
依托数据、平台、知识增强等优势 夸克大模型大幅降低问答幻觉率
“大模型时代,夸克有巨大机会创造出革新性搜索产品。”11月22日,夸克大模型公布了其面向搜索、生产力工具和资产管理助手的大模型技术布局。数据显示,夸克千亿级参数大模型登顶C-Eval和CMMLU两大权威榜单,夸克百亿级参数大模型同样在法律、医疗、问答等领域的性能评测中夺冠。
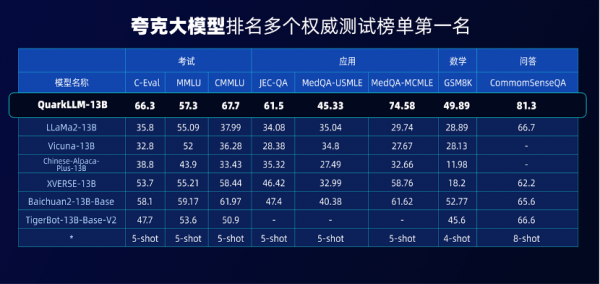
凭借在搜索业务和智能技术上的长期积累,夸克大模型利用数据、平台、知识增强等优势,可以大幅提升知识正确性。在医疗健康领域,夸克大模型已经可以将问答内容的幻觉率降低至5%,处在行业领先水平。
夸克推进搜索革新,自研大模型打造技术新底座
在互联网高速发展的30余年中,搜索曾经高效地满足了用户主动获取信息的需求。但是随着移动互联网内容生产和供给模式的转变,传统搜索逐步变得封闭化、孤岛化。基于大模型的AIGC技术将会给搜索产品带来全新变化,推进搜索革新已经成为行业共识。
夸克技术负责人蒋冠军表示,夸克大模型是面向搜索、生产力工具和资产管理助手的应用型大模型。在搜索应用中,将通过图文多模理解、专业知识生成、交互方式创新进一步拓宽应用场景,提升用户体验。

夸克技术负责人蒋冠军
夸克大模型的优势源自于智能技术实力与搜索业务基础,蒋冠军认为,夸克大模型有四大优势:第一、最全面的通用知识数据和行业知识数据,以及知识理解和评估体系;第二、得益于搜索技术体系的积累,拥有千亿级参数平台的模型训练能力;第三、拥有长期智能化产品经验的智能技术产运团队。第四、拥有全行业的知识增强技术体系及能力。
面向未来,要解决大模型的应用问题,关键要解决知识正确性问题。据悉,基于强大的搜索产品和智能技术积累,夸克大模型在知识增强上的优势可以大幅提升知识正确性。同时,在医疗健康领域,夸克已经可以将问答内容的幻觉率降低至5%,处在行业领先水平。夸克大模型也将是持续推动夸克App产品体验创新和迈向新一代搜索的技术底座。
夸克大模型性能评测夺冠 四大能力提升用户效率
日前,阿里巴巴智能信息事业群发布全栈自研、千亿级参数的夸克大模型,将应用于通用搜索、医疗健康、教育学习、职场办公等众多场景。夸克大模型的整体水平超越GPT-3.5,在多语言翻译、写代码、安全合规、内容创作等方面处在国内行业头部水平。
针对AIGC技术与搜索产品在大模型领域的协同发展,清华大学新闻学院教授、博士生导师沈阳认为,依托搜索平台,夸克大模型拥有高质量的各类数据,在中文语境下,模型能力处在行业领先水平。在教育、医疗等垂直领域中,夸克在对话、解题上的能力取得了新的突破,是国产自研大模型的优秀代表之一。同时,在安全性能上,夸克经历了搜索场景下的长时间考验,累积了非常丰富的经验和能力。
数据显示,夸克大模型接连登顶C-Eval和CMMLU两大权威评测榜单,多项性能优于GPT-4。在国内大模型赛道火热的当下,夸克大模型具备较好的语义理解、知识掌握与应用、逻辑推理能力,整体水平达到行业一流水平。
另外,在最新的百亿参数测试集中,夸克同样在法律、医疗、问答等多个领域中排名第一,夸克大模型在不同参数量级的对比中均表现优秀。
在大模型技术落地层面,夸克大模型的能力体现在四个方面,可以帮助用户提升工作、学习效率。知识能力,拥有广泛的知识覆盖、信息搜集和多语言支持等,支持外接专业知识增强,提升跨领域的知识和语言理解能力;对话能力,具备较强的上下文理解、语境推理、关键信息保持和记忆能力,更好地适应不断变化的语境,理解用户的意图和需求,确保对话回复准确、合理、连贯;创作能力,能够根据主题或关键词,生成连贯、有逻辑、有深度的文本内容,支持续写、润色、仿写、批改等多种不同写作需求;安全能力,具备较好的世界观、价值观,对于明显的虚假信息,均能做到准确识别、正确回答或者给出合理指引。
以用户需求出发,打造工作、学习、生活的AI助手,夸克App持续迭代进化。据悉,夸克大模型将全面升级夸克在搜、用、存上的智能化体验,帮助用户进一步提升效率。同时,基于多年累积的搜索优势,夸克将借助AI驱动推进搜索革新,加速迈向下一代搜索。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2023
11/23
12:16
分享
点赞

Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
Apple芯片现不可修复漏洞,或成iPhone越狱突破口
DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮
QwQ-32B模型成本地部署福音,通义App可第一时间体验
入局智驾的印奇,看到了怎样的未来?
成本打到6万以下,手把手教你用4路锐炫显卡+至强W跑DeepSeek
千里科技亮相吉利AI智能科技发布会,共启“AI+车”新纪元
天翼云CPU实例部署DeepSeek-R1模型最佳实践
京东云与宝德计算战略签约,共绘分布式存储与智算新未来
全球AI顶会AAAI 2025 在美开幕,产学研联手的“中国队”表现亮眼
蚂蚁数科提出创新跨域微调框架ScaleOT入选全球AI顶会AAAI 2025
国产软件再破记录!阿里云PolarDB数据库登顶TPC-C双榜第一
