
以太网:如何满足AI计算互联要求?

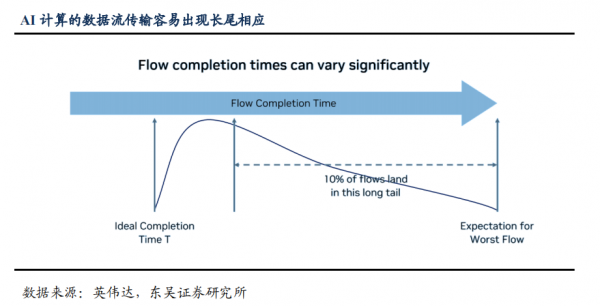
传统云计算及相应算法产生的数据流基本为占用内存小、波动范围小的流量,因此虽然网络为非全局路由,按照既定策略为流量分配路径也不会过多出现拥塞;AI 计算产生的数据流中大象流(Elephant Flow)显著增加,对于少数被分配较多大象流的路径,其传输时间将显著高于大部分路径,这就会产生“长尾效应”,大部分路径传输完成后闲置等待少数路径完成传输,系统利用率因此打折扣。
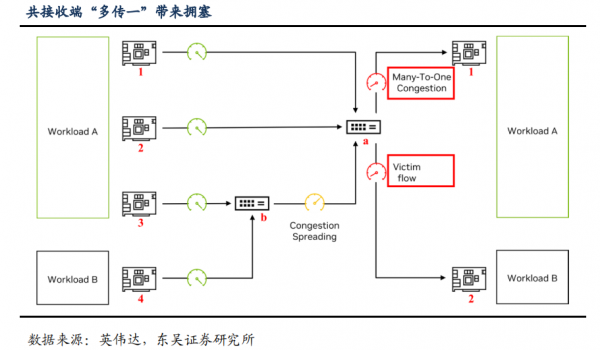
不同计算进程间数据共接收端,容易出现“受害者流量”。AI 推理集群必然会出现多个负载处理多个用户需求或多条并发请求的情况,不同负载由不同端口输出数据,传输路径上有共用的叶、脊交换机,则共接收端的“多传一”(Many-To-One)现象容易出现网络背压、拥塞传播甚至丢包。
例如下图中,负载 A 由网卡 1、2、3 输出的路径与负载 B 由网卡 4 输出的路径共用交换机 a,且路径 3 与路径 4 共用交换机 b,在常规网络架构下,路径 1、2、3 均按最大带宽连接交换机 a,交换机 a 处出现拥塞,网路背压导致连接交换机 b 的路径也出现拥塞,路径 4 数据流的稳态带宽受到影响,成为“受害者流量”(Victim Flow)。
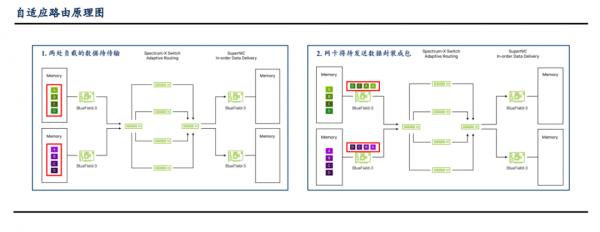
RDMA 网络如何解决潜在问题?“自适应路由”基于网卡及交换机,可解决“大象流”带来的长尾效应。
1)交换机根据各端口数据输出队列状态判断该端口的负荷情况,并将新数据路由至当前负荷最小的端口/路径,这样可有效实现各端口负载均衡;
2)重新路由后的数据一般会按照与原序列不同的顺序到达网卡,网卡利用 DDP 协议(数据报文中的 DDP 前缀包含识别数据原存储位置的信息)将接收到的数据按照原顺序存放。针对 AI 计算中显著增加的“大象流”,自适应路由通过动态监控各端口传输负荷并按此分配路径,均衡负载,解决长尾问题。
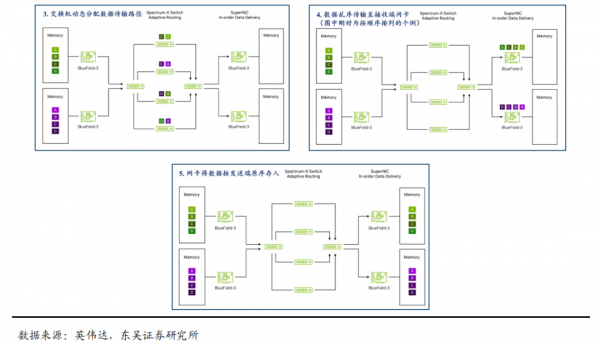
交换机拥塞控制算法+缓存池化实现性能隔离。1)各节点交换机实时监控传输速率及拥塞程度,由交换机芯片接收处理该节点及相邻节点的检测数据,并基于拥塞控制算法调节各相关交换机的传输速率;2)交换机将物理缓存池化,根据不同端口的接收、传输速率分配缓存。
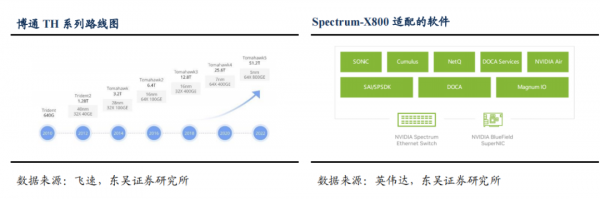
芯片支持容量提升,增加 RoCE 配套功能。交换机芯片支持的容量迭代提升是必然趋势,博通 Tomahawk 5 总容量达 51.2T,支持 64 个端口单口带宽达 800G,相比上代翻倍,英伟达 Spectrum-X800 交换机总容量 51.2T、端口 64 个,分别是上一代的 4 倍和两倍;同时前一章中提到 RoCE 实现的自适应路由、拥塞控制及缓存池化分配等功能均需要交换机、网卡软硬件支持。
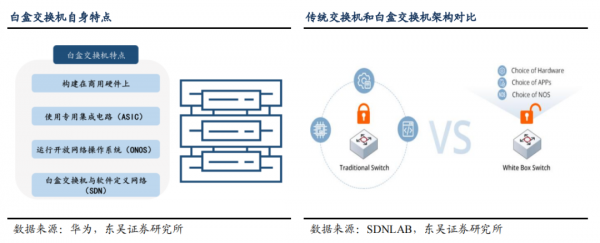
RoCE 带来更多软件客制化可能,白盒交换机有望进一步渗透。白盒交换机采用开放式网络交换架构,将商用硬件与开源软件操作系统相结合,以实现更灵活的网络配置和管理。RoCE 网络中的硬件升级以实现自适应路由、拥塞控制等功能,同时云厂商亦可根据自身硬件特性、需求和痛点自行开发相应功能的算法及软件,白盒交换机在软硬件上的发挥空间进一步扩展。
好文章,需要你的鼓励


让老旧Windows和macOS系统延续生命力
大多数用户只使用计算机预装的操作系统直到报废,很少尝试更换系统。即使使用较老版本的Windows或macOS,用户仍可通过开源软件获益。本文建议通过重新安装系统来提升性能,Mac用户可从苹果官方下载各版本系统安装包,PC用户则建议使用纯净版Windows 10 LTSC以获得更长支持周期。文章强调备份数据的重要性,并推荐升级内存和固态硬盘。对于老旧系统,应替换需要联网的内置应用以降低安全风险,定期进行系统维护清理。

新加坡南洋理工大学提出“棱镜假设“:像光谱仪一样解读图像的神秘密码
新加坡南洋理工大学研究团队提出"棱镜假设",认为图像可像光谱一样分解为不同频率成分,低频承载语义信息,高频包含视觉细节。基于此开发的统一自编码系统UAE,通过频率域分解成功统一了图像理解和生成能力,在多项基准测试中超越现有方法,为构建真正统一的视觉AI系统提供了新思路,有望推动计算机视觉技术向更智能统一的方向发展。

微软计划到2030年用Rust语言替换所有C和C++代码
微软杰出工程师Galen Hunt在LinkedIn上宣布,目标是到2030年消除微软所有C和C++代码。公司正结合AI和算法重写最大的代码库,目标是"1名工程师、1个月、100万行代码"。微软已构建强大的代码处理基础设施,利用AI代理和算法指导进行大规模代码修改。该项目旨在将微软最大的C和C++系统翻译为内存安全的Rust语言,以提高软件安全性并消除技术债务。

当AI遇到“健忘症“:芝加哥大学团队如何让智能助手不再胡编乱造
芝加哥伊利诺伊大学团队提出QuCo-RAG技术,通过检查AI训练数据统计信息而非内部信号来检测AI回答可靠性。该方法采用两阶段验证:预检查问题实体频率,运行时验证事实关联。实验显示准确率提升5-14个百分点,在多个模型上表现稳定,为AI可靠性检测提供了客观可验证的新方案。
2024
07/08
14:04
分享
点赞

