
2024年AMD CPU和GPU技术进展
6月3日,AMD在台北 ComputeX 2024 大会上详细展示了其在CPU、GPU及UA互联等方面的最新产品:
Zen 5:展示被苏姿丰称之为“迄今为止性能最高、能效最高的处理器核心”——全新Zen 5核心 。
第二代XDNA NPU架构:XDNA NPU 2引入了全新的Block FP16 (BF16)浮点精度,其AI引擎性能是第二代 AMD 锐龙 AI 的三倍,是目前唯一可提供 50 TOPS 的AI 处理性能的产品。
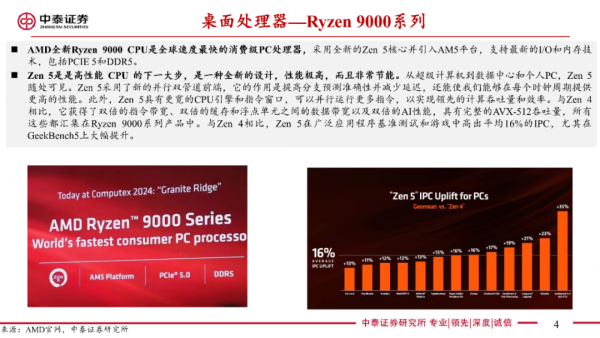
消费级PC处理器:推出全新Ryzen 9000 CPU,全球速度最快的消费级PC处理器,采用Zen5核心,并引入AM5平台,支持最新的I/O和内存技术。首发有4款产品均于今年7月出售。
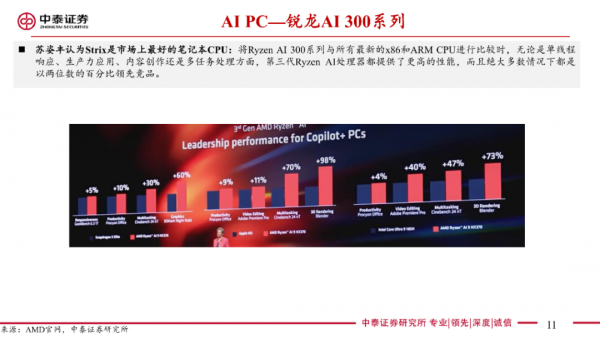
AI PC处理器:AMD下一代超薄和高端笔记本电脑的处理器“Strix Point”,苏姿丰称之为“面向下一代AI PC/Copilot+PC的世界一流处理器”。该系列产品展示的有Ryzen AI 9 HX370。
全新Versal AI Edge Gen 2系列:提供首个集成预处理、推理和后处理的单芯片自适应解决方案。
AI GPU:缩短产品更新时间,计划今年将推出速度更快、内存更大的MI325X;25年推出新的cDNA4架构的MI350系列;26年,将推出带有全新cDNA架构的MI400系列。
UA-Link:展示AMD在推动高性能AI网络基础设施系统的发展方面也取得了重大进展:计划将于今年推出UA-Link 1.0标准。

























好文章,需要你的鼓励


米拉·穆拉提重返公众视野,谨慎发声
穆拉蒂时隔18个月首次接受重大媒体采访,介绍其创立的Thinking Machines Lab正在开发的"交互模型"。该模型能以200毫秒间隔处理音频、文本和视频流,捕捉人类交流中的中断、修正和停顿。她还谈及OpenAI"政变周"经历,强调行业决策权过于集中的担忧,并回应了公司近期研究人员离职问题,表示这是初创实验室的正常波动。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
本期《Quick Charge》播客涵盖多个热点话题:特斯拉疑似试图删除FSD欺诈相关证据以规避巨额赔付;卡特彼勒持续推进建筑领域电气化布局;住宅太阳能30%税收抵免即将到期。此外,嘉宾Tom Pacheco就高压系统与电池技术培训展开探讨,强调电动车技术人才培养的紧迫性。节目同时提醒有意安装太阳能的用户尽快行动,可通过EnergySage平台比较多家安装商报价。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2024
10/09
21:04
分享
点赞

