
搭建一个 AI 问答机器人,需要几步?
搭建一个企业内部AI 问答机器人、知识库的场景,我们可以选择大厂的云服务,这相对于大多数用户来说,是最省事的方案。但很多企业可能会有一些私有化的数据,或者受限于企业内部的安全性要求,只能走模型私有化部署的方式。
很多人想到模型私有化部署,会以为要数据中心的多台服务器来做,其实不然。

赞奇科技基于 NVIDIA ChatRTX 搭建的企业问答机器人
但搭建一个AI 问答机器人又是一个涉及硬件选择、安装、开发环境部署的综合过程。
最近赞奇的工程师团队测试了几款主流大模型,就采用 AI 工作站搭建一个本地问答机器人提供了一些建议参考,这里抓一些重点给大家:
第一步
确定需求与目标
这一步至关重要,需要确定以下关键点:
- 性能要求:了解所做任务的复杂度,如知识库所需要采样的数据库的大小,未来的用户并发量等,以此来预估所需的计算资源和存储空间等,通常我们可以用现有机器跑任务测试的方式来评估。
- 预算范围:明确愿意投入的资金等成本范围。对预算没有概念的小伙伴可以通过询问,或者参考公开市场价格等方式来加速了解。
第二步
选择合适的硬件
根据需求我们来制定硬件配置,AI 工作站比较关键的配置有 GPU、CPU、内存、机箱等。
GPU
GPU 是 AI 工作站中非常核心的算力,也是 AI 工作站中需要首先考虑的配件。目前适用于专业 AI 工作站的显卡主要有 NVIDIA RTX(TM) 5880 Ada (48GB) 及 NVIDIA RTX(TM) 5000 Ada (32GB) 等,这两款显卡属于 NVIDIA 专业级显卡,主动散热、功耗很低而且非常稳定,静音也适合办公室使用。
我们可以看看两款显卡的参数:
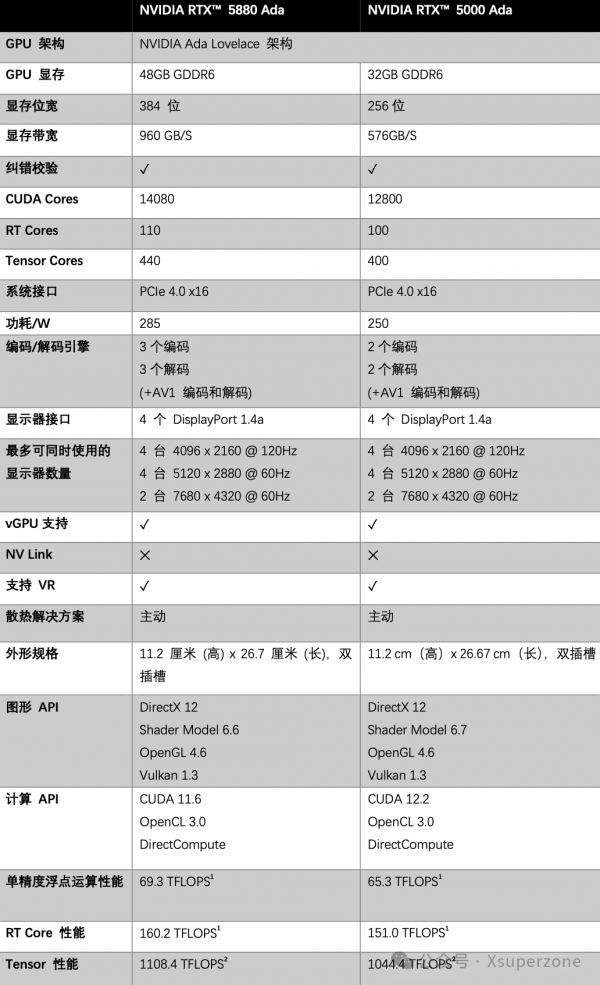
我们需要根据算力需求来配置工作站中的显卡,包括显卡型号和数量。AI 工作站可至多支持 4 张高性能专业显卡,同时一个工作站中需要配置同一型号的显卡,并且一般采用单卡、双卡和四卡的配置。
这就需要我们同时要了解不同型号显卡的性能,才能来匹配任务需求。这是个极大的挑战。很多人对显卡性能并不熟悉,而且在不同的任务情况下,显卡的表现也会有所不同。我们可以参考与我们类似的任务在显卡上的测评数据来评估。有条件的话,在购买时建议最好提前测试下。
显卡实测数据
很多企业采用 AI 工作站来做知识库、智能问答等应用,主要任务是本地的模型微调和推理,模型大小普遍选择在 7B/8B,13B,32B 和 70B。
NVIDIA 解决方案合作伙伴赞奇科技,分别对 AI 工作站中搭载 NVIDIA RTX 5880 Ada、NVIDIA RTX 5000 Ada 的单卡、双卡、四卡配置进行了模型训练和推理的测试,测试数据供大家在选型时参考。
AI 工作站搭载 NVIDIA RTX 5000 Ada 的实测

NVIDIA RTX 5000 Ada
(图片源于 NVIDIA)
测试环境:
CPU: Intel(R) Xeon(R) w5-3433
内存:64G DDR5 * 8
GPU: NVIDIA RTX 5000 Ada * 4
操作系统:ubuntu22.04
Driver Version: 550.107.02
CUDA: 12.1
推理框架:vllm
测试数据(以下数据均为多次测试数据的平均值):
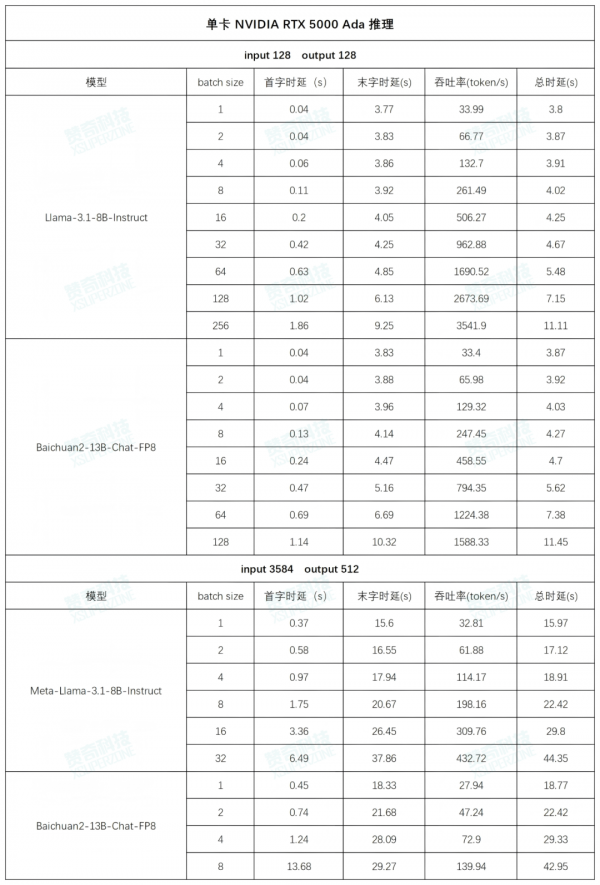
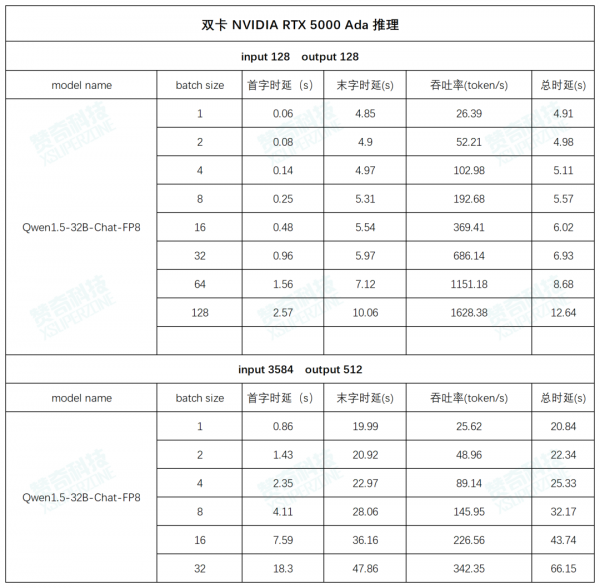
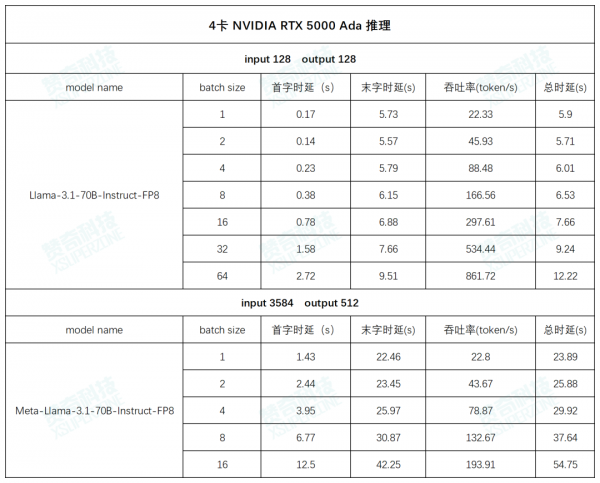
左右滑动查看更多测试数据
AI 工作站搭载 NVIDIA RTX 5880 Ada 的实测

NVIDIA RTX 5880 Ada
(图片源于 NVIDIA)
测试环境:
- CPU: Intel(R) Xeon(R) w5-3433
- 内存:64G DDR5 * 8
- GPU: NVIDIA RTX 5880 Ada * 4
- 操作系统:ubuntu 22.04
- Driver Version: 550.107.02
- CUDA: 12.1
- 推理框架:vllm
测试数据(以下数据均为多次测试数据的平均值):
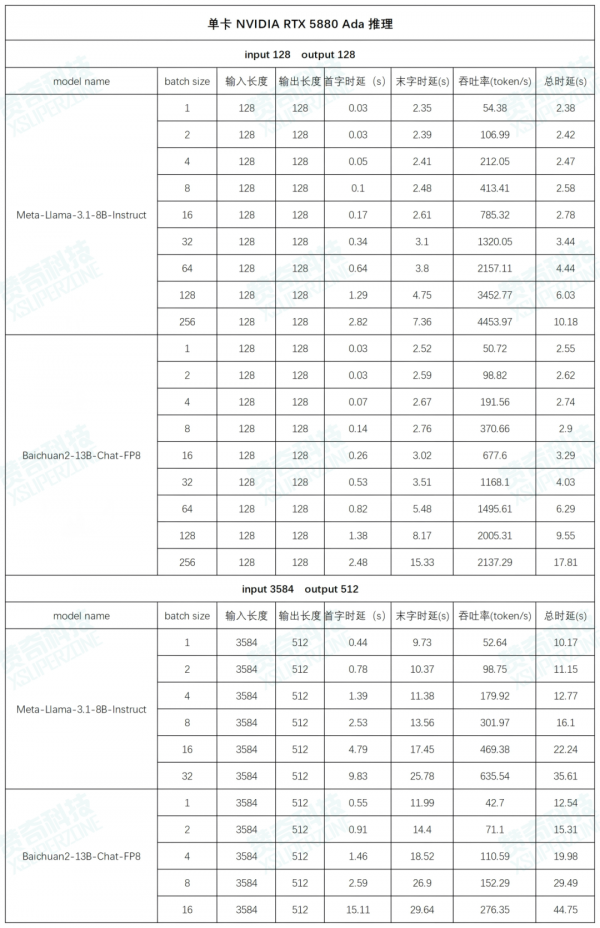
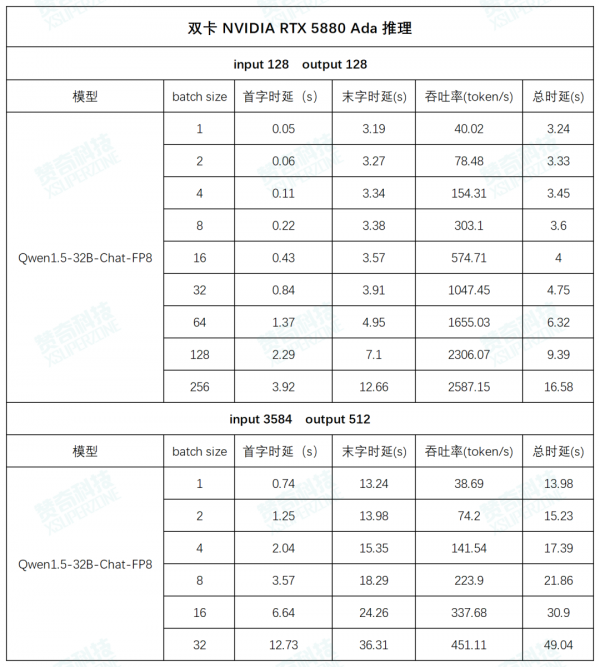
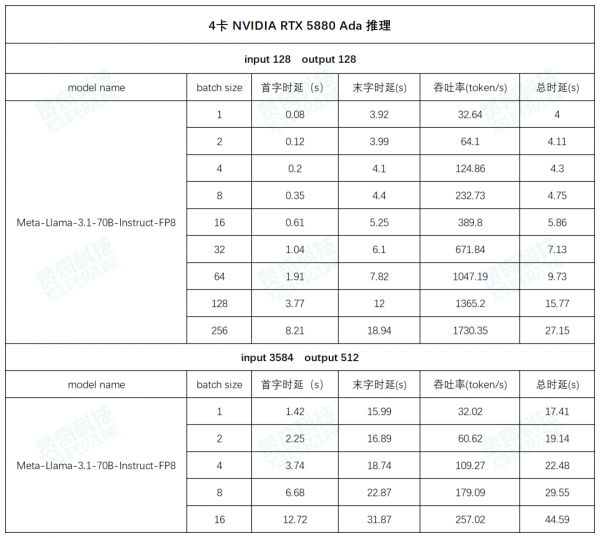
左右滑动查看更多测试数据
噪音测试
无论是搭载 4 张 NVIDIA RTX 5880 Ada, 还是 4 张 NVIDIA RTX 5000 Ada 的品牌 AI 工作站,在压测情况下机器出风口测得的噪音水平控制在 50-60 分贝,基本上接近环境音的水平,办公室噪音?那是没有的!
好文章,需要你的鼓励



不用读论文,AI工程师用“图书馆分级借阅“方案让大模型记住12.8万字长文——不列颠哥伦比亚大学与微软研究院联合出品
不列颠哥伦比亚大学与微软研究院提出SEKV,通过熵引导语义分段和GPU-CPU分级存储,在12.8万字上下文下将显存降低53.3%,同时比最强语义压缩基准提升5.9%。

AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
AI评估初创公司Braintrust确认其AWS云账户遭未经授权访问,导致客户API密钥泄露风险。公司已通知所有客户立即更换存储在其平台上的API密钥,并表示已封锁受损账户、审计相关系统访问权限,同时对内部密钥进行了轮换。目前,Braintrust正对事件原因展开调查。安全专家指出,此次泄露可能对依赖该平台的AI公司产生连锁影响。该公司今年2月完成8000万美元B轮融资,估值达8亿美元。

当机器人在脑海中“做白日梦“:POSTECH与KAIST联手解决AI规划中的幻觉问题
ACID框架通过引入逆向动力学模型对AI规划轨迹进行"现实检验",解决了机器人规划系统只看终点不看过程的根本缺陷,在六种任务上全面提升性能。

