
MLPerf Llama大模型推理测试:一款GPU独战NVIDIA群雄
目录
- ML Commons的MLPerf基准测试:Llama-2-70b
- 8x GPU:MI300X与H100-SXM旗鼓相当
- 多GPU线性扩展评估、B100单卡表现优异
- Tensor并行多卡NVLINK vs. PCIe效率
- 选型参考:显存带宽是Token/s输出唯一决定因素吗?
- 硬件参数、卡间互连与软件发挥

ML Commons的MLPerf基准测试:Llama-2-70b
最近看到国外网站讨论NVIDIA和AMD数据中心GPU的实际性能,我也想给大家分享点测试对比信息——来自第三方联盟组织ML Commons推出的MLPerf Inference: Datacenter基准测试。

ML Commons有点像AI行业的spec.org。上图为组织的发起人成员,我看到除了Intel、AMD、NVIDIA等国外巨头之外,也包含有国内的公司阿里巴巴、华为、浪潮、宁畅、OPPO。显然,大家应该都是不希望在业内公认的基准测试中掉队,特别是AI这个如今火热的领域。

上图是更多成员,我又看到了H3C、联想,以及几大服务器ODM厂商。包含的成员覆盖全面,通常推出的测试程序标准就比较公平,网站上公布的测试结果用来横向对比的参考价值也比较大。
本次解读MLPerf BenchMark中的项目,是使用Llama-2-70b大语言模型进行的推理测试。如下图:在最新的v4.1版本已公布结果中,只有除了各种型号的NVIDIA GPU之外,只有一款AMD Instinct MI300X。严格地说,在较早的v4.0测试中出现了Intel Gaudi 2的身影,但其性能水平应该与最新的Gaudi 3有些差距。所以本文不想引入更多分支剧情,专注于当前的MLPerf Inference: Datacenter v4.1。
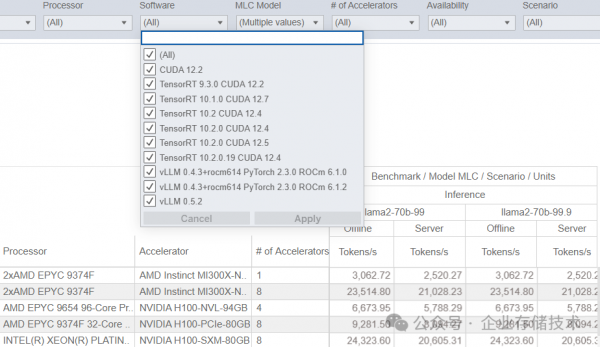
本文测试数据引用自https://mlcommons.org/benchmarks/inference-datacenter,上面只是部分截图。
与大模型推理测试结果直接相关的,就是GPU的型号和数量。除此之外,我们还能看到更多信息,比如使用的服务器型号、CPU,以及软件平台环境等。参考上面截图,实际上NVIDIA GPU在Llama-2-70b测试中基本都是用CUDA+TensorRT;而AMD则是ROCm+PyTorch+vLLM。PYTorch的流行度不用我说了吧,TensorRT可以理解为NVIDIA进一步加速的框架;vLLM如今的评价也是挺高的。
上图中的测试结果处,可以看到llama2-70b-99和llama2-70b-99.9两栏,而它们之间的Tokens/s数值又完全相同。我觉得这是一个有点容易让人混淆之处,具体区别指的什么呢?
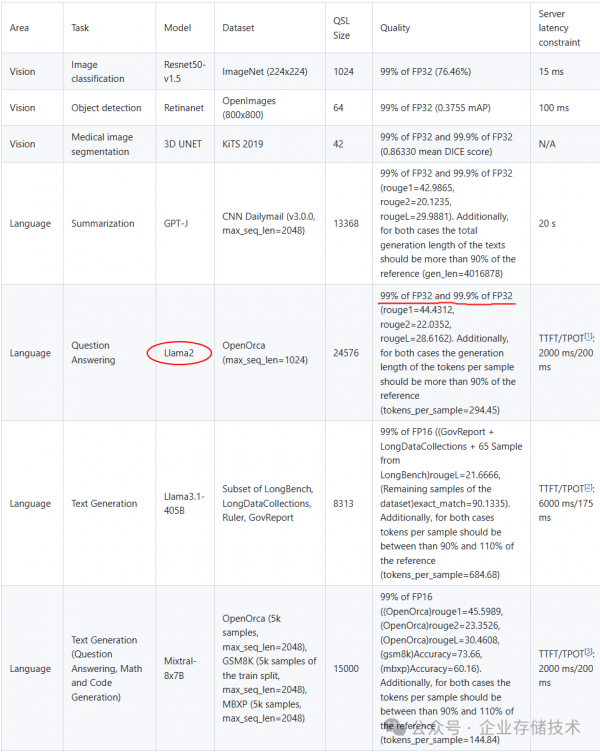
参考上面图表,Llama2测试中的99%和99.9%似乎指的是FP32所占的比重?但事实上推理计算通常不需要这么高精度的模型——另外载入显存的数据量也太大了。下表只是个简单的参考,KV Cache部分与上下文长度相关,就不展开讨论了。
|
70b模型推理 |
模型占用显存 |
KV Cache… |
|
8bit |
约70GB |
|
|
16bit |
约140GB |
|
|
32bit |
约280GB |
MLPerf Llama-2-70b推理测试实际上是用的FP8量化模型,下文中有我发现的证据。
在MLPerf Llama-2-70b推理测试结果中还分为Offline和Server两项,参考介绍如下:
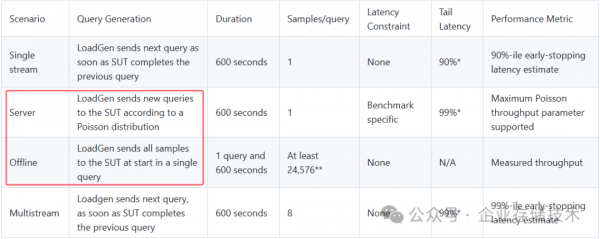
Server:LoadGen 在启动时会在单个查询中将所有样本发送到被测系统(SUT)。
Offline:一旦被测系统(SUT)完成上一个查询,Loadgen 就会发送下一个查询。
可以理解为Server是模拟服务器在响应查询请求,而Offline则是离线生成最大的压力,应该能把GPU跑得更满一点吧。
8x GPU:AMD MI300X与NVIDIA H100-SXM旗鼓相当
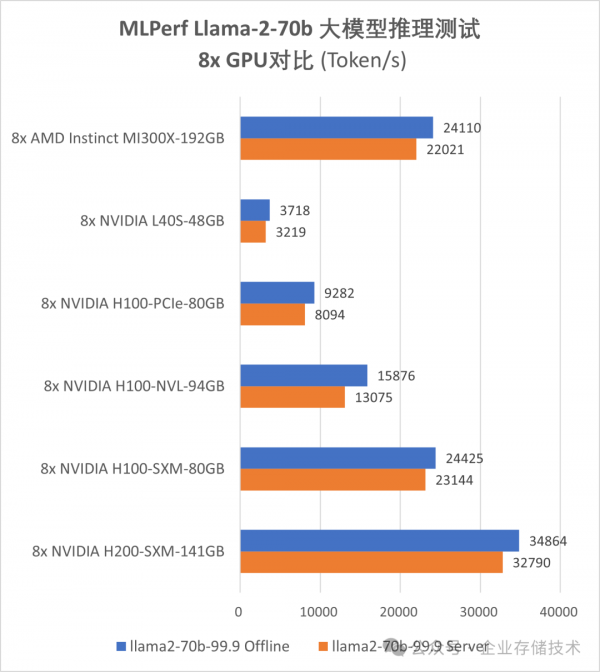
首先我特别挑选出8x GPU(单机8卡)的测试结果,对于相同GPU型号和数量的多个测试结果,挑成绩最高的进行对比。另外对于70b这种尺寸的模型和数据中心GPU配置,单节点服务器就能容纳全部推理数据到显存,多节点的结果参考意义不大(类似于只是跑个多副本)。
在SXM/OAM GPU模组的比较中,8个AMD MI300X的Token/s测试数据与8个NVIDIA H100-SXM-80GB相当接近;8个H200-SXM-141GB则表现最好,还要领先40%左右。
与上面的3款GPU相比,8卡H100-NVL-94GB(4组双卡NVLINK)、H100-PCIe-80GB和L40S-48GB的性能差距依次都比较大。其原因我在下文中会具体分析。
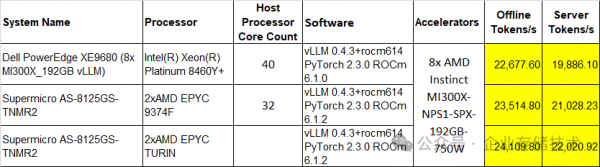
注意:Dell XE9680服务器其实也是双CPU配置(2颗40核),8x SXM GPU的平台基本上都要服务器2 Socket插满吧。
仅以上图表为例,不同测试平台对MLPerf Llama-2-70b推理测试的结果影响不算太大,但还是有一些。同样是8个MI300X GPU,Token/s性能从低到高的3款服务器CPU分别为Xeon 8460Y+、EPYC 9374F和EPYC Turin(最新的9005系列,由于是preview结果没有写CPU核数),它们最大差距达到10%左右。
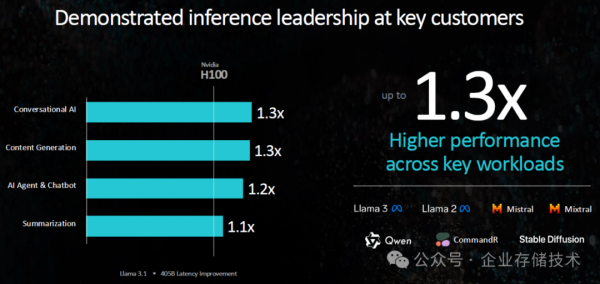
上图引用自AMD在10月10日发布会上的资料,我在《AMD EPYC 9005 (Zen 5&5c) 服务器CPU架构解读》曾经引用过一部分,今天再看下GPU相关的。
之前AMD官宣这个MI300X能达到H100最多1.3倍的性能,我个人猜测会不会统一使用PyTorch测试的?当然我并不了解更多的细节信息,所以只是一个猜测。
至于H200,AMD之前是拿MI325X来进行对比的。

Instinct MI325X GPU是在2024 Q4正式出货的,也许我们在下个季度能看到它出现在MLPerf的榜单中?
多GPU线性扩展评估、B100单卡表现优异
下面我将列出完整的测试图表,除了8 GPU之外,还有那些“单卡”、“4卡”的,其中包括有NVIDIA GH200 Grace Hopper Superchip以及NVIDIA B200-SXM-180GB。
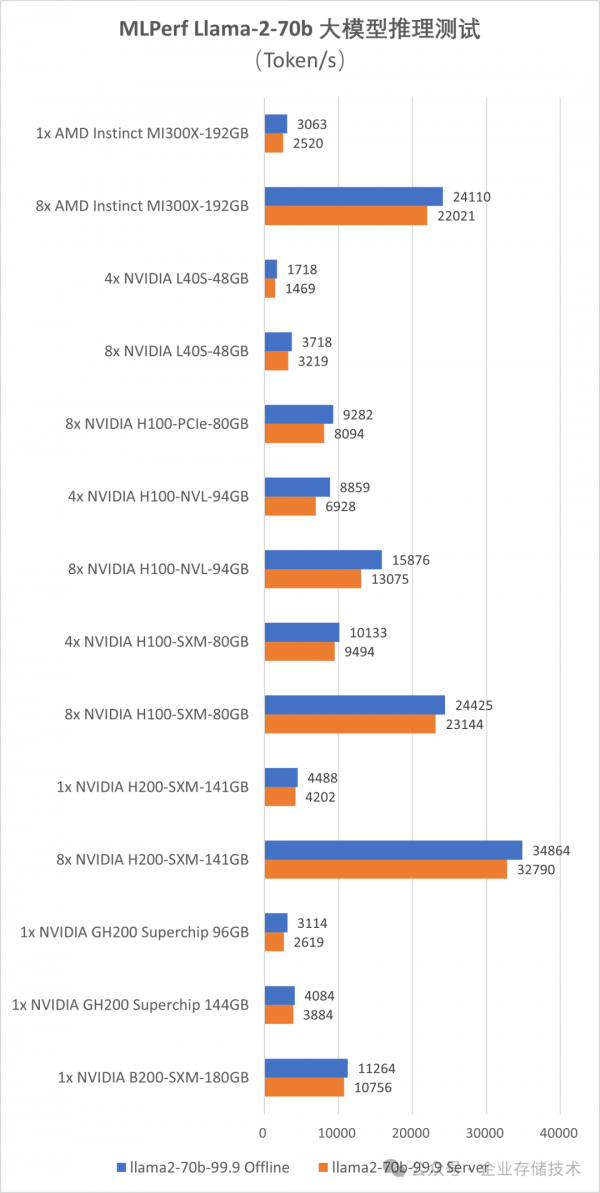
从这里我们可以评估GPU的线性扩展效果。比如8个MI300X推理Token确实达到了单GPU的8倍;H200也是类似的情况。前面我说过MLPerf是测试的Llama-2-70b FP8量化模型推理,所以像L40S 4/8 GPU测试也能达到翻倍的结果,因为基本不需要跨两组“4卡”交互数据。
NVIDIA B200-SXM-180GB单GPU的数据确实优异,一块差不多能顶4个H100-SXM-80GB了。目前这个测试成绩还是preview状态,估计早晚NVIDIA会公布Blackwell架构多GPU的BenchMark结果。
Tensor并行多卡NVLINK vs. PCIe效率
上面这个图表,看起来还是有点让人感觉复杂。为了进一步方便分析,我还想把算力折算到每个GPU来看看。在此之前,有必要先跟大家分享个重要的信息,也算是我从测试代码中发现的吧。
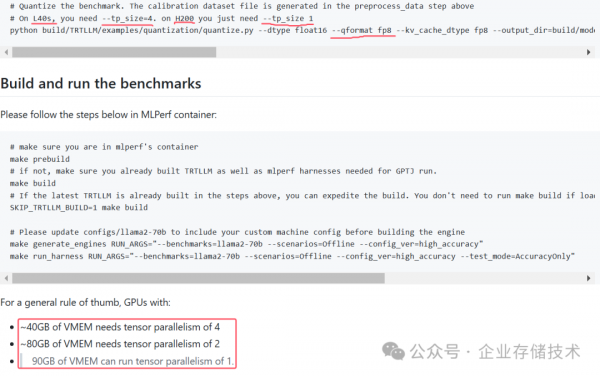
--qformat fp8及右边的输出目录,是把Llama-2-70b量化到FP8的操作。
90GB VMEM就是进行这个测试的门槛需求,也就是说显存达到90GB就可以跑tensor并行度1;而像H100 80GB这样的需要跑tensor并行度2;48GB的L40S则需要—tp_size=4参数。
在有NVLINK或者AMD Infinity Fabric这类高速专用互连的情况下,跨卡的显存数据访问影响应该不大?而通过PCIe插槽的多卡tensor并行,理论上效率就要低一些了。
选型参考:显存带宽是Token/s输出唯一决定因素吗?
记得我在《LLM大模型推理测试 & AI PC选型指南 (1)》中讨论过端侧推理,Torken生成速度的决定因素经常是显存(内存)带宽,但也可能有由于算力、I/O因素受影响的情况。
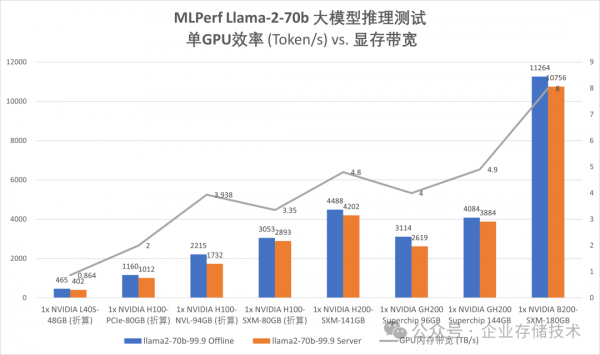
折线上的数值为GPU内存带宽,单位TB/s
如上面图表,右边是4款96GB及以上显存的GPU;左边较低显存的是通过多卡测试成绩折算出来的“单GPU贡献”。(注:不代表单卡显存低于90GB就能把这个测试跑起来。)
B200是单位显存带宽Token性能发挥最好的,这一块NV目前的优势大家也不得不承认。
H100-SXM-80GB、H200-SXM-141GB、GH200 96GB、GH200 144GB这4款GPU的Token性能基本上与显存带宽成正比关系。Grace Hopper Superchip架构的效率相对要低一点,可能与其Arm CPU有关。
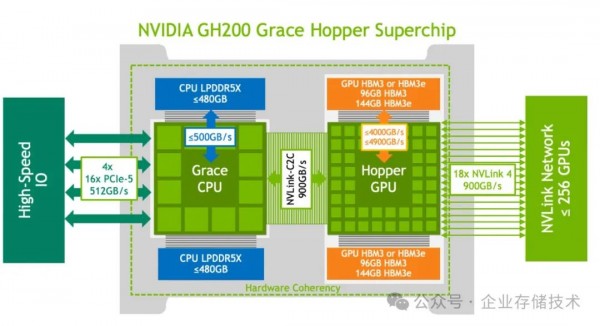
而PCIe形态的H100、L40S GPU,其单位显存带宽能发挥出的推理性能,就要差一些了。这应该与tensor并行的跨卡显存访问瓶颈有关。只是我没想明白的是:H100-NVL-94GB——按道理超过90GB只要tensor parallelism=1就好了,即使走双卡NVLINK互连的效率也不错啊?
硬件参数、卡间互连及软件发挥
| GPU内存带宽 (TB/s) | FP8 TFLOPS (非稀疏) | TDP功耗 (W) | |
| AMD Instinct MI300X-192GB | 5.3 | 2614.9 | 750 |
| NVIDIA L40S-48GB | 0.864 | 733 | 350 |
| NVIDIA H100-PCIe-80GB | 2 | 1513 | 350 |
| NVIDIA H100-NVL-94GB | 3.938 | 1671 | 400 |
| NVIDIA H100-SXM-80GB | 3.35 | 1979 | 700 |
| NVIDIA H200-SXM-141GB | 4.8 | 1979 | 700 |
| NVIDIA GH200 Superchip 96GB | 4 | 1979 | 1000* |
| NVIDIA GH200 Superchip 144GB | 4.9 | 1979 | 1000* |
| NVIDIA B200-SXM-180GB | 8 | 4500 | 1000 |
注:GH200 Superchip的1000W功耗中,还包含了72核Arm CPU,GPU部分大约也是700W左右吧。
只好再看看GPU内存带宽之外的规格参数了。上表中我还列出了每款GPU的标称FP8浮点算力,以及TDP功耗。
H100-SXM、H200-SXM和GH200的计算性能是一样的,前面我们看到,它们的测试表现主要受显存带宽影响。PCIe接口的H100,受限于350-400W的功耗,FP8算力要低一些。H100的PCIe介面是PCIe 5.0 x16;而L40S则是PCIe 4.0 x16(还要跨4卡tensor parallelism),推理效率再低一些也是可以理解的。
根据L40S的表现,您是否也能大致推算出NVIDIA RTX 6000/5880 Ada,以及GeForce RTX 4090 (D)的推理性能?还记得我去年讨论“GPU禁令限制计算 & NVIDIA A800/H800/L40等替代分析” 时总结的表格吗?当然4090的显存只有24GB。像AMD MI300这样把显存做大还是有意义的,比如实际跑130B左右模型的8bit量化推理,加上KV Cache占用单卡14x GB显存就不见得能放下了。
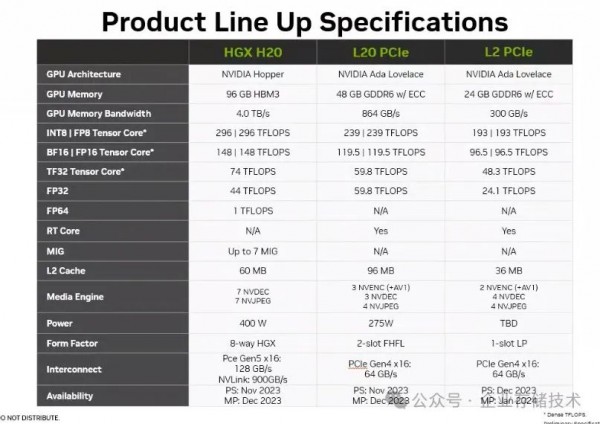
上面为网传图片,仅供参考
这里我想低调提一下H20,由于显存带宽和卡间互连不在禁售的限制中,所以有人说它的推理性能与H100和H800没有明显差距。类似情况应该还有AMD MI308X。
本文中没有讨论训练,及其相关的多卡互连效率——这个因素在AI大模型训练应用中的影响应该更明显。

在本月初的文章中,我曾列出过HGX H20-SXM(H100/200外观形态一样的)以及MI300X-OAM的8 CPU模组照片。上图是AMD Instinct MI325X平台。
关于AMD,一方面我看到MI300X在700-750W的功率水平上,提供了更高的显存带宽和算力指标。但今天似乎还没完全充分发挥出来?估计是ROCm等软件生态上与NVIDIA还有一定差距。所以留给AMD的任务不只是加强GPU的硬件能力——之前公布的roadmap中,2025年将推出MI350系列(包括MI355X),2026年是MI400系列…
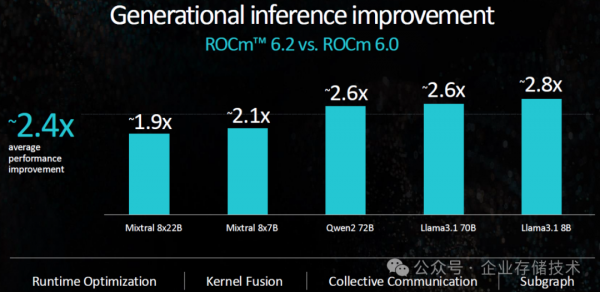
根据AMD列出的数字,从ROCm版本6.0到6.2,AI推理性能已经有很大提高。我也期待看到ROCm 6.2以及更新版本的实测表现。
好文章,需要你的鼓励


Waymo因洪水问题发布召回,近4000辆自动驾驶车辆受影响
Waymo近日发布软件更新,对旗下约4000辆自动驾驶车队实施召回,以帮助车辆规避积水道路。美国国家公路交通安全管理局(NHTSA)指出,此前Waymo机器人出租车在遭遇无法通行的积水路段时,仅减速而未完全停车。此次召回涵盖第五代和第六代自动驾驶系统车辆,共计3791辆。Waymo表示正在完善软件防护措施,并已限制车辆在极端天气及易发洪涝区域的运营。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。

AI驱动的“地面情报“系统:Samsara如何帮助城市主动修复坑洼路面
路面坑洞每年给城市造成数百万美元损失。车队管理公司Samsara推出名为"Ground Intelligence"的AI解决方案,通过已安装在数百万辆商用卡车上的摄像头,自动识别并追踪坑洞的位置与劣化程度。该系统以仪表盘形式呈现,可主动向城市管理者推送预警信息,将被动响应转变为主动规划。目前,芝加哥已成为其新客户。未来还将扩展至涂鸦、损坏护栏等城市基础设施监测。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。
2024
12/30
11:04
分享
点赞

