
从H100、GH200到GB200,英伟达如何构建 AI超级计算机SuperPod?
进入AI大模型时代,单个GPU训练AI模型早已成为历史。如何让成百上千个GPU互连,组成宛若一个GPU的超级计算系统,成为业界热点!
1、GPU高性能计算概述 2、GPU深度学习基础介绍 3、OpenACC基本介绍 4、CUDACC++编程介绍 5、CUDAFortr基本介绍
NVIDIA DGX SuperPOD是下一代数据中心人工智能(AI)架构。旨在提供AI模型训练、推理、高性能计算(HPC)和混合应用中的高级计算挑战所需的计算性能水平,以提高预测性能和解决方案的时间。
下面一起学习英伟达H100→GH200→GB200三代产品的GPU互连架构方案。
1、基于H100搭建256 GPU的SuperPod
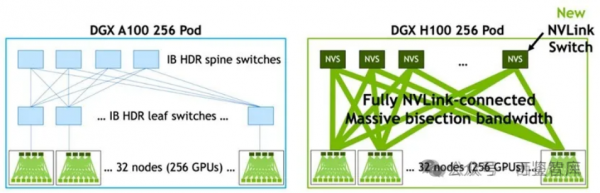
在DGX A100情况下,每个节点上8张GPU通过NVLink和NVSwitch互联,机间(不同服务器)直接用200Gbps IB HDR网络互联(注:机间网络可以用IB网络,也可以用RoCE网络)。
而在DGX H100的情况下,英伟达把机内的NVLink扩展到机间,增加了NVLink-network Switch,由NVSwitch负责机内的交换,NVLink-network Switch则是负责机间交换的交换机,基于NVSwitch和NVLink-network Switch可以搭建256个H100 GPU组成的SuperPod(即一个超级计算系统 ),256个GPU卡Reduce带宽仍然可以打到450 GB/s,和单机内部8个GPU卡的Reduce带宽完全一致。
但是DGX H100的SuperPod也存在一定的问题,跨DGX H100节点的连接只有72个NVLink连接,SuperPod系统里并不是无收敛的网络。
如下图,在DGX H100系统里,四个NVSwitch留出了72个NVLink连接用于通过NVLink-network Switch连接到其他DGX H100系统,72个NVLink连接的总双向带宽是3.6TB/s,而8个H100的总双向带宽是7.2TB/s,因此,在SuperPod系统里在NVSwitch处存在收敛。
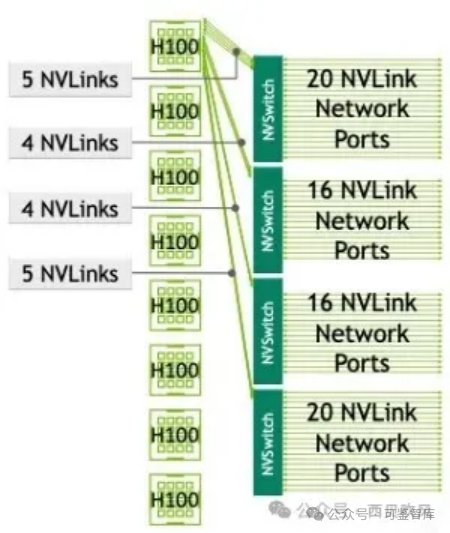
图:基于H100搭建256 GPU的SuperPod
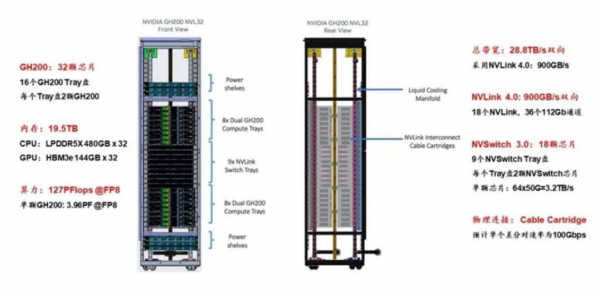
2、基于GH200和GH200 NVL32搭建256 GPU的SuperPod
2023年,英伟达宣布生成式AI引擎DGX GH200投入量产,GH200是H200 GPU(H200与H100主要是内存大小和带宽性能方面的区别)与Grace CPU的结合体,一个Grace CPU对应一个H200 GPU,GH200除了GPU之间采用NVLink4.0连接以外,GPU和CPU之间也采用NVLink4.0连接。
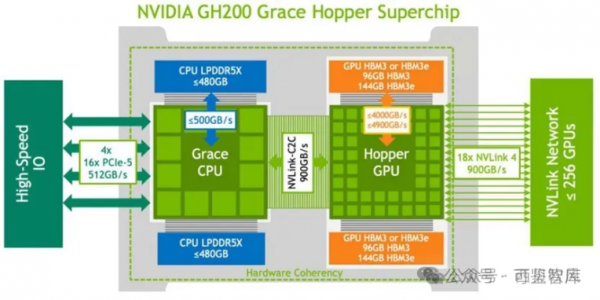
GH200通过NVLink 4.0的900GB/s超大网络带宽能力来提升算力,服务器内部可能采用铜线方案,但服务器之间可能采用光纤连接。对于单个256 GH200芯片的集群,计算侧1个GH200对应9个800Gbps(每个800Gbps对应100GB/s,2条NVLink 4.0链路)光模块。
GH200 SuperPod与DGX H100 SuperPod的区别在于在单节点内部和节点之间互联时都是用NVLink-network Switch互联。
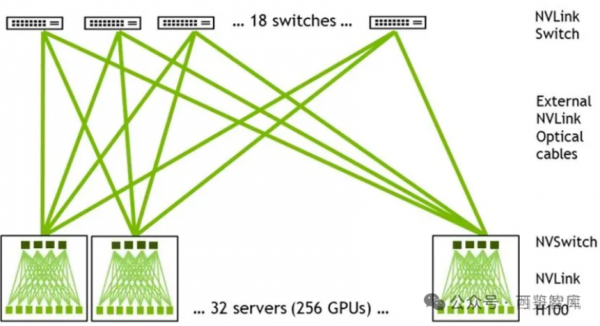
DGX GH200采用二级Fat-tree结构,由8个GH200和3个一级NVLink-network Switch(每个NVSwitch Tray包含2个NVSwitch芯片,有128个Port)组成单机,32个单机经由36个二级NVLink-network Switch全互联,形成了256个GH200的SuperPod(注意是36个二级NVLink-network Switch,这样才能保证无收敛)。
图:基于GH200搭建256 GPU的SuperPod
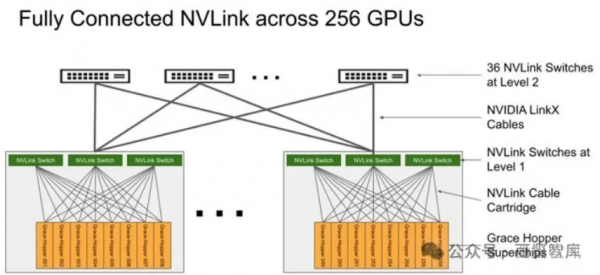
GH200 NVL32为机架级集群,单个GH200 NVL32拥有32个GH200 GPU和9个NVSwitch Tray(18个NVSwitch3.0芯片),如果组成256个GPU的GH200 NVL32超级节点,则需要再配置一级机间的36个NVLink-network Switch即可。
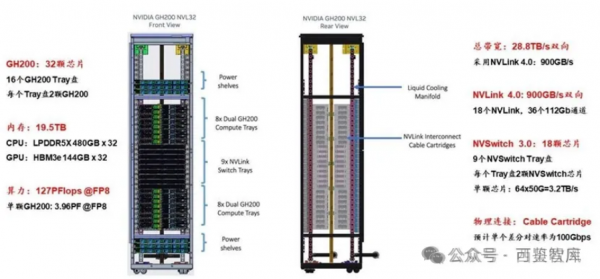
3、基于GB200 NVL72搭建576 GPU的SuperPod
和GH200不同,一个GB200由1个Grace CPU和2个Blackwell GPU组成(注:单个GPU算力不完全等价B200)。GB200 Compute Tray是基于英伟达MGX设计的,一个Compute Tray包含2个GB200,也就是2个Grace CPU、4个GPU。
一个GB200 NVL72节点包含18个GB200 Compute Tray,即36个Grace CPU,72个GPU,此外还包含9个NVLink-network Switch Tray(每个Blackwell GPU有18个NVLink,而每个第4代NVLink-network Switch Tray包含144个NVLink Port,所以需要72*18/144=9个NVLink-network Switch Tray实现全互联)。
图:GB200 NVL72内部拓扑架构
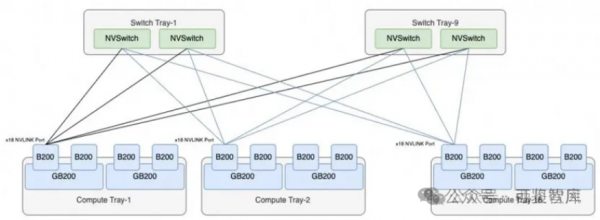
在英伟达的官方宣传中,8个GB200 NVL72组成一个SuperPod,从而组成一个由576个GPU组成的超级节点。
但是,我们通过分析可以看出GB200 NVL72机柜中的9个NVLink-network Switch Tray已经全部用于连接72个GB200了,已经没有额外的NVLink接口用于扩展构成更大规模的两层交换集群了,576个GPU的SuperPod从英伟达官方的图片来看,更多的是通过Scale-Out RDMA网络互联的,而并不是通过Scale-Up的NVLink网络互联的。如果需要通过NVLink互联来支持576个GPU的SuperPod,则需要每72个GB200配置18个NVSwitch,这样单机柜就放不下了。
另外,英伟达官方说NVL72有单机柜版本,也有双机柜的版本,并且双机柜每个Compute Tray只有一个GB200子系统,这样有可能是通过双机柜的版本来实现通过NVLink互联来支持576个GPU的SuperPod,这样这个双机柜版本的每个双机柜有72个GB200和18个NVLink-network Switch Tray,从而可以满足两层集群的部署需要。如下图所示:
图:基于GB200搭建576GPU的SuperPod
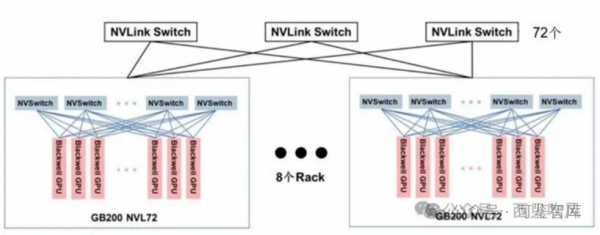
和上一代256个H200全互联类似结构类似,只是第一级及第二级所有的设备台数有所不同,需要两级NVLink-network Switch互联:
第一级的一半Port连接576个Blackwell GPU,所以需要576*18/(144/2) =144个NVLink-network Switch,每个NVL72有18个NVLink-network Switch Tray。第二级Port全部与第一级的NVLink-network Switch Port连接,所以需要144*72/144=72 个NVSwitch。
好文章,需要你的鼓励



Allen AI团队推出SAGE:首个能像人类一样“想看多长就看多长“的智能视频分析系统
Allen AI研究所联合多家顶尖机构推出SAGE智能视频分析系统,首次实现类人化的"任意时长推理"能力。该系统能根据问题复杂程度灵活调整分析策略,配备六种智能工具进行协同分析,在处理10分钟以上视频时准确率提升8.2%。研究团队创建了包含1744个真实娱乐视频问题的SAGE-Bench评估平台,并采用创新的AI生成训练数据方法,为视频AI技术的实际应用开辟了新路径。

联想推出DE6600系列:更智能的存储解决方案
联想推出新一代NVMe存储解决方案DE6600系列,包含全闪存DE6600F和混合存储DE6600H两款型号。该系列产品延迟低于100微秒,支持多种连接协议,2U机架可容纳24块NVMe驱动器。容量可从367TB扩展至1.798PiB全闪存或7.741PiB混合配置,适用于AI、高性能计算、实时分析等场景,并配备双活控制器和XClarity统一管理平台。

AI视觉模型真的能看懂长篇文档吗?中科院团队首次揭开视觉文本压缩的真相
中科院团队首次系统评估了AI视觉模型在文本压缩环境下的理解能力,发现虽然AI能准确识别压缩图像中的文字,但在理解深层含义、建立关联推理方面表现不佳。研究通过VTCBench测试系统揭示了AI存在"位置偏差"等问题,为视觉文本压缩技术的改进指明方向。
2024
08/30
17:04
分享
点赞

