
国内唯一,阿里千问斩获NeurIPS 2025最佳论文奖
11月27日,人工智能领域顶级会议NeurIPS 2025公布了论文奖,阿里通义千问团队在注意力机制上的研究成果从全球5524篇论文中脱颖而出,被评为最佳论文,是唯一获得该奖项的中国团队。该论文首次在业内揭秘了注意力门控对大模型性能和训练的影响,据悉,该研究成果已应用于Qwen3-Next模型,并显著提升模型的性能与鲁棒性。

阿里通义千问研究成果被评为NeurIPS 2025最佳论文
门控是大模型应用最广泛的技术之一,它可以作为模型的“智能降噪耳机”,帮助模型过滤无效信息从而提升模型性能。近年来,AlphaFold2、Forgetting Transformer等学术界和工业界模型开始探索将门控和注意力机制结合,但都对门控在注意力机制中有效的原因缺乏探索,也没有大规模实践的经验。
此次,通义千问团队通过在1.7B稠密模型(Dense)与15B混合专家模型(MoE)上训练超过 3.5 万亿 token,并对比 30 余组控制实验,首次清晰揭秘了其背后的原理,并展现了在注意力中使用门控形式最有效的方式及扩展成功实践。
注意力头是注意力机制中的基本计算单元。实验结果显示,对各注意力头的输出进行门控,是提升模型性能最有效的方式。使用该方式,在引入额外1%参数、计算开销增加低于2%的情况下,可以实现0.2以上的困惑度下降、MMLU基准评测2个点的提升。研究还发现,该技术还能在更大规模的模型训练上实现更好的性能。
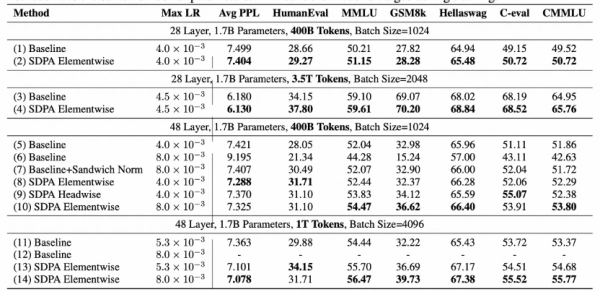
使用论文方法,在引入额外1%参数、计算开销增加低于2%的情况下,可以实现0.2以上的困惑度下降、MMLU基准评测2个点的提升
更深入的分析发现,注意力门控还解决了大模型长期存在的两大问题:注意力池(Attention Sink),即少量特殊token计算中产生很大的输出值、占据很高的注意力分数;巨量激活(Massive Activation),即模型激活中出现大于中位数数千倍的离群值。上述两个现象都容易在BF16等低精度训练中引发数值误差,影响训练稳定与低精度部署。该研究显示,门控注意力将首token的注意力占比从 46.7%降至4.8%,同时将最大激活值从1053降至94。
目前,该技术方案、实验模型及产品级模型均已开源。NeurIPS评审委员会表示:“我们认为该方法将被广泛采用,这项工作将极大推动社区对大语言模型中注意力机制的理解。”
通义千问团队表示:“对门控机制、模型机制等的深入理解,不仅为大语言模型架构设计提供了新思路,也为构建更稳定、更高效、更可控的大模型奠定了基础。”
据悉,目前阿里千问已开源300多款模型,涵盖全模态、全尺寸,全球下载量突破7亿次,衍生模型超过18万个,位居全球第一。
好文章,需要你的鼓励


Waymo因洪水问题发布召回,近4000辆自动驾驶车辆受影响
Waymo近日发布软件更新,对旗下约4000辆自动驾驶车队实施召回,以帮助车辆规避积水道路。美国国家公路交通安全管理局(NHTSA)指出,此前Waymo机器人出租车在遭遇无法通行的积水路段时,仅减速而未完全停车。此次召回涵盖第五代和第六代自动驾驶系统车辆,共计3791辆。Waymo表示正在完善软件防护措施,并已限制车辆在极端天气及易发洪涝区域的运营。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。

AI驱动的“地面情报“系统:Samsara如何帮助城市主动修复坑洼路面
路面坑洞每年给城市造成数百万美元损失。车队管理公司Samsara推出名为"Ground Intelligence"的AI解决方案,通过已安装在数百万辆商用卡车上的摄像头,自动识别并追踪坑洞的位置与劣化程度。该系统以仪表盘形式呈现,可主动向城市管理者推送预警信息,将被动响应转变为主动规划。目前,芝加哥已成为其新客户。未来还将扩展至涂鸦、损坏护栏等城市基础设施监测。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。
2025
11/27
11:28
分享
点赞

遭黑客入侵的Klue称犯罪分子正在删除窃取的客户数据,但新的黑客组织接连发出威胁
苹果起诉OpenAI窃密:前员工利用零日漏洞下载机密文件
Uber联手Hertz为Lucid无人驾驶出租车提供运营支持
Aurora与McLane达成合作,无人驾驶卡车将在德克萨斯州运营
Waymo因洪水问题发布召回,近4000辆自动驾驶车辆受影响
AI驱动的"地面情报"系统:Samsara如何帮助城市主动修复坑洼路面
特斯拉Robotaxi披露两起远程操控事故
特斯拉FSD自动驾驶软件加速进军欧洲市场
Waymo暂停高速公路服务,因自动驾驶出租车难以应对施工区
Waymo自动驾驶车辆注册数量领跑德克萨斯,特斯拉远落后
Siri AI、ChatGPT、Claude真实横评,谁才是最强AI助手?
Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
