
AI数据中心:网络设计和选型标准
为了最大化分布式训练的效能,就需要构建出一个计算能力和显存能力超大的集群,来应对大模型训练中算力墙和存储墙这两个主要挑战。
而联接这个超级集群的高性能网络直接决定了智算节点间的通信效率,进而影响整个智算集群的吞吐量和性能。要让整个智算集群获得高的吞吐量,高性能网络需要具备低时延、高带宽、长期稳定性、大规模扩展性和可运维等关键能力。

AIDC的网络选型
当前 AIDC 的大规模网络架构主要有两种,一种是InfniBand网络,一种是 RoCE 网络,二者各有优势。
InfniBand网络
InfniBand网络自从诞生以来就专注于高性能领域,当前市场主流的 IB 技术为 400Gbps 的 NDR。IB 网络是专门为超算集群设计的网络,它有两个特点:
原生无损网络 :InfniBand 网络采用基于 credit 信令机制来从根本上避免缓冲区溢出丢包。只有在确认对方有额度能接收对应数量的报文后,发送端才会启动报文发送。依靠这一链路级的流控机制,可以确保发送端绝不会发送过量,网络中不会产生缓冲区溢出丢包。
万卡扩展能力 : InfniBand 的 Adaptive Routing 基于逐包的动态路由,在超大规模组网的情况下保证网络最优利用。
目前业内有大量万卡规模超大 GPU 集群的 IB 案例。
RoCE网络
RoCE(RDMA over Converged Ethernet)是在 InfniBand Trade Association(IBTA)标准中定义的网络协议,
允许通过以太网络使用 RDMA(Remote Direct Memory Access,远程直接访问内存)。简而言之,它可以看作是RDMA 技术在超融合数据中心、云、存储和虚拟化环境中的应用。RoCE 网络的特点如下:
生态开放:RoCE 生态基于成熟的以太网技术体系,业界支持厂商众多。相比于 IB 交换系统,RoCE 网络不需要专用硬件,可以基于多厂商开放的硬件网卡 / 交换机等进行部署。同时业务的开通、运维与传统以太网技术一脉相承,配置、维护更为简单。
速率更快:以太网技术广泛应用于数据中心网络、城域网、骨干网,当前速率可以灵活支持 1Gbps~800Gbps,未来有望演进至 1.6Tbps。与 IB 相比,在互联端口速率和交换机总容量上更胜一筹。
成本较低:以太网高端芯片经过多年的技术发展积累,其单位带宽成本更具竞争力,交换机成本整体更低。

具体到实际业务层面,InfniBand 方案一般要优于 RoCE 方案,RoCEv2 是足够好的方案,而 InfniBand 是特别好的方案,以下将从业务层面对比下这两种方案。
业务性能方面,由于 InfniBand 的端到端时延小于 RoCEv2,所以基于 InfniBand 构建的网络在应用层业务性能方面占优。但 RoCEv2 的性能也能满足绝大部分智算场景的业务性能要求。
业务规模方面,InfniBand 能支持单集群万卡 GPU 规模,且保证整体性能不下降,并且在业界有比较多的商用实践案例。
RoCEv2 网络能在单集群支持千卡规模且整体网络性能也无太大的降低。
业务运维方面,InfniBand 较 RoCEv2 更成熟,包括多租户隔离能力,运维诊断能力等。
业务成本方面,InfniBand 的成本要高于 RoCEv2,主要是 InfniBand 交换机的成本要比以太交换机高一些。
业务供应商方面,InfniBand 的供应商主要以 NVIDIA 为主,RoCEv2 的供应商较多。
AIDC的网络设计
面对 AIDC 对网络的高要求,通常情况下独立建一张高性能网络来承载智算业务是最好的方案,可同时满足高带宽、无阻塞的需求。
高带宽设计:当前大模型 AI 训练中会涉及大量的数据交互,对带宽有着极高的要求。目前智算服务器主流配置是配置8 张 GPU,并预留一定数量的 PCIe 插槽用于网络设备,视智算集群的网络需求会配置 4 张 100Gbps 以上的网卡,极端情况下甚至会配置 8 张以上的 100Gbps 以上的网卡。尤其是针对 NVLink 机型,当前主流方案是按照 GPU:IB 网卡 1:1 的模式来配置网卡,这种情况下每台机器会配置 8 张 HDR 甚至是 NDR 的网卡以满足 AI 训练中的高带宽需求。
无阻塞设计:无阻塞网络设计的关键是采用 Fat-Tree(胖树)网络架构。交换机下联和上联带宽采用 1:1 无收敛设计,即如果下联有 20 个 200Gbps 的端口,那么上联也有 20 个 200Gbps 的端口。此外交换机要采用无阻塞转发的数据中心级交换机。当前市场上主流的数据中心交换机一般都能提供全端口无阻塞的转发能力。
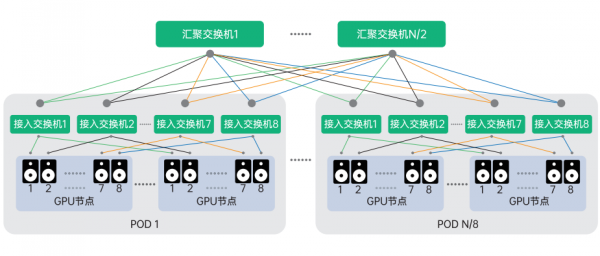
低延时设计AI-Pool:当前用于 AI 大模型训练的集群通常会采用支持 NVLink+NVSwitch 的 GPU 机型,这样节点内不同编号的 GPU 间可借助 NCCL 通信库中的 RailLocal 技术,可以充分利用主机内 GPU 间的 NVSwitch 的带宽,基于此我们可以优化网络架构,将 8 个节点和 8 个接入交换机作为一组,构成 AI-pool,如此同一个组内不同节点的同编号GPU 之间通讯只需要经过 1 跳就可到达,从而大幅度降低通讯延迟。
智算胖树网络设计
网络可承载的 GPU 卡的规模和所采用交换机的端口密度、网络架构相关。网络的层次多,承载的 GPU 卡的规模会变大,但转发的跳数和时延也会变大,需要结合实际业务情况进行权衡。
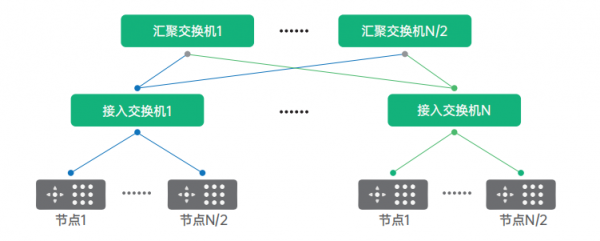
当节点数量超过交换机的端口数时,为了保证节点之间无阻塞通讯,就需要组成胖树架构,两层胖树架构如图所示,图中 N 代表单台交换机的端口数。单台交换机最大可下联和上联的端口为 N/2 个,即单台交换机最多可以下联 N/2 台服务器和 N/2 台交换机。两层胖树网络可以接入 N*N/2 个节点。
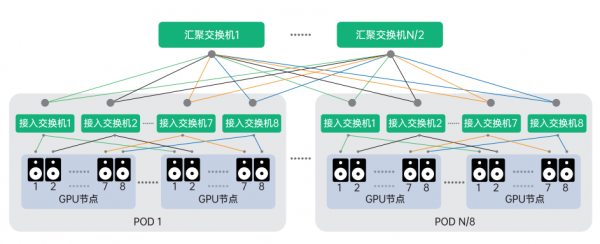
对于采用 8 卡 NVLink+NVSwitch 机型的节点我们可以对二层胖树进行优化,8 个节点为一组采用 AI-pool 的设计模式,如图所示,采用该架构可优化节点间同编号 GPU 的通讯效率,最大可支持 N*N/2 张 GPU 卡互联。
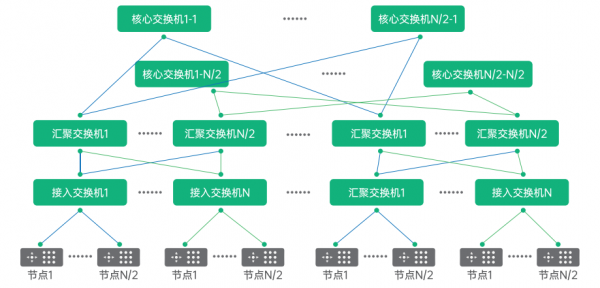
综上,两层胖树和三层胖树最重要的区别是可以容纳的GPU卡的规模不同。以端口数为40的交换机为例,两层胖树架构最大可容纳的GPU卡的数量是800张卡,三层胖树架构最大可容纳的GPU卡的数量是16000张卡。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

华南理工大学与西湖大学联手破解3D场景生成难题:让AI真正“站在你的角度“看世界
CGGS是华南理工大学与西湖大学联合提出的以自我为中心三维场景生成框架,通过一致性增强多视角扩散模型、光流深度估计和互信息几何优化,实现高保真文本驱动3D场景生成。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

南加州大学团队揭示:AI抑郁症检测中藏着一个让准确率虚高23%的“致命漏洞“
南加州大学团队发现语音抑郁检测领域存在数据漏洞,并提出CLeaD跨语言对比对齐框架,揭示模型规模越大跨语言性能越差的反直觉规律。
2024
12/16
19:04
分享
点赞

