
AI研究人员的六道道德自检题:如何强化你的伦理判断力
欢迎来到CNET全新的客座专栏系列Alt View,这是一个汇聚多元专家与权威人士的论坛,分享他们对快速演进的人工智能领域的深度洞察。
当然,你有道德准则,但你多久会真正运用一次?
我,Meia,是一位从事心理学研究的教授。我可以告诉你,绝大多数糟糕的结果并非源于缺乏道德准则,而是这些准则没有被激活。我,Max,是一位从事AI研究的教授。我可以告诉你,作为一名AI研究人员,你的每一个选择都至关重要,因为你正在参与构建有史以来最强大的技术:AI既可能带来前所未有的健康、繁荣、自由、尊严与赋权,也可能引发一场取代我们工作、关系、决策、权力乃至我们整个物种的竞赛。
AI社区几乎每天都要面对道德抉择,话题涵盖AI伴侣、监控、黑客攻击和军事应用等。许多顶级AI公司正深陷诉讼泥潭,议题从数据中心到AI安全无所不包,其中最引人注目的莫过于OpenAI的Sam Altman与xAI的Elon Musk之间的法庭交锋。与此同时,Anthropic与美国国防部的对峙也已持续多时。
所以,对于所有AI研究人员,这里有一份实用清单,帮助你锻炼自己的道德力量。
一、你有红线吗?
是否存在某种行为,让你觉得在道德上完全无法接受,以至于一旦你所在的组织采取了它,你就会选择辞职?或者采取某种预先设定好的、有代价的行动,比如举报?这些行为就是你的道德红线。
例如,Rosa Parks因反对种族隔离的公民不服从行为而被罚款和解雇;Vasily Arkhipov因否决苏联对美核打击而遭批评;Edward Snowden因揭露大规模监控而流亡海外。许多AI研究人员因顶级AI公司越过他们的红线而选择离开,比如Daniel Kokotajlo,他在拒绝签署不诋毁协议的情况下从OpenAI辞职,冒着损失近200万美元股权的风险。你的红线是什么?
二、你把红线写下来并分享出去了吗?
George Washington和Benjamin Franklin都为自己写下了道德准则,Franklin甚至每周给自己的表现打分。这是避免"温水煮青蛙"效应的有力工具,可以保护你的红线不被逐渐侵蚀。与亲人分享或在网上公开这些准则,会增加坚守它们的社会压力。对于每条红线,务必写下一旦被越过你将采取的具体行动。
三、你抵御过道德脱钩了吗?
为了进一步强化你的道德肌肉,确保红线不被移动,了解需要警惕的失败机制非常有用。肌肉不运动就会萎缩,道德肌肉也是如此。让我们看看由有史以来最具影响力的心理学家之一Albert Bandura所识别的道德脱钩机制。当你的红线受到公司、社交圈、个人利益诱惑或自我感觉良好的欲望施加压力时,这些机制能帮你识别并对抗它们。
责任转移与扩散:如果你或他人说服你,你并非真正对伤害负责,你会感觉好受些:真正的决策者是高层、投资者、市场、地缘政治或历史("这项技术不可避免")。当AI工作分散到大型团队时,每个人对集体结果的责任感都会减弱。"我只是个研究员"或"我只是在做我的工作",是政治理论家Hannah Arendt识别出的典型借口。讽刺音乐家Tom Lehrer在那首关于火箭科学家从纳粹德国转投美国的滑稽歌曲中作了总结:"'火箭升空之后,落在哪里就不归我管了',Wernher von Braun如是说。"
例如,一位Anthropic研究员在读到Claude AI可能与150多名伊朗女学生遇难事件相关的报道时,可能会安慰自己说自己无可指责,因为只有管理层才需要为出售军事打击工具负责。
文字游戏:Bandura和Arendt都强调了微妙的措辞选择如何重塑道德边界。我们都熟悉军事委婉语,比如用"打击目标"代替轰炸,"附带损伤"代替平民伤亡,"强化审讯技术"代替酷刑。但AI行话中也充满了类似的文字游戏,且常常受到利益相关方的鼓励。
最基本的游戏是"委婉标签":用积极或情感平淡的术语替代道德色彩鲜明的语言。研究人员不是在"帮助构建可能取代工人、操纵用户、集中权力或加剧生存风险的系统";他们做的是"能力研究"、"模型改进"或"基准提升"。在受版权保护的数据上训练变成了"学习的自由"。不受欢迎的数据中心变成了"AI基础设施"。解雇或弱化工人变成了"生产力提升","游说反对问责"变成了"减少摩擦"。请练习使用中性词,比如用"公司"代替"实验室"(听起来酷且无辜),用"AI系统"代替"AI模型"(听起来无害)。Bandura的观点是,委婉语不仅软化了语气,更削弱了良知。
另一种文字游戏是责备归因,把批评者塑造成问题本身——"末日论者"、"卢德分子"、"投机政客"、"无知记者"或反科技的欧洲人。一旦对手被指责为非理性或心怀不轨,AI研究员就觉得没必要把批评当作严肃的道德议题对待。
第三种文字游戏是软性去人格化:失业的程序员、被侵权的个体作者、与聊天机器人对话后自杀的孩子,都消失在"劳动力市场"、"创作者群体"、"边缘案例"这些类别中。伤害越是被统计化而非个人化地讨论,触发的道德痛苦就越少。
选择性道德豁免:人们倾向于在总体上坚持高道德标准,但在自己受益最大的领域开个例外:一位AI研究员可能对抽象的不公正充满道德激情,但在评判自己的雇主、AI、薪水或股权时,却会暂停同样的标准。
有利比较:人们倾向于只与更糟糕的人比较:"至少我不在最鲁莽的实验室。""至少我没在做自主武器。""至少我关心对齐问题。"这让你感觉自己有道德,却不必追问自己的行为在绝对标准下是否可接受。
道德正当化:对于承认自己正在造成伤害的人,将其正当化为服务于崇高使命是很有诱惑力的,比如"帮助民主胜出"、"创造普遍富足"或"确保安全有一席之地"——而不严肃地质疑这些崇高目标是否可信,或是否有伤害更小的实现方式。
这些道德脱钩技术组合并升级时威力极大:安然公司高管从被合理化为公司生存所需的轻微财务操纵开始,逐步升级到掩盖巨额债务的大规模欺诈。Bernie Madoff从被合理化为帮助客户的小额回报造假开始,然后把责任转嫁给市场、把受害者去人格化,通过渐进的道德脱钩最终酿成650亿美元的欺诈案。在越南战争中,士兵服从命令参与"正义战争",从轻微违规开始,通过责任扩散和受害者去人格化,逐步升级到美莱村大屠杀这样的暴行。
前沿AI研究员典型的Bandura式自我安慰是:"我不是一场有害竞赛中拿高薪的参与者;我是一个负责任、现实、道德严肃的人,在引导不可避免的进步。"但鉴于民调显示这场取代竞赛极不受欢迎,它真的不可避免吗?还是这只是一个Bandura式的借口和自我实现的预言?
四、你是否保持情境意识?
你是否主动调研你的红线是否被越过?这包括调查你所在组织行为的间接后果。Hannah Arendt写过"平庸之恶",认为最大的伤害往往不是出于恶意,而是出于不思考全局的、顺从而尽责的技术官僚。
我们前面谈到了如何用文字游戏来淡化已知伤害,把它们重新定义为可控的、过渡性的,或被收益所抵消。但还有另一种强大的道德脱钩技术:通过不主动了解自己所造成的伤害来保持便利的无知。如果你本可以通过调查就能知晓,那么无知就是一个糟糕的借口:德国化学家Bruno Tesch在1946年因向奥斯维辛集中营供应齐克隆B毒气而被定罪处决,尽管他声称自己不知道这些毒气将被用于何处。
所以请定期问一些显而易见的问题。例如,你所在的组织有哪些红线?它是否在积极游说反对你支持的AI安全立法?你查过AI安全指数了吗?它的产品如何被使用?如果你为Google或OpenAI工作,你有没有浏览过任何针对你公司的、涉嫌与聊天机器人相关自杀案的诉讼?
讽刺的是,得益于现代大语言模型,对这些情况一无所知实在没有借口,因为它们距离你只有一个提示词。例如,你可以每月尝试这样问:
"请列出[我的公司]近年来在道德上有争议的行为,包括a)其工具的争议性使用(如用于自杀、犯罪、监控或武器),b)其工具据称造成的伤害,c)公司或其领导层据称的谎言或违背承诺,d)公司追逐利润而非真正造福人类的扭曲激励。"
五、你在内部发声了吗?
如果你了解到某件事接近你的某条红线,那么就在内部提问以了解更多。虽然历史上批评自己所在组织可能招致杀身之祸,但在今天的AI公司这样做甚至不太可能让你被解雇——再说,你为什么要继续为一家无法容忍对你红线的尊重性质询的公司工作呢?大多数公司甚至有保护你的举报政策。
如果你发现的情况无法接受但你还没准备好辞职,那就在内部发声:向同事和上级解释原因,并大力推动变革。不要像那些意识到低温可能导致挑战者号航天飞机O型环灾难性故障、后来后悔没有强烈发声的工程师之一。如果你在安全团队,但不认识游说团队或做发布决策的人,请真诚地努力与他们建立联系并教育他们——不要成为"旁观者综合症"的典型代表。
六、你在外部发声了吗?
公开表态挑战自己所在的组织,可以从多个方面产生作用,从推动其自愿改进到激发外部力量向其(及其竞争对手)施压。这并不意味着你必须像Edward Snowden那样冒着流亡的风险:近来有许多案例显示,AI研究人员对自己公司提出有理有据的批评,并未遭到任何报复。如果你公开批评所在组织或揭露有害或非法行为,会面临什么后果?大多数美国AI公司都有举报人政策;请阅读你的那份!此外,简单搜索一下(也许不要用你自己公司的大语言模型)就能找到许多声誉良好的举报人组织,它们能在你被解雇或被起诉时提供从法律支持到经济援助的各种帮助。
读完这些,你会如何评价自己的道德肌肉?你在自己身上识别出多少种道德脱钩技术?你对公司可能造成的伤害进行的调研有多深入?如果你尽管心怀善意但得分很低,也请不要灰心。把它想象成第一次去健身房,发现自己连50磅都举不起来:肌肉需要使用才能变强,这个六步计划可以迅速强化你的道德肌肉——很快你会发现镜中的自己变得格外好看。
Q&A
Q1:AI研究人员的道德红线是什么意思?
A:道德红线指的是那些让你觉得在道德上完全无法接受的行为。一旦你所在的组织采取了这些行为,你就会选择辞职或采取其他预先设定好的、有代价的行动,比如举报。每个人都应明确自己的红线,并写下一旦被越过将采取的具体行动。
Q2:什么是道德脱钩?有哪些常见表现?
A:道德脱钩是由心理学家Albert Bandura提出的概念,指人们让自己脱离道德责任的心理机制。常见表现包括责任转移与扩散、用委婉语进行文字游戏、选择性道德豁免、与更糟糕的人作有利比较、用崇高使命进行道德正当化等。这些机制组合起来威力很大,可能导致严重的道德滑坡。
Q3:AI研究人员发现问题后该怎么办?
A:可以先在内部提问以了解更多情况,向同事和上级解释问题并推动变革。如果内部发声无效,可以考虑外部发声,公开提出有理有据的批评。大多数美国AI公司都有举报人保护政策,还有许多声誉良好的举报人组织提供法律和经济援助。
好文章,需要你的鼓励

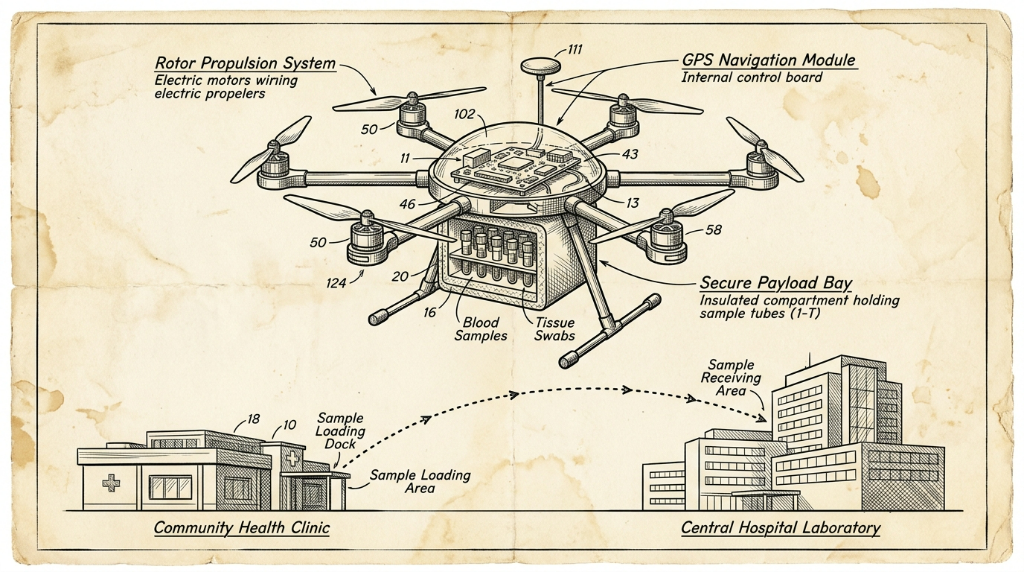
英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2026
05/18
12:18
分享
点赞

WAIC2026 现场直击:开普勒顶流人气王,麒麟系列火爆出圈
面壁智能将密度定律带入具身智能
龙磁科技拟投3.58亿元扩建越南永磁铁氧体基地
首创一层Scale-up网络256卡全互联,摩尔线程MTT C256超节点为万卡及十万卡级集群夯实底座
从高血压诊疗入手,北京安贞医院让医疗大模型走出聊天框
西门子肖松:以场景为牵引,推动工业AI从单点实效迈向生产力跃迁
打造Token极致性价比 新华三震撼亮相2026世界人工智能大会
机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
SAP推出统一平台,整合构建与部署AI的全套能力
Core42与Solutions+携手推进穆巴达拉主权AI基础设施建设
谷歌阻止了一场疑似由AI辅助开发的零日漏洞攻击
科技巨头Q1财报出炉:资本支出持续高位,AI基础设施投入超6000亿美元
Meta放弃开源Llama转向专有模型Muse Spark,开发者何去何从
Opera浏览器支持本地下载运行大语言模型,超150款可选
xAI正转型为新型云计算服务商?与Anthropic达成重磅算力合作
Anthropic将借助SpaceX的Colossus 1超级计算机为Claude提供算力支持
月之暗面完成20亿美元融资,估值达200亿美元
Anthropic牵手SpaceX、IBM押注AI赛道、Cerebras谋划巨额IPO
