
OpenAI首席科学家MIT演讲:揭示 o1模型训练核心秘密

前不久,OpenAI的首席科学家Hyung Won Chung在MIT的一场演讲引发了不少思考。
他揭示了一个培养通用人工智能(AGI)的关键策略:通过激励模型自主学习,才能让机器具备解决多任务的通用技能。
他打了一个非常形象的比喻:大家都听过“授人以鱼,不如授人以渔”
但他更进一步,
提出:“要让他知道鱼有多美味,并且让他保持饥饿”,这样他就会主动学会钓鱼。

这不仅让他学会如何获取鱼,还会激发他学习更多相关的技能,比如阅读天气、了解鱼类习性等。最重要的是,有些技能是通用的,能够应用到其他任务中。
这个类比不仅适用于人类学习,也适用于AI系统。
通过激励机制,AI模型能够在应对不同任务时,自主学习和适应环境变化。
这就是未来AI发展的核心——弱激励学习。
通用智能:让机器学会更多“钓鱼”的方法
在演讲中,Hyung Won Chung详细阐述了通用智能和专用智能的区别。
专用智能是为了特定任务设计的,就像是教人只会一种“钓鱼”方法。
而通用智能则更类似于教会机器在任何环境下灵活运用多种技巧,能应对各种未知的场景。
这种灵活性让通用智能模型能够自适应,不再需要人为教授每个具体任务。

他提出,最好的方法不是直接教模型某个技能,而是通过弱激励机制,让模型在大量的数据和任务中,自己摸索和发展出解决问题的能力。
这种自主学习的能力,是未来通用智能的关键。
计算力:AI的“精神与时间之屋”
Hyung Won Chung还提到了计算能力在AI发展中的关键作用。
他引用了一个有趣的类比:大家还记得《龙珠》里的“精神与时间之屋”吗?在那里训练一年,外界只过了一天。
对于AI来说,计算资源的扩展,让它的“训练时间”大幅缩短——相当于几天时间,它就可以在某些领域超越人类专家。
如今,计算力的指数级增长,已经让AI可以轻松做到这点。
未来,我们可以通过更多的计算资源,让AI模型在短时间内学习海量任务,从而具备超越专家的能力。
涌现能力:机器“学会”人类没教的技能
Hyung Won Chung还提到了一个有趣的现象——涌现能力。
随着模型规模的扩大,AI模型往往会自发表现出一些没有被直接教授的能力。
比如,像GPT-4这样的模型,虽然没有专门教它数学和推理,但它却能自然地表现出这些能力。
这表明,随着模型规模的扩展,机器会自动学会解决新问题的能力,这也让人类对AI的潜力充满期待。
“鱼的美味”与激励学习
Hyung Won Chung特别强调了激励结构的设计。
他认为,未来的AI训练,需要给模型设计更复杂、更有深度的激励结构。
举个例子,现在的语言模型会产生“幻觉问题”,即在没有答案时也会编造出内容。
解决这个问题的办法,就是让模型学会在不确定的情况下回答“我不知道”。
通过调整激励结构,让模型不仅追求正确答案,还要学会在面对未知时保持谨慎,这样AI的可靠性和可信度才能提高。
正如他所说:“教会模型判断自己是否知道答案,远比教它一个特定的技能更为重要。”
这种激励学习的方式,正是让AI模型具备通用能力的关键。
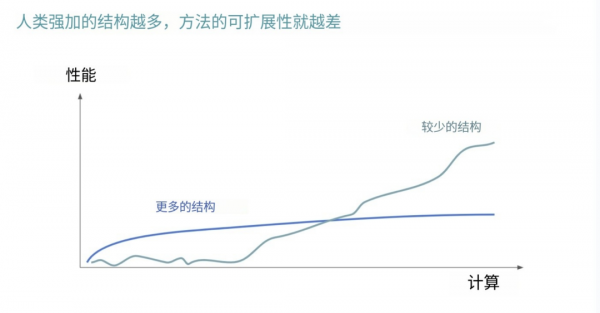
扩展:不仅仅是计算力
通常我们谈到AI的“扩展”,指的是增加更多的计算力,让模型变得更强大。
但Hyung Won Chung提出了一种更深层的扩展理念。他认为,真正的扩展不是简单地增加计算资源,而是要重新设计模型架构,消除那些限制模型进一步提升的障碍。
通过更好的设计,让AI在数据和计算资源的增加中,自动适应并提升性能。
不断“去学习”:迎接AI的快速迭代
Hyung Won Chung还提到了一个非常有意思的观点——去学习。
他解释说,随着AI的发展,研究人员需要学会不断丢掉过去的认知,适应新模型带来的新能力。
每一次新模型的推出,都会颠覆我们对AI的认知。只有保持“去学习”的心态,才能跟上AI领域的快速变化。
深思:激励是最强的驱动力
正如Hyung Won Chung所言,最有效的学习方式是通过激励驱动,这不仅适用于人类,也同样适用于AI。
通过设计精妙的激励结构,模型能够在面对各种任务时自主探索、学习,并逐渐发展出通用能力。这种自主学习的过程让AI具备了更强的适应性和解决问题的能力。
作家赫尔曼·黑塞在《悉达多》中提到的一句话:
“智者追寻的不是永恒的真理,而是一个不断学习和成长的过程。”
对于AI来说,激励机制就像这个追寻的过程,它并不依赖于直接获得某个答案,而是在大量任务中不断寻找、摸索,最终通过自我学习变得更强大。
好文章,需要你的鼓励


IT部门面临的十大挑战与应对策略
CIO们正面临众多复杂挑战,其多样性值得关注。除了企业安全和成本控制等传统问题,人工智能快速发展和地缘政治环境正在颠覆常规业务模式。主要挑战包括:AI技术快速演进、IT部门AI应用、AI网络攻击威胁、AIOps智能运维、快速实现价值、地缘政治影响、成本控制、人才短缺、安全风险管理以及未来准备等十个方面。

北航团队发布AnimaX:让静态3D模型瞬间“活“起来的神奇技术
北航团队发布AnimaX技术,能够根据文字描述让静态3D模型自动生成动画。该系统支持人形角色、动物、家具等各类模型,仅需6分钟即可完成高质量动画生成,效率远超传统方法。通过多视角视频-姿态联合扩散模型,AnimaX有效结合了视频AI的运动理解能力与骨骼动画的精确控制,在16万动画序列数据集上训练后展现出卓越性能。

CIO放弃散弹枪式做法,采用更具战略性的AI试点
过去两年间,许多组织启动了大量AI概念验证项目,但失败率高且投资回报率令人失望。如今出现新趋势,组织开始重新评估AI实验的撒网策略。IT观察者发现,许多组织正在减少AI概念验证项目数量,IT领导转向商业AI工具,专注于有限的战略性目标用例。专家表示,组织正从大规模实验转向更专注、结果导向的AI部署,优先考虑能深度融入运营工作流程并产生可衡量结果的少数用例。

让AI看图说话更详细更准确:上海人工智能实验室团队开发的ScaleCap技术突破
这项研究解决了AI图片描述中的两大难题:描述不平衡和内容虚构。通过创新的"侦探式追问"方法,让AI能生成更详细准确的图片描述,显著提升了多个AI系统的性能表现,为无障碍技术、教育、电商等领域带来实用价值。

