
服务器NVMe调优指南:4900万IOPS、340GB/s带宽 (24x SSD)
目录

通过优化 NVMe 驱动器和 AMD EPYC 9005 系列处理器的配置,实现了 4900 万 IOPS 和 340 GB/s 带宽。详细分析了性能优化最佳实践、FIO 基准测试设置及结果,希望能帮助读者在实际系统中实现最佳性能。
本文主要内容翻译自《NVMe(R) Tuning Guide for AMD EPYC(TM) 9005 Series Processors》,原始资料链接见文末。
第一章:引言
1.1 - NVMe
NVMe 是一种用于通过 PCIe 总线访问非易失性存储介质的开放式逻辑设备接口。在本文发布之时,市场上已有一些 PCIe Gen5 NVMe 驱动器,但大多数 NVMe 驱动器的速度为Gen3(8 GT/s)和Gen4(16 GT/s)。第五代(32 GT/s)NVMe 驱动器因更低的I/O开销、更低的延迟以及对多个长命令队列的支持而提升了性能。NVMe 驱动器的优势如下:
-
性能:减少延迟,增加顺序访问的带宽以及随机访问的IOPS。
-
高密度:可在 PCIe Switch后配置多个 NVMe 驱动器。
-
速度:可使用 PCIe Gen3(8 GT/s)、PCIe Gen4(16 GT/s)或 PCIe Gen5(32 GT/s)的 NVMe 驱动器。
-
以下性能指标对 NVMe 驱动器十分重要:
-
每秒处理的 IOPS 数:通常以 4 KB 的块大小来衡量。
-
吞吐量(以 GB/s为单位):通常以更大的 8 KB、64 KB 和 128 KB 块大小来衡量。
-
NVMe 默认必须处理两种类型的数据:每次读取(IOP)对应一个完成信号和一个中断,并且按顺序处理。
每个 PCIe 写入事务的典型最大写入块大小为 256 B。NVMe 读取操作是指向系统内存的 PCIe 写入事务。如今市面上较好的 PCIe Gen5 NVMe 驱动器在采用 PCIe x4 格式时,最多可处理大约 1800 KIOPS 的随机读取。一个 16 通道的 PCIe 端口可以连接四个 x4 NVMe 驱动器,如果驱动器采用 x8 规格,则可连接两个。
- 中断速率可能会因资源消耗而对系统性能产生不利影响。在需要高性能(低延迟或高吞吐量)的情况下,许多系统设计得益于降低中断速率。
- NVMe 事务采用队列深度为 128(在诸如 psync 之类的一些库中这是默认值)进行序列化。这会限制设备和核心的有效使用率,因为它们在等待对方完成处理时处于闲置状态,从而造成人为的瓶颈。
本调优指南通过讨论第五代 AMD EPYC 处理器所提供的 NVMe 子系统的选择及选项,以及各选项的权衡取舍,来帮助您解决这些瓶颈问题。
1.2 - 工作负载概述
FIO 是一种用于对不同类型的I/O进行综合基准测试的工具。FIO 支持许多I/O引擎,例如sync、mmap、libaio、posixaio、SG v3、splice、null、network、syslet、guasi、solarisaio等,支持多线程任务、带宽限制以及指定I/O优先级的功能。它支持典型的工作负载类型,如顺序读取、顺序写入、随机读取和随机写入。顺序操作衡量带宽,随机操作衡量每秒输入 / 输出操作次数(IOPS)。如需更多信息,请参阅FIO文档(https://buildmedia.readthedocs.org/media/pdf/fio/latest/fio.pdf)。
FIO 基准测试使用顺序访问来衡量以 KBps 为单位的带宽吞吐量性能,并使用IOPS 来衡量随机访问I/O性能。与 NVMe 设备规格中公布的最大吞吐量相比,使用随机读取和写入操作能让 FIO 避开内置的预取逻辑,从而对设备延迟提供更贴合实际的测量结果。伪随机线性反馈移位寄存器(LFSR)引擎用于生成均匀随机分布。随机工作负载使用 4 KB 的块大小,而顺序工作负载使用 128 KB 的块大小。numactl是可选的,因为 FIO 已经有 “--cpus_allowed”参数可将线程绑定到逻辑核心上。
PCIe 协议是另一个可能影响 NVMe 性能的因素。PCIe 通道数量会限制进行顺序读写时的最大理论带宽,并且通常与供应商在 NVMe 驱动器规格中所报告的最大带宽一致。表 1-1 展示了 PCIe 单向最大理论带宽。

表 1-1:PCIe 单向最大理论带宽
本调优指南针对配备最新 BIOS 引导程序、采用 AMD EPYC 9005 系列处理器的单插槽或双插槽系统。这些系统应包含一个或多个未挂载为活动目录的 PCIe Gen3、Gen4或Gen5 NVMe 设备。为保持一致性,请将最新的 FIO 构建为静态二进制文件,首选 PCIe 第五代 NVMe 设备。
1.3 - 重点阅读
请务必阅读以下指南(可从 AMD 文档中心获取 https://www.amd.com/en/search/documentation/hub.html),这些指南包含了有关第五代 AMD EPYC 处理器的重要基础信息:
o AMD EPYC(TM) 9005 Processor Architecture Overview
o BIOS & Workload Tuning Guide for AMD EPYC(TM) 9005 Series Processors《AMD EPYC 9005服务器BIOS & 工作负载调优指南》
o Memory Population Guidelines for AMD EPYC(TM) 9005 Series Processors
第二章:性能优化最佳实践
AMD EPYC 9005 系列处理器包含诸如 AMD Infinity Fabric等技术,可解决在使用 NVMe 驱动器时出现的以下瓶颈问题:
- 每秒必须处理的事务数量。
- 每秒必须处理的中断数量。
- 使用队列深度为 1 时固有的事务序列化等待问题。
这些瓶颈在所有系统中都存在,但每个瓶颈出现的具体节点有所不同。
2.1 - 事务数量
AMD EPYC 处理器通常能够在事务准备好处理时同时处理多个并发事务。在使用严格的 PCIe 排序时,较新的已提交写入操作会因较旧的已提交写入操作的发布而被阻塞,即便较新操作与较旧操作之间并无任何依赖关系。严格排序意味着较新的写入操作在较旧的写入操作发布之前无法发布,这意味着无法充分发挥 AMD EPYC 处理器的优势。
2.1.1 - 建议的优化方法
PCIe 允许放松已提交写入操作的顺序。如果较新的已提交写入操作与较旧的已提交写入操作之间没有依赖关系,并且写入的位置不同,那么较新的已提交写入操作可以在较旧的已提交写入操作之前或与其同时发布。这使得在任何给定时间都能够处理多个事务。
NVMe 事务包含两种不同的已提交写入操作:数据事务和完成事务。AMD 建议使用多个 NVMe 驱动器,而不是相对于先前写入操作放松完成事务的顺序,因为这可能会破坏生产者 - 消费者模型。
2.2 - 待处理的中断数量
第五代 AMD EPYC 处理器提供了一个集中式中断和异常处理单元,该单元可减少路由开销并有助于扩展,从而在核心数量较多时为处理能力带来显著优势。AMD Infinity Fabric 旨在向处理程序每秒提供多达 150 万个中断,且不会影响性能。将中断数量保持在此阈值以下可显著提升性能。
以下参数在优化中断处理方面可发挥重要作用:
- NVMe feature ID 设置。
- 更高的核心数量。
- 轮询模式(Polling mode)。
2.2.1 - NVMe Feature ID 设置
设备会发出中断以指示任务已完成。默认情况下,NVMe 控制器会为从队列中处理的每个命令发出一个完成信号。
NVMe 控制器可设置为在发出单个完成信号及相应中断之前,指定可合并的完成信号数量。进行此操作时,请务必设置不少于 100 μs 的超时时间,以防完成信号无法合并。例如,在处理 10 个任务后发出一个完成信号,可使用以下命令:
nvme set-feature /dev/nvme0n1<磁盘地址> --feature-id 8 –value 522
注意:必须对每个 NVMe 设备都执行此操作。
在流量较低的情况下,NVMe feature-ID 设置存在一些缺点。例如,使用队列深度为 1 意味着设备不会有 10 个完成信号可合并,并且会等待 100 ms 的超时时间,这会降低性能。AMD 建议在使用此优化方法时将队列深度至少设置为 16。
2.2.2 - 更高的核心数量
增加可处理由计划任务或线程数量所控制的事务的处理器核心数量,是中断处理的另一项推荐优化方法。AMD 建议每个 NVMe 驱动器使用四到八个核心。将核心、内存和设备置于同一插槽可提升性能。以下是将核心、内存和设备分配到同一插槽的示例:
numactl --membind=1 --cpunodebind=0-3 --numjobs=1 --iodepth=64 --group_reporting --runtime=600
2.2.3 - Polling Mode
一些较新的 NVMe 驱动器支持使用轮询模式,在这种模式下,内核驱动程序会轮询完成队列,而不是等待中断来处理它们。如果设备驱动程序支持轮询模式,那么 NVMe 完成操作可以基于轮询而非基于中断。如果内核支持,您可以为每个队列指定连续、自适应混合或固定时间混合轮询,以便在该队列的延迟、吞吐量和 CPU 使用率之间实现平衡。轮询(即使是混合轮询)比中断会占用稍多的 CPU 资源。要在内核中设置轮询模式,可使用以下命令:
echo 1 > /sys/block/<nvmedevice>/<queue>/io_poll
要设置不同的轮询参数:
- 连续轮询:
echo -1 > /sys/block/<nvmedevice>/<queue>/io_poll_delay - 自适应混合轮询:
echo 0 > /sys/block/<nvmedevice>/<queue>/io_poll_delay - 固定时间混合轮询:
echo <x ns> > /sys/block/<nvmedevice>/<queue>/io_poll_delay
2.3 - NPS
AMD 建议在 BIOS 中将L3 Cache as NUMA选项启用,并将NPS设置为 1。
第三章:FIO 性能基准测试设置
本章介绍了用于本调优指南的被测系统(SUT)详细信息、测试方法以及平台配置。被测系统针对连接到由 128 核(256 线程)AMD 9005 系列处理器驱动的双插槽系统的 NVMe 驱动器执行I/O性能测试。基于 Linux 的 FIO 工具在不同配置下被用于执行和分析这些性能测试。
3.1 - 被测系统配置
表 3-1 展示了用于测试 24 个 x4 系列 NVMe 固态硬盘(SSD)性能的被测系统配置。
|
组件 |
详情 |
|
操作系统 |
Ubuntu 22.04 |
|
Node per Socket(NPS) |
1 |
|
处理器 |
2 个 128 核的第五代 AMD EPYC |
|
核心 |
每个 CPU 128 个 |
|
线程 |
每个 CPU 256 个(启用同步多线程技术,SMT 打开时) |
|
SSD驱动器 |
最多 24 个 NVMe PCIe Gen5。 |
|
FIO 版本 |
3.28 |
表 3-1:被测系统配置
3.2 - FIO 基准测试安装及调优注意事项
大多数 Linux 发行版都包含预编译的 FIO 软件包,这意味着在测试前您无需下载并编译源代码。然而,AMD 为了在各被测系统间保持功能的一致性和完整性,使用了静态构建的 FIO 版本。
要在基于 Ubuntu 22.04 的发行版上安装系统自带的预编译 FIO(版本 3.28,注:可能已有更新版本),可使用以下命令:
# sudo apt install fio
要在基于 RHEL8/CentOS8 的发行版上安装系统自带的预编译FIO(版本 3.7),请使用以下命令:
# sudo dnf install fio
要在 Ubuntu 22.04 系统上静态下载并构建最新的 FIO,可按以下步骤操作:
# sudo apt install libaio-dev libbsd-dev di valgrind libtcmalloc-minimal4 libcunit1 libcunit1-dev libgfapi0 libiscsi-dev nvme-cli numactl
# git clone https://github.com/axboe/fio
# cd fio
# git checkout fio-3.28(或酌情用更新版本替代)
# ./configure --build-static --enable-lex
# make
# sudo make install
注意事项:
- AMD 推荐使用 FIO 版本 3.16 或更高版本,因为 FIO 3.7 版本不支持 “--cpus_allowed” 参数。
- 这些测试使用的是 “fio-3.28” 这个 FIO tag。
3.2.1 - 擦除(Purging)
擦除操作可将固态硬盘设备恢复到一种状态,使得后续的写入操作尽可能如同设备从未被使用过且不包含任何有效数据时那样执行。要在 Linux 中执行此任务,需安装 nvme-cli 软件包,它提供了基本的 nvme 命令。如果安装了合适的 nvme-cli 软件包,那么可以执行以下命令来安全擦除整个驱动器。例如,要擦除 nvme1n1 驱动器,可使用以下命令:
# nvme format /dev/nvme1n1 --ses=1
(编者注:请注意格式化等操作的风险,被测试的SSD不要包含任何有用的数据。本文后续将不再提示)
默认的 “--ses=0” 选项表示不请求安全擦除操作。
设置 “--ses=1” 会触发安全擦除模式,该模式会擦除用户数据,并可能用0或1替换数据。
设置 “--ses=2” 会执行速度较慢但更安全的加密用户数据擦除操作,然后删除加密密钥。
以下是一个使用 “--ses=1”擦除后的驱动器示例:
# hexdump -n 16 /dev/nvme1n1
0000000 0000 0000 0000 0000 0000 0000 0000 0000
0000010...
请务必在安全擦除后对驱动器进行预处理。这是因为 AMD EPYC 数据架构会对连续的 00h 数据返回进行优化,从而导致吞吐量过高,远超 NVMe 设备规格所规定的值。
3.2.2 - 预处理(Preconditioning)
全新的设备或处于类似状态的设备通常在过渡到与实际工作负载性能相对应的稳定状态之前,会有一段性能提升期。设备必须处于 “稳定状态” 才能进行准确的测量。稳定状态由以 “轮次” 衡量的窗口定义,当测试结果进入并保持稳定状态至少五轮时,即视为达到稳定状态。存储网络行业协会(SNIA)指南规定,当相邻两次运行之间的变化小于 20% 时,即达到稳定状态。《使用 SNIA 固态硬盘性能测试规范理解固态硬盘性能》(https://www.snia.org/sites/default/files/UnderstandingSSDPerformance.Jan12.web_.pdf)解释了固态硬盘预处理的重要性。
对 NVMe 驱动器进行预处理可使其进入稳定状态,因此这是获得可重复且具有代表性的测试结果的最重要要求。按照固态存储(SSS)性能测试规范(PTS)企业版 1.0 (https://www.snia.org/sites/default/files/technical-work/pts/release/SNIA-SSS-PTS-Enterprise-v1.0.pdf)对 NVMe 驱动器进行预处理。有两种可接受的预处理类型:
工作负载相关预处理(WDPC):运行与测试所用相同的工作负载。
工作负载无关预处理(WIPC):使用与测试工作负载无关的工作负载。
AMD 推荐这种方法,即使用顺序 128 KB 块写入两倍用户容量的数据。
以下是一个预处理命令示例:
# dd if=/dev/random of=/dev/nvme1n1 bs=128k status=progress
3.2.3 - NVMe Gen5测试策略
NVMe 的性能与 CPU 核心分配直接相关。有时候,让Linux 内核任务调度器来确定最佳分配方式是最为简便的做法。内存带宽会直接影响 NVMe 第五代驱动器的最大IOPS以及性能。AMD 建议填满所有内存通道以实现最大带宽。此外,物理CPU 核心能够处理的 IOPS 比其同步多线程(SMT)伙伴核心更多。
本调优指南中所述的测试是按照第 2 页的 “工作负载概述”来执行的。
3.3 - 测试方法
测试是依照第2 页的 “工作负载概述”来进行的。
3.4 - 核心 / CCD绑定与操作系统任务调度器
NVMe 性能与 CPU 核心分配直接相关。Linux 内核任务调度器会确定最佳分配方式,但 AMD 的测试中很少看到超过 5% 的性能提升。一些测试表明,当绑定到CCD或 CPU 核心时,性能会下降 5%。您还应该考虑物理核心与SMT核心的相对能力,因为物理核心能够处理的 IOPS 比其SMT核心更多。
3.5 - 内存带宽
当接近PCIe 带宽限制时,要留意内存带宽限制情况。AMD 建议填满所有内存通道以获取最大内存带宽。
3.6 - 中断合并
中断合并能够降低CPU 的中断开销。请参阅《NVM Express(R) 基础规范》(https://nvmexpress.org/wp-content/uploads/NVM-Express-Base-Specification-2.0b-2021.12.18-Ratified.pdf)的第 5.27.1.6 节内容。
3.7 - 并发任务数量(numjobs)
为了在PCIe Gen5 U.2 “供应商 A” 驱动器上实现最大 IOPS,必须对 FIO 应用程序进行配置,使其使用多个Zen 5 核心。
3.8 - 硬件同步多线程(SMT)感知
要特别留意SMT和非一致性内存访问(NUMA)设置。每个NVMe PCIe 设备都与一个NUMA节点相关联,在 BIOS 中将节点NPS设置为 4,并将ACPI SRAT L3 Cache As NUMA Domain设置为启用状态后,就能显示出这些关联关系。将FIO 进程绑定到错误的核心或NUMA Node上,可能会导致无法实现最大IOPS或带宽。
AMD EPYC Zen 5 CPU 缓存架构允许每个核心访问其自身的一级(L1)和二级(L2)缓存。每个核心复合体芯片(CCD)包含 8 个核心,这 8 个核心(以及它们的SMT伙伴核心)共享同一个三级(L3)缓存的访问权限。
lstopo是一个Linux 实用工具,它能够帮助我们了解 CPU 核心和SMT兄弟核心,以及主机系统缓存架构的相关情况,例如:
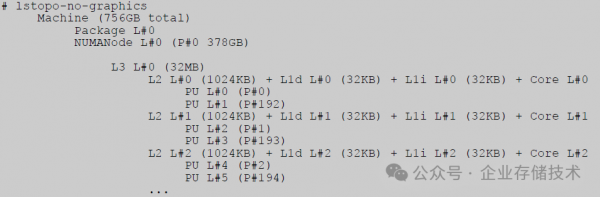
这个示例表明,核心 P0 和核心 P192 是SMT兄弟核心,它们与核心 P1 和 P193 等共享相同的L3 Cache line,依此类推。
3.9 - 非一致性内存访问(NUMA)感知
由于已将L3 as NUMA打开,且每个CCD都有自己的 L3 Cache,所以 “lscpu” 命令可以帮助您确定NUMA节点 6 的 CPU 核心范围:48 - 55、176 - 183。即便将 BIOS 配置恢复到默认的NPS 1 且禁用L3 Cache As NUMA,这种映射关系也不会改变,不过NUMA节点的数量会发生变化。
运行单核单线程测试(1C1T)时,使用本地 CPU 逻辑核心 48。对于单核双线程测试(1C2T),则要添加 CPU 逻辑核心 48 的兄弟(SMT)线程。这种 CPU 兄弟核心对的数量因处理器型号而异。执行以下命令可确定CPU 逻辑核心 48 的兄弟核心:
# cat /sys/devices/system/cpu/cpu48/topology/thread_siblings_list
对于启用了同步多线程(SMT)、总共 64 个核心的单处理器,此命令应返回 48,112。在这个示例中,在进行1C2T 测试时,要将 CPU 逻辑核心 112 与CPU 逻辑核心 48 一起使用。对于启用了SMT、总共 128 个核心的双处理器系统,此命令应返回 48,176。在此情况下,在进行 1C2T 测试时,要使用 CPU 逻辑核心 176 与 CPU 逻辑核心48,而不是 112。
一个复合的企业工作负载应该包含不同的profile,以反映现实世界中的任务情况。如上文所述,I/O存储性能测试包含 1C1T 和 1C2T 测试,这有助于您确定启用了SMT的核心的最大IOPS能力。
使用以下方式测试NVMe的最大性能:
采用单核单线程(1C1T)和单核双线程(1C2T),I/O深度为 32,进行 128 KB 顺序访问测试。
采用单核单线程(1C1T)和单核双线程(1C2T),I/O深度为 32,进行 4 KB 随机访问测试。
对于 1C2T 测试,您可以选择一起执行以下命令:
numactl --physcpubind 48,176
fio --cpus_allowed 48,176
这种映射关系取决于 NVMe 设备的物理 PCIe 插槽位置以及 AMD EPYC CPU 型号,而不取决于NPS或L3 Cache As NUMA的 BIOS 设置。
要一般性地运行这些测试,可按以下步骤操作:
1.通过执行 “lsblk -p” 命令来验证 NVMe 设备是否已正确配置。
2.通过执行以下命令来确定目标 NVMe 设备的 PCIe bus:device.funtion三元组:
lspci -D | grep NVMe
3.通过执行以下命令来确定 NVMe 设备实际所在的本地NUMA节点:
lspci -vvv -s <PCIe bus:device.funtion>
4.与步骤 3 类似,您也可以选择执行以下命令来确定NUMA节点(假设 PCIe 域为 0000):
# cat /sys/bus/pci/devices/0000:bus:device.function/numa_node
其中,“bus:device.function”是从步骤 2 中的 “lspci” 命令获取的 PCI 三元组,该命令返回的值就是目标 NVMe 设备的物理或本地NUMA节点。
3.10 - 首选I/O和宽松排序
第三代及之前的 AMD EPYC 处理器包含首选输入 / 输出(Preferred I/O)和宽松排序(Relaxed Ordering)设置,这些设置有助于优化网络和磁盘I/O性能。第五代 AMD EPYC 处理器(9xx4 型号)及更新型号包含了架构增强功能,默认情况下就能提供最优的网络和磁盘I/O性能,无需使用上述任何一种功能特性。
第四章:FIO 性能基准测试结果
本章展示了使用 FIO 3.28 在配备 Ubuntu 22.04 系统、搭载 24 个三星 PM1743 NVMe 驱动器(容量为 1.92 TB)的双插槽第五代 AMD EPYC 客户参考板(CRB)上收集的示例性能数据,该参考板的 BIOS 版本为 RVOT0081。这些图表仅用于说明目的,并不旨在宣称或保证任何级别的性能表现。
制造商规格中列出了示例驱动器的带宽性能:对于 128 KB 顺序读取,带宽能力为 12,000 MB/s;对于 4 KB 随机读取,每秒IOPS为 1500K。这款 NVMe 驱动器专为读密集型工作负载而设计,其写入性能未进行优化,且可能会有所变化。规格中列出的可持续 128 KB 顺序写入带宽为 2500 MB/s,可持续的 4 KB 随机写入性能为 5 万 IOPS。不过,4 KB 随机写入的峰值性能可能高达 110K IOPS。
唐僧_huangliang注:本指南中列出的以上数值,比当前三星官网查到的PM1743性能指标偏低一些,可能是SSD有过优化提高。建议大家参考下面图表,有助于更好地理解后续测试结果:
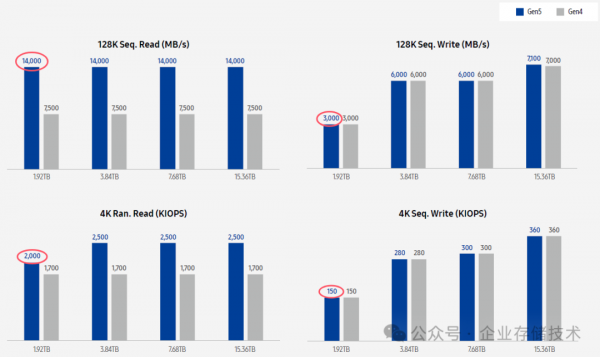
上图截自《Samsung SSD PM1743 White Paper》,这里显示PCIe Gen5下的顺序读写带宽为14,000MB/s和3,000MB/s,随机读写IOPS为200万和15万。
全部 24 个驱动器都实现了供应商规格数据表中所规定的线性性能扩展。除了 4 KB 随机写入之外,各次运行之间的差异通常较小。这属于正常情况,因为由于 NAND 闪存芯片的固有局限性,NVMe 驱动器必须进行磨损均衡、垃圾回收以及其他后台任务。
本章所展示的性能结果仅用于说明目的,不构成任何声明。您实际获得的性能可能与所展示的结果存在较大差异。
4.1 - 128 核系统
本节描述了使用表 3-1 中所述的 128 核被测系统(SUT)开展测试的情况以及所获得的相关结果。
4.1.1 - 单线程测试结果
4.1.1.1 - 以最大 IOPS 进行随机读写
随机写入测试与随机读取测试非常相似,只不过将 “--rw”选项更改为 “randwrite”。由于 NVMe 驱动器具有磨损均衡和垃圾回收等特性,预计随机写入测试的变化幅度会比随机读取测试更大。本节以单个设备 “/dev/nvme0n1”为例进行说明。
以下示例命令使用一个NVMe 驱动器,通过 4 KB 随机读取(“–rw randread”)来测量IOPS性能。本示例将 “/dev/nvme0n1” 作为目标NVMe 驱动器,并使用位于 “/bench/fio”的静态二进制 FIO 文件。测试目标是针对此工作负载一般执行情况下NVMe 供应商所规定的最大读取 IOPS。
4.1.1.2 - 运行随机读取至最大 IOPS 测试
随机读取的FIO 测试命令如下:
./fio --description 'FIO Random ReadMaxIOPS Test' --rw randread --thread --size 100% --direct 1 –buffered 0 -iodepth 128 --output-format json --invalidate 1 --bs 4096 --ioengine libaio --time_based –-norandommap --random_generator=lfsr --cpus_allowed_policy=split --exitall --group_reporting –ramp_time 10 --runtime 60 -allrandrepeat 0 -name=”nvme0n1” --numjobs=16 -filename /dev/nvme0n1
若要同时对更多驱动器执行测试,可添加额外的 “--name="disk_nvmeXn1" --numjobs=1 --filename /dev/nvmeXn1” 参数,如下所示:
./fio --description 'FIO Random ReadMaxIOPS Test' --rw randread --thread --size 100% --direct 1 –buffered 0 -iodepth 128 --output-format json --invalidate 1 --bs 4096 --ioengine libaio --time_based –norandommap --random_generator=lfsr --cpus_allowed_policy=split --exitall --group_reporting --ramp_time 10 –runtime 60 --allrandrepeat 0 \
--name="disk_nvme0n1" --numjobs=1 --filename /dev/nvme0n1 \
--name="disk_nvme1n1" --numjobs=1 --filename /dev/nvme1n1 …
这两个示例中使用的 “numjobs”值为 1。这意味着针对每个要执行 FIO 测试的驱动器,FIO 进程仅使用一个线程来执行操作。在某些特定场景下,“--numjobs=1”就足够了。
然而,对于较新的NVMe目标设备来说,仅使用一个 CPU 线程可能无法充分发挥其性能。因此,您可能需要修改 “--numjobs=X”参数,使其包含四到八个 CPU 线程。以下示例展示了使用四个 CPU 线程来执行测试的情况:
./fio --description 'FIO Random ReadMaxIOPS Test' --rw randread --thread --size 100% --direct 1 –buffered 0 -iodepth 128 --output-format json --invalidate 1 --bs 4096 --ioengine libaio --time_based –norandommap --random_generator=lfsr --cpus_allowed_policy=split --exitall --group_reporting --ramp_time 10 –runtime 60 --allrandrepeat 0 \
--name="disk_nvme0n1" --numjobs=4 --filename /dev/nvme0n1 \
--name="disk_nvme1n1" --numjobs=4 --filename /dev/nvme1n1
通过添加 --cpu-allowed '0-7' 参数,就可以指定 FIO 线程和任务数量(numjob)所绑定的具体 CPU / 核心,如下所示:
./fio --description 'FIO Random ReadMaxIOPS Test' --rw randread --thread --size 100% --direct 1 –buffered 0 --iodepth 128 --output-format json --invalidate 1 --bs 4096 --ioengine libaio --time_based –norandommap --random_generator=lfsr --cpus_allowed_policy=split --exitall --group_reporting --ramp_time 10 –runtime 60 --numjobs=4 --allrandrepeat 0 \
--name="disk_nvme0n1" --cpus_allowed "0-3" --filename /dev/nvme0n1 \
--name="disk_nvme1n1" --cpus_allowed "4-7" --filename /dev/nvme1n1
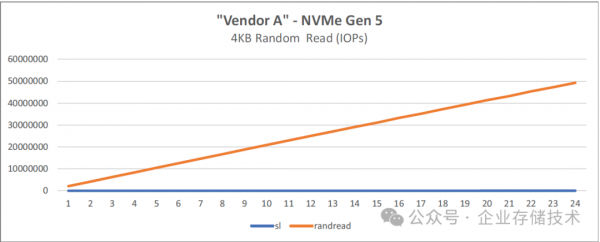
图 4-1:基于 128 核的第五代 AMD EPYC 处理器的 FIO 4 KB 随机读取
唐僧_huangliang注:上面图表中蓝色线条“sl“为Slot的缩写,即插入的SSD槽位数。我们看到IOPS性能随盘数提高保持线性提升,24块SSD时接近5000万IOPS(下文中的第五章,会列出具体数值)。
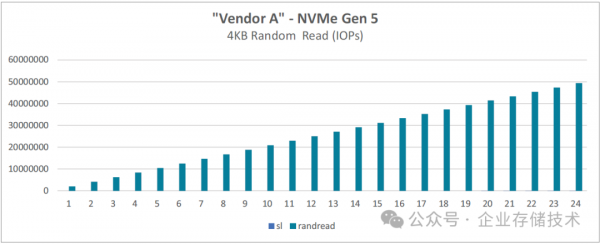
图 4-2:基于 128 核的第五代 AMD EPYC 处理器、采用 8 个线程的 FIO 4 KB 随机读取
上面的文字应该是指:测试中对每个NVMe SSD使用8个线程(CPU核心)。
4.1.1.3 - 运行随机写入至最大 IOPS 测试
FIO 随机写入工作负载会向NVMe端点的随机地址执行写入操作。要实现这一点,只需像如下所示那样编辑-rw randwrite 即可。本次测试的目标是获取一般工作负载下NVMe 供应商所规定的最大写入IOPS。
随机写入的 FIO 测试命令如下:
./fio--description 'FIO Random WriteMaxIOPS Test' --rw randwrite --thread --size 100% --direct 1 –buffered 0 --iodepth 128 --output-format json --invalidate 1 --bs 4096 --ioengine libaio --time_based –norandommap --random_generator=lfsr --cpus_allowed_policy=split --exitall --group_reporting --ramp_time 10 --runtime 60 --numjobs=4 --allrandrepeat 0 \
--name="disk_nvme0n1" --cpu_allowed "0-3"--filename /dev/nvme0n1 \
--name="disk_nvme1n1" --cpu_allowed "4-7" --filename /dev/nvme1n1
为每个额外添加的NVMe驱动器添加额外的命令行,并像随机读取示例那样相应地修改“--cpus_allowed” 参数。
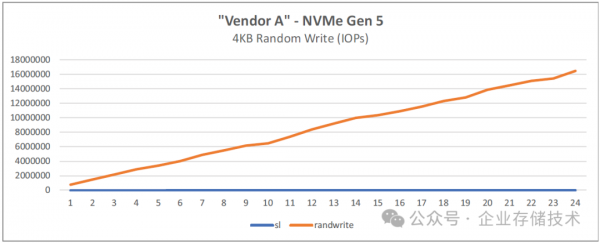
图 4-3:基于 128 核的第五代 AMD EPYC 处理器的 FIO 4KB 随机写入
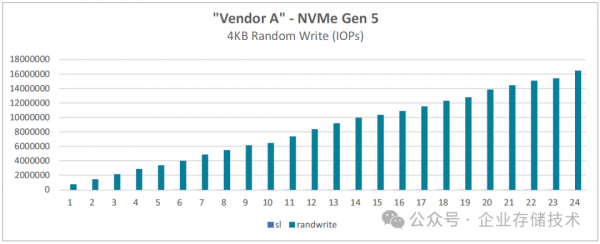
图 4-4:基于 128 核的第五代 AMD EPYC 处理器的 FIO 4KB 随机写入
4.1.1.4 - 以顺序读取进行最大吞吐量测试
以下示例命令使用128 KB 顺序读取来测量最大吞吐量。
注意:顺序读取通常不需要高达 32 的输入 / 输出深度(iodepth),但本示例为了简便起见使用了相同的iodepth。
运行顺序读取至最大 NVMe(PCIe)读取吞吐量测试
顺序读取的FIO 工作负载常被用于对 PCIe 链路进行压力测试或性能检验。AMD Socket SP5 平台采用了 PCIe Gen5规范。顺序读取的 FIO 工作负载以 128 KB 的块大小(--bs 128k)执行,并且使用读取参数(--rw read)来运行。
以下是一个将顺序读取最大化的示例。本次测试的目标是获取此工作负载一般执行情况下 NVMe 供应商所规定的最大读取吞吐量。
顺序读取的FIO 测试命令如下:
./fio --description 'FIO Sequential Read MaxKB Test' --rw read --thread --size 100% --direct 1 --buffered 0 --iodepth 128 --output-format json --invalidate 1 --bs 128k --ioengine libaio --time_based --norandommap --random_generator=lfsr --cpus_allowed_policy=split --exitall --group_reporting --ramp_time 10 --runtime 60 --allrandrepeat 0 \
--name="disk_nvme0n1" --numjobs=1 --filename /dev/nvme0n1 \
--name="disk_nvme1n1" --numjobs=1 --filename /dev/nvme1n1 ...
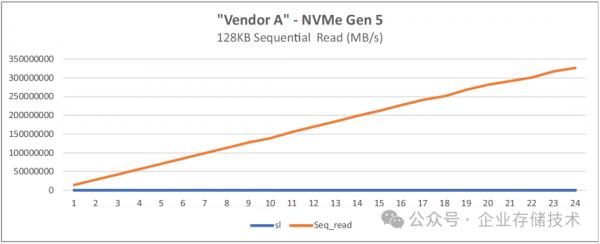
图 4-5:基于 128 核的第五代 AMD EPYC 处理器的 FIO 128KB 顺序读取
唐僧_huangliang注:达到24块SSD时,这里显示顺序读带宽达到300GB/s以上。
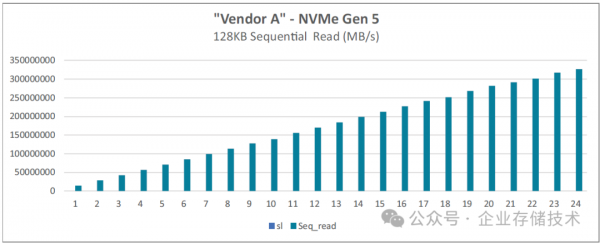
图 4-6:基于 128 核的第五代 AMD EPYC 处理器的 FIO 128KB 顺序读取
4.1.1.5 - 以顺序写入进行最大吞吐量测试
顺序写入的FIO 工作负载通常用于对 PCIe 链路进行压力测试或性能检验。AMD Socket SP5 平台采用了 PCIe Gen5规范。顺序读取的 FIO 工作负载是以 128 KB 的块大小(--bs 128k)来执行,并且是通过写入参数(--rw write)来运行的。
以下是一个将顺序写入最大化的示例。对于此工作负载的常规执行情况而言,测试目标是获取 NVMe 供应商所规定的最大写入吞吐量。
顺序写入的FIO 测试命令如下:
./fio --description 'FIO Sequential Write MaxKB Test' --rw write --thread --size 100% --direct 1 –buffered 0 --iodepth 128 --output-format json --invalidate 1 --bs 128k --ioengine libaio --time_based –norandommap --random_generator=lfsr --cpus_allowed_policy=split --exitall --group_reporting --ramp_time 10 --runtime 60 --allrandrepeat 0 \
--name="disk_nvme0n1" --numjobs=1 --filename /dev/nvme0n1 \
--name="disk_nvme1n1" --numjobs=1 --filename /dev/nvme1n1 ...
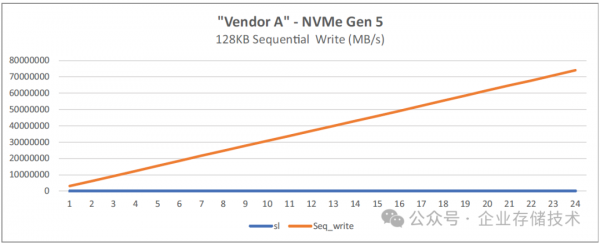
图 4-7:基于 128 核的第五代 AMD EPYC 处理器的 FIO 128KB 顺序写入
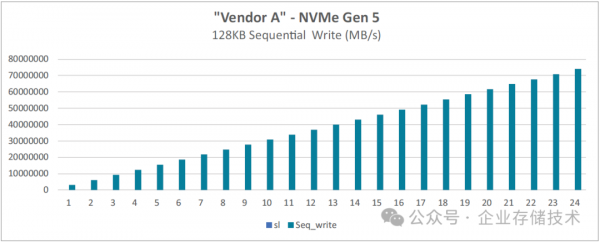
图 4-8:基于 128 核的第五代 AMD EPYC 处理器的 FIO 128KB 顺序写入
4.1.2 - 扩展到 24 个 NVMe 驱动器
当扩展到24 个驱动器时,在 18 个驱动器和 22 个驱动器处会出现性能下降(瓶颈),因为每个 P 和 G Link同时运行时能够提供 70 GB/s 的单向带宽(注:CPU架构可参考《AMD EPYC 9005 (Zen 5&5c) 服务器CPU架构解读》)。在扩展测试过程中一定要注意驱动器的顺序,因为如果 P 和 G 在同一个NBIO上,将会有并发的 PCIe bus number,并且会按顺序枚举,而当 P 和 G Link同时受到压力时会遇到性能瓶颈。
始终要指定驱动器最接近的NUMA节点。例如,连接到CPU0 的驱动器使用NUMA Node 0,连接到 CPU1 的驱动器使用NUMA Node 1。
第五章:测试结果
5.1 - 128 核系统
本节展示了使用表3-1 中所述的 128 核被测系统(SUT)所获得的测试结果数值。
5.1.1 - 随机读取扩展性测试
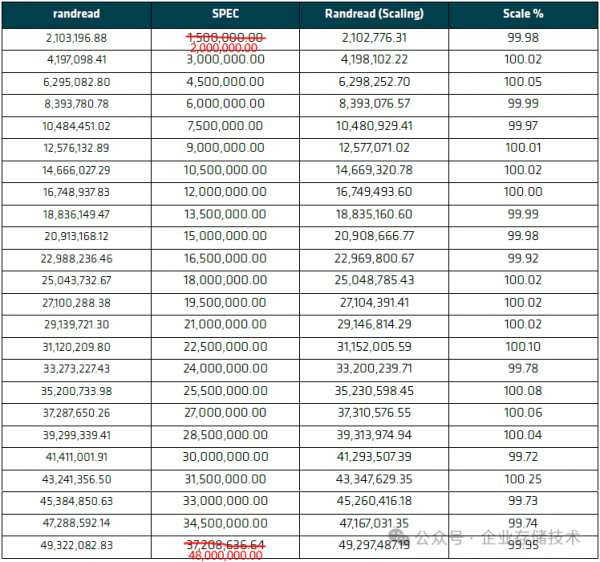
表 5-1:随机读取扩展性测试结果(左起第2列的SPEC参考数值,从上到下可以按照2,000,000.00的倍数来脑补一下)
唐僧_huangliang注:前文中我提到过,三星PM1743 1.92TB SSD的随机读IOPS官方参考值为200万IOPS(这里单盘实测偏高一点),24块盘测出来总共49xx万IOPS达到了理想的线性扩展。
5.1.2 - 随机写入扩展性测试
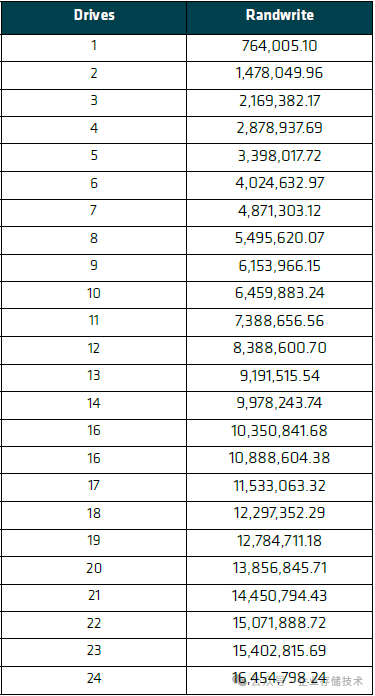
表 5-2:随机写入扩展性测试结果
PM1743单盘测出随机写76万IOPS,这应该是因为测试时间只有60秒,SSD还没有达到稳态。本文的测试目的,是观察服务器CPU处理能力和I/O带宽发挥,SSD跑得“虚高”并不是坏事。
24块盘随机写IOPS总共达到1654万,基本上也是线性扩展的。(每块SSD写IOPS之间的偏差值,本身就会大一点)
5.1.3 - 顺序读取扩展性测试 340,433,064.76(单位KB/s)
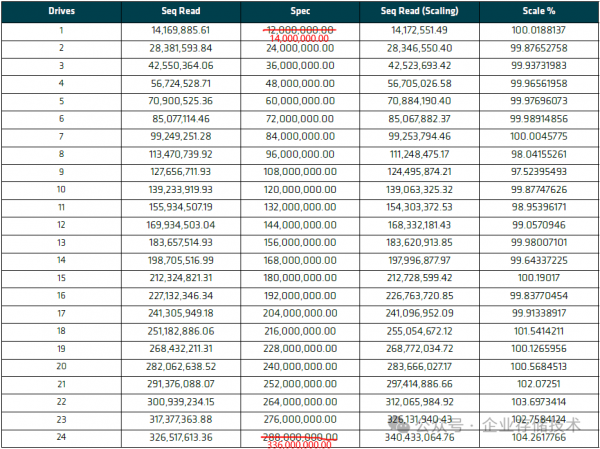
表 5-3:顺序读取扩展性测试结果(左起第3列的SPEC参考数值,从上到下可以按照14,000,000.00的倍数来脑补一下)
如果按照PM1743单盘14,000MB/s顺序读带宽来计算,24块盘理论上能跑到336GB/s(这里按照1GB=1,000MB/s来计算,以此类推)。实测数值达到326-340GB/s这一水平,应该也是很理想了。
5.1.4 - 顺序写入扩展性测试
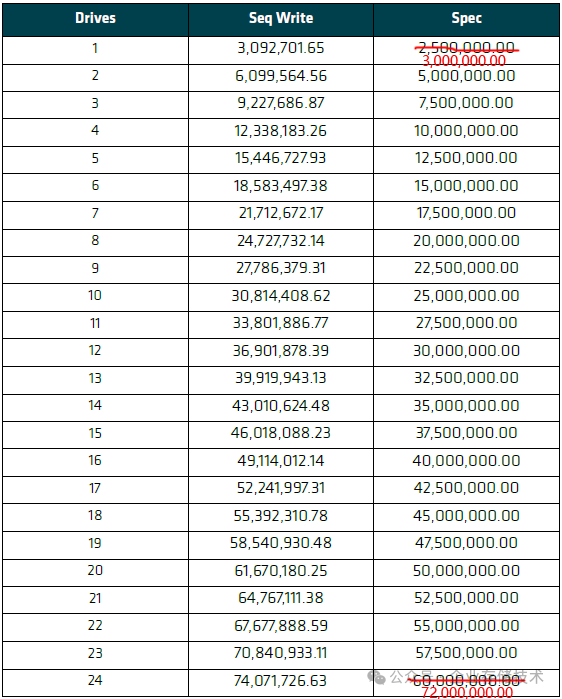
表 5-3:顺序写入扩展性测试结果(右边一列的SPEC参考数值,从上到下可以按照3,000,000.00的倍数来脑补一下)
PM1743单盘顺序读带宽规格为3,000MB/s,24块盘理论上能跑到72GB/s(这里按照1GB=1,000MB/s来计算,以此类推)。由于单盘的实测数值偏高一点,所以24块SSD顺序写合计达到了74GB/s。

参考资料 https://www.amd.com/content/dam/amd/en/documents/epyc-technical-docs/tuning-guides/58465_amd-epyc-9005-tg-nvme.pdf
扩展阅读:《企业存储技术》文章分类索引更新(微信公众号合集标签)
注:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
好文章,需要你的鼓励


Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

LMMs-Lab与NTU MMLab联手微软:让AI智能体“一句话自我进化“的秘密
SkillOpt-Lite通过将智能体技能优化形式化为零阶优化问题,提出极简流水线:把执行轨迹存为文本文件,让AI直接用文件系统工具翻日志、找规律、改技能,配合独立验证门控,比复杂的多智能体优化框架跑得更快效果更好,并自然延伸至执行框架自动优化(HarnessOpt),使轻量模型能够超越大模型。

Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber周三发布了一款基于现代Ioniq 5改装的数据采集原型车,搭载14个摄像头、8个固态激光雷达和9个雷达,通过英伟达双驱Thor计算机处理数据。Uber计划今年在全球部署500辆此类车辆,每月可采集200万英里高保真驾驶数据,供Avride、Waymo、WeRide等30余家自动驾驶合作伙伴使用。这是Uber自2020年出售自动驾驶部门以来首次自主组装车辆,也是其AV Labs部门的重要进展。

NVIDIA推出“三模式“AI语言大脑:一个模型同时兼顾速度与准确,彻底打破现有推理瓶颈
英伟达推出Nemotron-Labs-Diffusion三模式语言模型,将逐字生成、并行扩散与自猜自验融于一体,单用户吞吐量最高达Qwen3-8B的4倍,同时保持相近准确率。

