
傅利叶正式开源全尺寸人形机器人数据集Fourier ActionNet,并发布全球首个全流程工具链
3月17日,傅利叶正式开源全尺寸人形机器人数据集Fourier ActionNet,并发布全球首个全流程工具链。首批上线超3万条高质量真机训练数据,包含多种自由度灵巧手的训练数据及专门针对手部任务的模仿学习数据,面向全球开发者及科研机构开源共享,提供从数据采集、训练、部署的一站式解决方案。

数据高质量,提升训练有效性
高质量机器人动作数据是具身智能发展的核心驱动力。然而真实场景下的机器人动作数据长期面临采集成本高、标注精度不足等问题,制约着行业进步。Fourier ActionNet数据集囊括傅利叶GRx系列所有机型的各类任务训练,完整记录机器人在真实环境中的任务执行数据,涵盖了对常用工具、家居用品、食物等多种物体的精确取放、倾倒等操作,以及在不同环境条件下实现泛化执行。
- 多模态+高质量+万级体量:万级真机训练数据,包含专门针对手部任务的模仿学习数据,适配多自由度灵巧手任务;

- VLM标注+人工核验:所有数据均采用视觉语言模型(VLM)进行自动标注,并通过人工二次核验,确保数据精度与准确性。
全球首个全流程工具链,降低研发门槛
除了数据集的开源以外,傅利叶同步开放了全球首个包含采集算法、训练算法以及数据部署算法的全流程工具链,最大程度上与全球开发者共享研究成果。开源的训练框架(如DP、ACT、iDP3)和部署工具,进一步降低了人形机器人技术研发门槛。
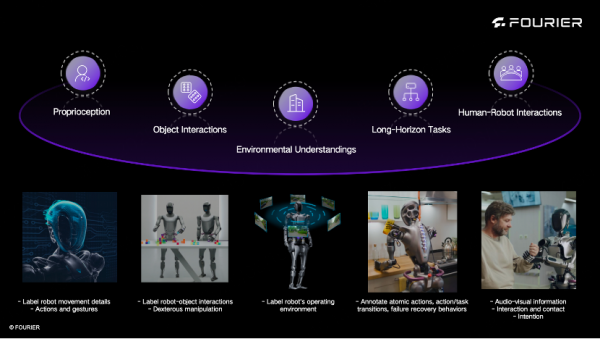
- 自带数据质量评估:基于扩散策略(DP)、Transformer动作分块策略(ACT)及改进3D扩散策略(iDP3)对数据集进行系统性验证,在GRx全系列机型中均可稳定执行开柜门、抓取柠檬、倾倒豆子等高难度任务;
- 配套开发工具支持:同步开源基于LeRobot生态的DP、ACT、iDP3等主流训练框架和部署框架,提供从数据管理到算法部署的全流程支持。
共建开源生态,推动技术共享
目前,傅利叶已与国内外20多家顶尖科研院校及行业领军企业开展合作,基于GRx人形机器人平台在强化学习、模仿学习、VLM大模型、感知系统等研究领域产出多项突破性成果。此次数据集开源标志着傅利叶从技术攻坚向生态共建的战略升级,未来还将持续开放更多覆盖全身运控、多任务协同的进阶数据模块。
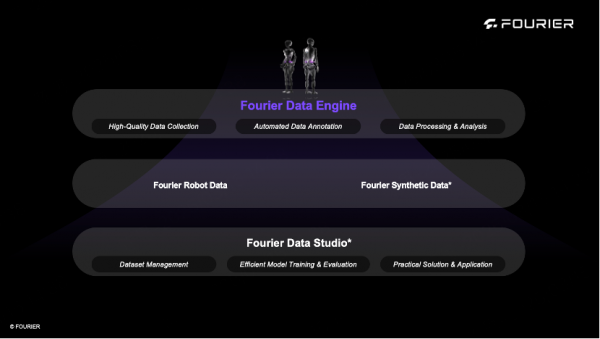
傅利叶始终致力于推动人形机器人开源生态建设,助力全球机器人技术共享与创新。我们诚邀所有对人形机器人研究感兴趣的开发者和科研伙伴加入这一开源浪潮,共同参与数据贡献与算法优化,迎接机器人技术赋能未来的无限可能。
好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

华东师范大学等多家机构联合出手:让机器人训练数据“少而精“,原来靠这个秘密武器
SIEVE是一种面向机器人模仿学习的数据筛选方法,通过发现可复用行为原语和转换接口,用50%数据和训练量超越全量训练效果。


马萨诸塞大学的研究者们证明了:搜索引擎的“比较策略“在数学上优于传统方法
马萨诸塞大学从数学角度证明,MaxSim评分策略在理论能力上超越传统单向量内积方法,并提出Signed MaxSim扩展,显著改善否定查询性能。
2025
03/17
11:21
分享
点赞

“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
魔法原子人形机器人走出“练兵场”
魔法原子举办2025场景战略发布会 官宣“千景共创计划”落地1000个应用场景
“2025世界机器人大赛-首届具身智能机器人运动会”新闻发布会在无锡召开
从“解题答疑”到“培养思维”,夸克“AI解题大师”定义AI产品新价值
傅利叶正式开源全尺寸人形机器人数据集Fourier ActionNet,并发布全球首个全流程工具链
《AI启示录》:当ERP长出AI神经,胜负手在于业务扎根
奢饰品行业的一个麻烦:这家法国公司想用AI来解决
北沟村的幸福蝶变:一场时间与技术的乡村交响
国产大模型崛起!ERP国产替代破局时刻到来!
DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮
