
Computex 2024:英伟达AI路线及战略分析
英伟达在台北 ComputeX 2024 大会上展示了英伟达在加速计算和生成式AI领域的最新产品,梳理了未来计算、应用包括AI机器人技术的发展与应用,从 AI硬件、软件、生态、下游应用等全方位梳理英伟达在AI领域的产品与发展路径。
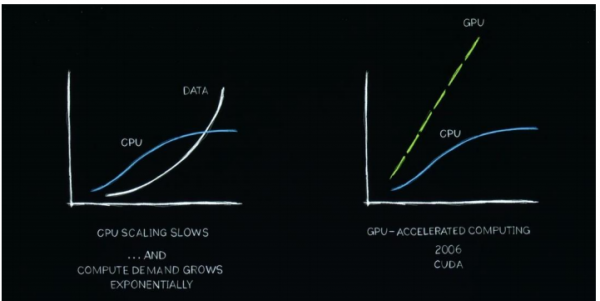
英伟达从加速运算、及GPU两方面改变科技产业发展。
加速运算,解决性能扩展大幅放缓与数据处理量飞速上升的矛盾。如果处理的需求,数据量继续呈指数级增长,但CPU性能不能持续快速扩展,那将经历计算膨胀。近二十年来,英伟达一直在研究加速计算,可以增强CPU,加速专门处理器可以做得更好的工作。
GPU是新的架构,适合用于并行运算场景。专用处理器可以将耗时很长的任务加速到极快的速度。因为CPU和GPU可以同时工作,它们都是自主的,独立的,可以将原本需要 100 个时间单位的任务加速到 1 个时间单位,速度的提升是难以置信的,效果非常显著,速度提升了 100 倍,但功耗只增加了大约三倍,成本只增加了约 50%。
专用处理器可以将需要处理很长时间的事情,加速到很快,并且成本相对较低。例如这里本身100T的事情,原本需要100个小时去处理,但是发明了CPU+GPU的架构,可以并行独立处理,现在只需要1个小时,但是它所需的电力成本只增加了3倍,而成本可能只增加了50%。
软件层面是GPU的最大门槛。从CPU切换到GPU,需要重写底层软件等,使其能够被加速并行计算。为了使加速计算能得到广泛应用,英伟达创新了一系列不同领域的库。虽然加速计算技术能够带来芯片显著的性能提升和成本节约,但也需要软件相匹配,以适应加速器并行运行,这不仅需要重新设计和编码,而且要求深入理解并行计算原理。为此,经过英伟20年里的研究,推出了一系列库。

加速计算的软件门槛:英伟达致力于让世界变得更容易,举例来看:
加速计算领域—cuDNN深度学习库:它专门针对神经网络加速进行了优化,使得深度学习模型的训练和推理过程能消耗更少的资源但以更高的速度完成。此外,英伟达还为人工智能物理模拟提供了专门的库,支持流体动力学等需要遵循物理定律的应用,进一步提高了模拟的效率和准确性;
5G无线电技术加速领域—Aerial库:它利用CUDA技术加速5G无线电技术,使得电信网络能够像软件定义互联网网络一样,通过软件定义和加速实现更高的性能。这不仅提升了整个电信行业的计算能力,也为云计算平台的发展提供了新的可能性;
芯片制造领域—Coolitho计算光刻平台:它通过加速计算技术,显著提高了掩模制作的效率,帮助台积电等公司节省了大量能源和成本。
这些特定领域的库是英伟达生态系统中的关键组成部分。如果没有这些库,全球的深度学习科学家可能无法充分利用CUDA的潜力,因为CUDA与TensorFlow、PyTorch等深度学习框架中使用的算法之间存在显著差异。这些库使得加速计算得以广泛应用,帮助英伟达在市场中保持开放和领先。
上周,谷歌宣布他们将cuDF放进了他们的云端系统,使他们的pandas更快。这是世界上最受欢迎的数据科学库,它被世界上1000万数据科学家使用,每个月下载170次。现在只需要一个键,就可以使用它,发现使用起来很快。当你加速数据处理那么快时,演示不会花费很长时间。
英伟达持续为AI发展做贡献
回顾NV与AI发展历程:
- 2012 年,公司研究人员发现原先的CUDA架构是非常好用的,为了使深度学习成为可能,开始和很多科学家进行合作;
- 2016年,英伟达将公司研发的第一台DGX超级电脑出售给OPEN AI;
- 2017年,世界出现了Transformer,在数千个、数万个Nvidia GPU上训练,并有企业有了成果。例如,OPEN AI宣布了ChatGPT,5天后就拥有了100万用户,2个月后拥有数百万用户。
- 2022 年,OpenAI 发布了 ChatGPT,五天内用户达到一百万,两个月内达到一亿,成为历史上增长最快的应用。
Transformer 使得无监督学习成为可能。所需算力不断增长,需要更大的GPU——Blackwell。
Blackwell架构以美国统计学家和数学家 David Harold Blackwell 的名字命名,是英伟达首个采用 MCM(多芯片封装)设计的 GPU,基于该架构实现的B200是英伟达目前能实现的最大芯片,合计搭载2080亿晶体管(两个基础芯片通过10tb /秒的英伟达芯片对芯片链路连接成一个统一的GPU。和H100架构的6个HBM接口相比,Blackwell的拼接方式进采用了4个HBM接口,这样一来就在存储接口方面节约了芯片面积。
从2016年Pascal架构提供19TFLOPS(FP16)至今,算力参数已经提升到了Blackwell架构提供的20PFLOPS(FP4),整整提升了1000倍。相比于Hopper平台,Blackwell平台具有六项革命性技术,在传统FP8精度下实现Hopper平台2.5倍性能,并新增FP4、FP6精度,FP4精度下实现Hopper平台的5倍性能表现, 能够在拥有高达 10 万亿参数的模型上实现 AI 训练和实时 LLM 推理。
DGX B200:DGX B200搭载8个B200 GPU,提供72PFLOPS训练算力和144PFLOPS推理算力,在推理、训练、加速数据处理中,分别表现出H100的15倍、3倍、2倍性能。根据英伟达在业绩说明会中表示,AI推理需求会不断上升,DGX B200在AI推理端性能的巨额提升将助力英伟达抢占AI推理市场。
GB200:GB200由两个B200和一个Grace CPU结合形成,通过900GB/s的超低功耗NVLink芯片间互连技术连接在一起,提供40PFLOPS(FP4)的算力,384GB内存,1.6TB/s带宽。搭载两个GB200的元件作为Blackwell计算节点,18个计算节点在NVLink Switch的支持下构成GB200 NVL72,最终用Quantum InfiniBand交换机连接,配合散热系统组成新一代DGX SuperPod集群。GB200 NVL72全部采用铜链接用以密集封装、互联GPU,无需采用光学收发器,可以简化操作,同时节省20kw用于计算,大幅提升其AI效能。
第五代NVLink:为了加速万亿参数和混合专家人工智能模型的性能,最新一代NVIDIA NVLink为每个GPU提供突破性的1.8TB/s双向吞吐量,确保最多576个GPU之间的无缝高速通信,适用于最复杂的LLM。
NVIDIA Spectrum-X是全球首款专为AI打造的以太网网络平台,可将网络性能较传统以太网网络平台提升1.6倍。Spectrum-X能够加快AI工作负载的处理、分析和执行速度,进而加快AI解决方案的开发和部署速度。其平台目前有Spectrum-X800,速度为每秒51.2Tbps,256个端口;25年将会推出512个端口的Spectrum-X,即Spectrum-X800 Ultra;26年推出X1600。X800和X800Ultra都是为成千上万个GPU设计的,而X1600是为数百万个GPU而设计的,其性能更强。
Blackwell是第一代NV平台,后续将持续迭代。公司生成式AI的推出,新的产业革命开端有很多合作伙伴。公司希望可以持续强化效能降低成本,扩充AI能力,让公司都能拥有AI;Blackwell会把GPU连接在一起,平台整合成AI工厂,让全世界可以使用。
- 2024年Blackwell芯片现已开始投产;
- 2025年,推出Blackwell Ultra GPU(8S HBM3e 12H);
- 2026年,推出Rubin GPU(8S HBM4);
- 2027年,推出Rubin Ultra GPU(12S HBM4),基于Arm的Vera CPU,以及NVLink 6 Switch(3600GB/s)。
好文章,需要你的鼓励


苹果2026年六大产品发布前瞻
苹果计划在2026年推出多款重磅新品,包括配备miniLED面板和A19 Pro芯片的27英寸外接显示器、搭载homeOS系统的7英寸智能家居控制设备、首次采用OLED屏幕的全新MacBook Pro、具备7.8英寸内屏的iPhone Fold折叠手机、售价699美元起的入门级MacBook,以及升级OLED显示技术的iPad mini。

阿里巴巴团队首次让AI学会真正“冲浪“网页:小模型也能像侦探一样深度挖掘网络信息
阿里巴巴团队开发出革命性AI浏览技术NestBrowse,让AI学会像侦探般深度挖掘网络信息。该系统采用双层嵌套结构,外层负责整体决策,内层专注信息提取,突破传统搜索局限。仅40亿参数的小模型就能超越大型系统,在复杂信息搜索任务中表现出色,为AI技术普及开辟新路径。

OpenAI招聘新任安全准备主管应对AI潜在危害
OpenAI正在招聘新的安全准备主管,负责预测其AI模型的潜在危害和滥用方式,以指导公司安全策略。这一职位出现在ChatGPT因对用户心理健康影响而面临多起诉讼的背景下。CEO阿尔特曼承认模型对心理健康的影响是2025年预见的挑战之一。该职位年薪55.5万美元加股权,将领导OpenAI准备框架的技术策略。

西湖大学携手蚂蚁集团突破AI视频理解瓶颈:OmniAgent让机器像人类一样“边听边看“分析视频
西湖大学联合蚂蚁集团推出OmniAgent,首个能够"边听边看"主动分析视频的AI系统。该技术突破了传统方法的局限,采用音频引导的"粗到细"感知策略,让AI像侦探破案一样灵活调用不同工具。在三大基准测试中,OmniAgent准确率比现有最佳模型提升10-20%,为智能视频理解开辟了全新路径。
2024
06/17
17:04
分享
点赞

