
国产AI视频重大突破!角色一致性,Vidu率先做到了
一觉起来,AI视频又双叕要变天了
之前一直困扰各位创作者的“人物一致性问题”,突然迎来了转机。
话不多说,我们先看效果
“一致性”要重点解决的,就是AI生成影视里的IP问题。
“毕竟没有观众想看自己喜欢的电影主角频频换脸吧”
而这一旦被解决,AI创作短剧、电影、绘本、广告等等等等方面的应用都将会有质的飞跃。

比如这里一个广告片的例子

可能上传的商品图片背景、角度都和要做的广告片不相干,但却能生成一些你想要的“高级”效果。

之前想生成同一人物在不同场景的分镜,通常会先用AI绘画的垫图(通常用Midjourney或者sd),或者局部重绘等方法先生成满意的画面,再通过另外的AI视频软件生成动态视频。

操作麻烦不说,保不齐垫图出来不像,还得加一层AI换脸。。。

而现在,只需上传一张参考图就搞定了,何不快哉!
官方的视频合集上面看了,这里我放点自己实测的效果。
先来个索大试试,我用Midjourney生成了个3D版的,有喜欢的朋友可以后台私信多送你几张。

提示词:索隆吃汉堡
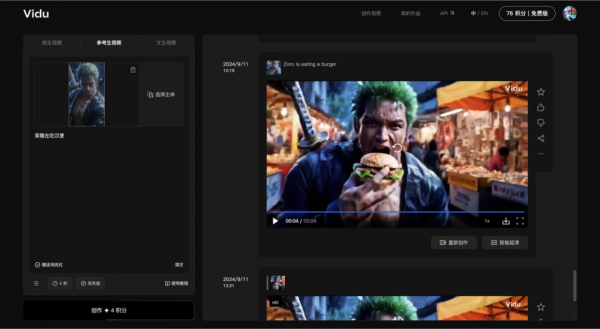
“这标志性绿藻头、胸口上的疤痕、佩刀...”
还原的有点到位!

就是这画质堪忧,Vidu啥时候给提升下。
最近正好在看咒术回战,索性再来个五条悟,也不知道后面复活了没,这次专门找了个2D动漫版的看看效果。

提示词:五条悟在看书

这画风,有一说一确实匹配的让我有些喜出望外,不过同样有点小瑕疵,动作连贯性有待进一步加强,另外,旁边这位女士是...
难道直接预测了五条老师的女友?
不过以上对于一致性问题来说都小问题,等待官方下一版本的优化了,你也可以立即在官网免费体验:https://www.vidu.studio/
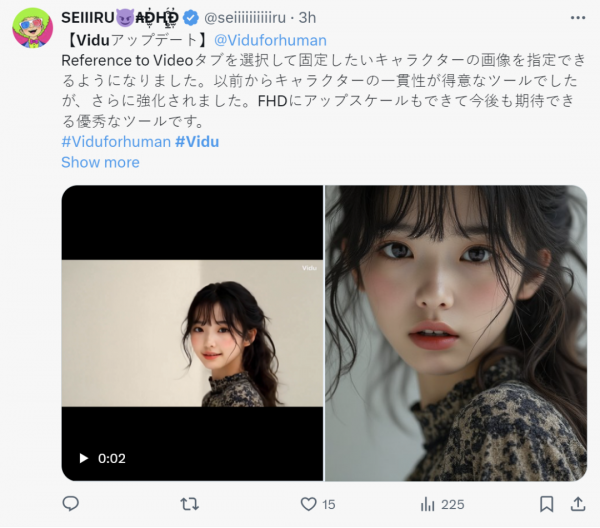
日本的网友也玩得飞起,果然一上来就是小姐姐
依稀记得半年前AI生成视频另一大Bug“4秒动态PPT效果,运动幅度太小”是咱国产的可灵AI率先开放给大家使用的,这次,是生数科技的Vidu。
而“角色一致性”这一功能,除了同样是我们国内的AI视频生成产品Pixverse有尝试,在Runway和其他软件还暂未看到。
乔老爷子曾经说过:“创新区分领袖和跟随者。”
也许之前,在AI生成视频方面,我们国内的AI厂家普遍都在扮演跟随者的角色。但这一次,不论是可灵AI、Pixverse 的大胆创新,还是Vidu的技术突破,国内的AI技术正在从追赶者转型为引领者,在国际舞台占有重要地位。
不但首发即开放给全球用户体验使用,更是在不断创新,探索AI视频领域的未来走向。
我们曾经在追随,但现在,我们正在引领新的变革。
好了,今天就聊到这里。如果你觉得这篇文章有帮助,记得点赞、收藏、分享给朋友们哦!咱们下次见啦!
附:
Vidu官网:https://www.vidu.studio/
可灵AI官网:https://klingai.kuaishou.com/
Pixverse官网:https://pixverse.ai/
好文章,需要你的鼓励


Decart发布Oasis 3世界模型,为机器人训练注入真实感
前沿AI研究机构Decart发布最新世界模型Oasis 3,旨在弥合虚拟仿真与物理AI之间的鸿沟。该模型将超写实交互图形能力与强大物理引擎相结合,可生成动作驱动的视频流,支持多视角环境模拟,延迟低于200毫秒。开发者能够借助自然语言提示,快速构建多样化极端场景,有效解决机器人和自动驾驶领域长期存在的"仿真到现实"差距问题,大幅降低物理AI训练成本。

当AI学会“自学成才“:无需人类喂养的智能代理如何在真实世界中越战越强——来自理海大学等机构的最新突破
OpenSkill是一套让AI代理无需人工监督即可自主成长的框架,通过从互联网获取知识、自建虚拟考题反复练习,实现真正的开放世界自我演化。

Visual Components 5.1发布:工厂仿真软件新版本支持大规模自主生产环境验证
Visual Components正式发布5.1版本工厂仿真软件,重点引入高精度物理仿真与可扩展机器人协同调度能力,支持在同一环境中同时模拟数百台自主移动机器人、自动导引车及人员的运行状态。新版本还将仿真性能提升至前代的10倍,新增Allen-Bradley PLC支持及Nachi、Epson机器人虚拟调试插件,并将脚本环境升级至Python 3。该软件旨在帮助制造商在实际部署前完成系统验证,降低调试风险,缩短投产周期。

当AI评委同时打多份分时,它的判断力会崩溃吗?——来自IIT焦特布尔与亚马逊的联合研究
论文研究了AI评委同时优化多个评判维度时的两大失败原因:梯度稀释与指令干扰,为多目标提示词优化提供了系统性诊断框架。

