
夸克健康大模型通过副主任医师考试,12门学科超合格线
5月27日,夸克健康大模型在12门国家副主任医师职称考试中成绩超过合格线,成为国内首个成功跨越这一门槛的大模型。这意味大模型在严肃医疗场景中迈出了从“知识记忆”向“临床推理”跃迁的关键一步。
此前,国内大模型多停留在临床执业医师资格考试阶段,只能拿到初级职称。夸克则实现了从初级到副高级职称的两级跳。夸克健康大模型以通义千问为基础,通过海量的高质量数据构建和多阶段后训练策略实现了此次突破。
全新的大模型能力已经可以直接通过夸克搜索调用。用户在使用中会发现,对于严肃医疗问题夸克会通过先分析后搜索,动态检索书籍、指南、药品说明书、医典论文等。这种高搜商的策略显著的提升了复杂病例的准确率。
此次副主任医师职称考试评测覆盖了12个常用学科,包括:全科医学、普通内科学、普通外科学、妇产科学、小儿内科学、肿瘤内科学、口腔医学、耳鼻咽喉科学、眼科学、皮肤与性病学、精神病学、麻醉学。在上述学科领域,夸克健康大模型均超过合格线,并在全科医学、肿瘤内科学、皮肤与性病学、精神病学4个学科达到主任医师及格线。
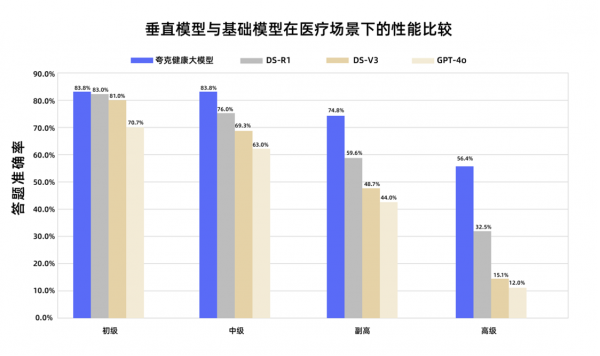
在初级与中级职称考试中,更小尺寸的夸克健康大模型相比满血版基础模型最高领先7分和10分左右。进入难度显著提高、强调临床综合运用的副高职称考试时,夸克最高领先幅度扩大至30分,在长链推理、诊疗路径规划上有显著提升。这项研究验证了垂直模型在性能提升上具备巨大潜力。
对题型维度的深入剖析显示,多选题与病例分析题是所有模型误判率最高的两类。个别通用基础模型在多选题上的正确率均不足60%,而夸克借助“医疗长思考”机制达到71%。在病例分析题中,夸克通过检索增强与分步推理组合策略,将正确率提升至53%。
夸克健康算法工程师徐健表示,“机器通过考试并不意味着可以替代医生,但它展示了在辅助诊疗决策、循证检索与患者沟通方面的巨大潜力。我们将不断强化模型能力,帮助医生和患者提升诊疗效率,为用户在居家场景下提供更多健康管理能力”。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

华南理工大学与西湖大学联手破解3D场景生成难题:让AI真正“站在你的角度“看世界
CGGS是华南理工大学与西湖大学联合提出的以自我为中心三维场景生成框架,通过一致性增强多视角扩散模型、光流深度估计和互信息几何优化,实现高保真文本驱动3D场景生成。
2025
05/27
11:12
分享
点赞

Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
Apple芯片现不可修复漏洞,或成iPhone越狱突破口
