翻译任务进行优化。该系列包含四个模型,其中两个旗舰模型均拥有70亿参数。腾讯使用四个不同数据集进行初始训练,并采用强化学习进行优化。在WMT25基准测试中,混元MT在31个语言对中的30个表现优于谷歌翻译,某些情况下得分高出65%,同时也超越了GPT-4.1和Claude 4 Sonnet等模型。

如何让AI像电影配乐师一样创作完整的长篇音频故事——腾讯ARC实验室团队AudioStory突破性进展
腾讯ARC实验室推出AudioStory系统,首次实现AI根据复杂指令创作完整长篇音频故事。该系统结合大语言模型的叙事推理能力与音频生成技术,通过交错式推理生成、解耦桥接机制和渐进式训练,能够将复杂指令分解为连续音频场景并保持整体连贯性。在AudioStory-10K基准测试中表现优异,为AI音频创作开辟新方向。

Unity Stoakes谈科技、科学与设计的融合变革全球健康
今年是Frontiers Health十周年。在pharmaphorum播客的Frontiers Health限定系列中,网络编辑Nicole Raleigh采访了Startup Health总裁兼联合创始人Unity Stoakes。Stoakes在科技、科学和设计交汇领域深耕30多年,致力于变革全球健康。他认为,Frontiers Health通过精心选择的空间促进有意义的网络建设,利用网络效应推进创新力量,让企业家共同构建并带来改变,从而有益地影响全球人类福祉。

Meta与特拉维夫大学联手打造VideoJAM:让AI生成的视频动起来不再是奢望
Meta与特拉维夫大学联合研发的VideoJAM技术,通过让AI同时学习外观和运动信息,显著解决了当前视频生成模型中动作不连贯、违反物理定律的核心问题。该技术仅需添加两个线性层就能大幅提升运动质量,在多项测试中超越包括Sora在内的商业模型,为AI视频生成的实用化应用奠定了重要基础。
2022
07/08
17:35
分享
点赞

百度学术:行业首个一站式AI学术平台,6.9亿文献资源加持
腾讯开源混元MT翻译模型系列
Unity Stoakes谈科技、科学与设计的融合变革全球健康
微软结束OpenAI独家合作,Office将引入Anthropic模型
亚马逊推出Zoox无人出租车服务,在拉斯维加斯提供免费乘车体验
OpenAI与Oracle签署3000亿美元云计算合作协议
Akamai联合IDC研究:生成式AI驱动边缘演进,亚太80% CIO将依赖边缘服务支持AI工作负载
Gartner发布2025中国网络安全技术成熟度曲线
Lucidity将成本控制焦点转向Kubernetes存储
Spotify因万名用户出售数据构建AI工具而愤怒
Anthropic服务大规模宕机,开发者调侃重回"原始编程时代"
AI说谎的原因:它只是在迎合你想听的答案
