
通义千问主力模型降价97%,1块钱能买200万tokens
5月21日,阿里云在武汉AI智领者峰会上官宣,通义千问GPT-4级主力模型Qwen-Long,API输入价格从0.02元/千tokens降至0.0005元/千tokens,直降97%。
这意味着,1块钱可以买200万tokens,相当于5本《新华字典》的文字量。
这款模型最高支持1千万tokens长文本输入,降价后约为GPT-4价格的1/400,直接击穿了全球底价。

Qwen-Long是通义千问的长文本增强版模型,性能对标GPT-4,上下文长度最高可达1千万。除了输入价格降至0.0005元/千tokens,Qwen-Long输出价格也直降90%至0.002元/千tokens。
相比之下,国内外厂商GPT-4、Gemini1.5 Pro、Claude 3 Sonnet及Ernie-4.0每千tokens输入价格分别为0.22元、0.025元、0.022元及0.12元,均远高于Qwen-long。
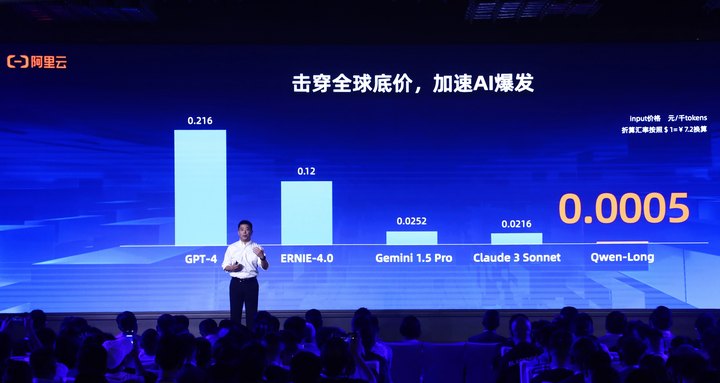
通义千问本次降价共覆盖9款商业化及开源系列模型。不久前发布的通义千问旗舰款大模型Qwen-Max,API输入价格降至0.04元/千tokens,降幅达67%。Qwen-Max是目前业界表现最好的中文大模型,在权威基准OpenCompass上性能追平GPT-4-Turbo,并在大模型竞技场Chatbot Arena中跻身全球前15。

不久前,OpenAI的Sam Altman转发了Chatbot Arena榜单来印证GPT-4o的能力,其中全球排名前20的模型中,仅有的三款中国模型都是通义千问出品。
业界普遍认为,随着大模型性能逐渐提升,AI应用创新正进入密集探索期,但推理成本过高依然是制约大模型规模化应用的关键因素。
在武汉AI智领者峰会现场,阿里云智能集团资深副总裁、公共云事业部总裁刘伟光表示:“作为中国第一大云计算公司,阿里云这次大幅降低大模型推理价格,就是希望加速AI应用的爆发。我们预计未来大模型API的调用量会有成千上万倍的增长。”
刘伟光认为,不管是开源模型还是商业化模型,公共云+API将成为企业使用大模型的主流方式,主要有三点原因:
一是公共云的技术红利和规模效应,带来巨大的成本和性能优势。阿里云可以从模型自身和AI基础设施两个层面不断优化,追求极致的推理成本和性能。阿里云基于自研的异构芯片互联、高性能网络HPN7.0、高性能存储CPFS、人工智能平台PAI等核心技术和产品,构建了极致弹性的AI算力调度系统,结合百炼分布式推理加速引擎,大幅压缩了模型推理成本,并加快模型推理速度。
即便是同样的开源模型,在公共云上的调用价格也远远低于私有化部署。以使用Qwen-72B开源模型、每月1亿tokens用量为例,在阿里云百炼上直接调用API每月仅需600元,私有化部署的成本平均每月超1万元。
二是云上更方便进行多模型调用,并提供企业级的数据安全保障。阿里云可以为每个企业提供专属VPC环境,做到计算隔离、存储隔离、网络隔离、数据加密,充分保障数据安全。目前,阿里云已主导或深度参与10多项大模型安全相关国际国内技术标准的制定。
三是云厂商天然的开放性,能为开发者提供最丰富的模型和工具链。阿里云百炼平台上汇聚通义、百川、ChatGLM、Llama系列等上百款国内外优质模型,内置大模型定制与应用开发工具链,开发者可以便捷地测试比较不同模型,开发专属大模型,并轻松搭建RAG等应用。从选模型、调模型、搭应用到对外服务,一站式搞定。
好文章,需要你的鼓励


《紫罗兰之梦》:耗资2000美元的AI电影,是AI垃圾还是电影制作的未来?
伊朗裔英国导演Ash Koosha耗时两个半月,以不足2000美元的成本,借助AI技术完成了一部关于伊朗反政府抗议镇压事件的75分钟剧情片《紫罗兰之梦》。该片即将在纽约翠贝卡电影节首映,成为首部入围顶级电影节的全AI真人故事片。导演认为,AI技术可大幅降低独立电影制作门槛,有望重塑整个影视行业格局。

当虚拟人物终于能“真实地打一拳“——来自耶路撒冷希伯来大学的4D人物动作仿真突破
耶路撒冷希伯来大学研究团队提出PhyGenHOI框架,将人体运动生成与物理仿真结合,让虚拟人物与三维物体之间的接触互动同时满足视觉自然性和物理真实性。

MIT研究人员开发图表理解AI训练数据集ChartNet
MIT与MIT-IBM计算研究实验室联合开发了专为图表理解设计的数据集ChartNet,包含逾百万张多样化图表及对应代码、文字描述、数值表格和问答对。研究团队利用两步合成数据生成流程,从单张图表出发可扩展出数百种变体。实验表明,基于ChartNet训练的小型开源视觉语言模型在数据提取、图表摘要等任务上显著超越体量更大的商业模型,有望帮助预算有限的中小企业低成本接入AI图表分析能力。

弗莱堡大学等机构联合研究:让AI学会“立体思考“,彻底解决图像匹配中的左右不分难题
本文介绍了弗莱堡大学等机构提出的3D-SC框架,通过引入三维基础模型的几何先验,无需人工标注即可解决AI图像匹配中的左右混淆和重复部件分不清的问题。
2024
05/21
11:41
分享
点赞

MIT研究人员开发图表理解AI训练数据集ChartNet
哈萨克斯坦紧急救援部门采购特斯拉Cybertruck,成为其海外新买家
法院裁定马斯克须在苹果/OpenAI诉讼中提交特斯拉和SpaceX邮件
芯片热潮引爆韩国股市跻身全球第六,但泡沫隐忧渐显
AI编程智能体协作失败:两个模型合作效果不如一个
谷歌发布Fitbit Air蓝图,允许任何人自制表带和配件
AI时代的终端管理:旧规则为何正在走向崩溃
思科Jeetu Patel谈如何破解"AI信任赤字"难题
Meta AI客服机器人泄露账户,Instagram遭遇大规模黑客攻击
劳斯莱斯Spectre Series II升级NACS充电并提升16%续航至308英里
Capita数据泄露案:苏格兰居民获准发起集体诉讼
Motive发布Vision 26峰会成果,推动车队安全与运营效率全面升级
