
AI终端智能:人工智能AI的新革命
基于成本、能耗、可靠性和时延、隐私、个性化服务等考虑,端云混合的 AI 才是 AI 的未来,高通认为终端 AI 能力是赋能混合 AI 并让生成式 AI 实现全 球规模化扩展的关键。
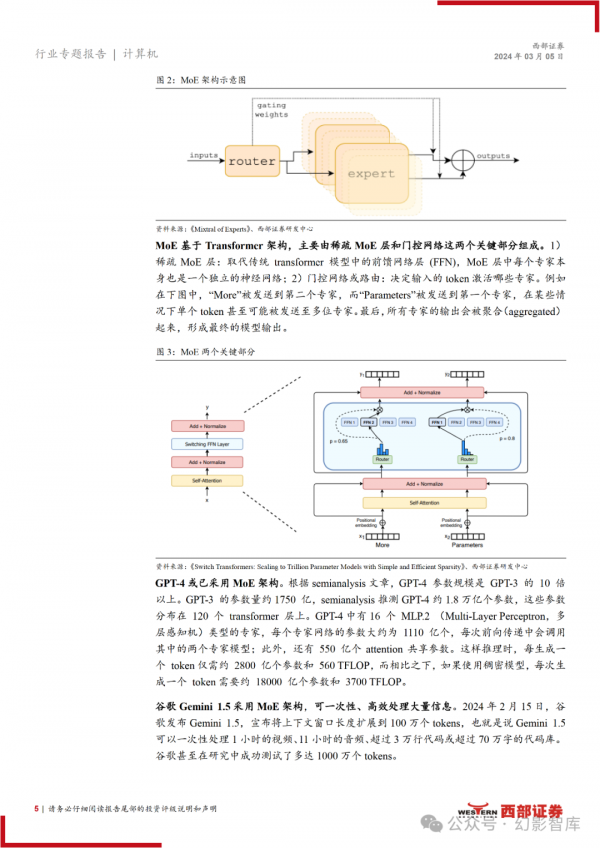
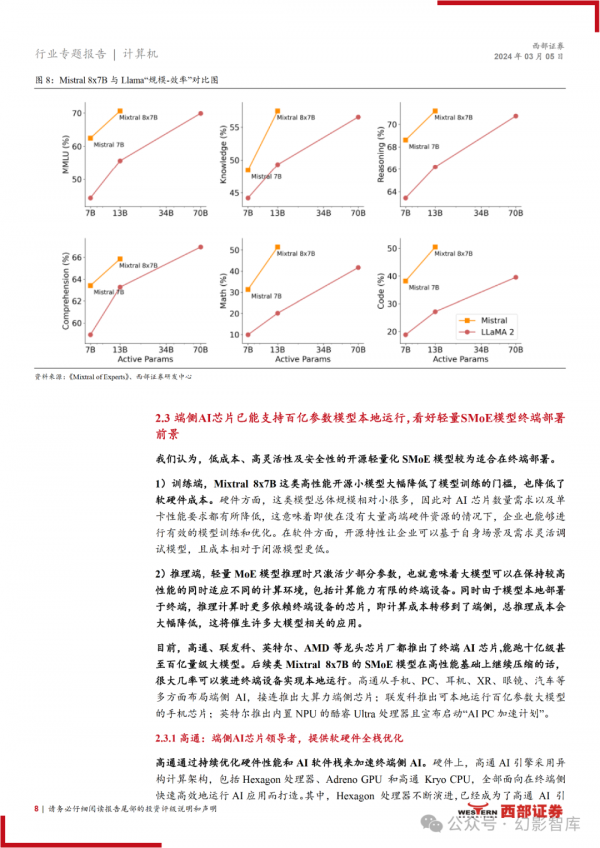
百亿参数开源 MoE 大模型 Mixtral 8x7B 再掀热潮,性能超 LLaMA2-70B,对 标 GPT-3.5。MoE(混合专家模型)通过将任务分配给对应的一组专家模型来 提高模型的性能和效率。Mixtral 8x7B 的专家数量为 8 个,总参数量为 470 亿, 但在推理过程中仅调用两个专家即只调用 130 亿参数。
我们认为 MoE 或为现阶段大模型平衡成本、延迟以及性能的最优选择,叠加 开源模型本身高灵活性、安全性和高性价比特点,Mistral AI 的开源 MoE 轻量 化模型可能是未来最适合部署于终端的模型。
目前,高通、联发科、英特尔、 AMD 等龙头芯片厂商都推出了终端 AI 芯片,能跑十亿甚至百亿量级大模型。后 续类 Mixtral 8x7B 的 SMoE 模型在高性能基础上继续压缩的话,很大几率可以 装进终端设备实现本地运行。

SMoE 轻量模型大幅降低了训练的门槛和成本, 且由于在推理时只激活少部分参数,保持较高性能的同时能适应不同的计算环 境,包括计算能力有限的终端,降低推理成本且将催生更多大模型相关应用。
2024 年有望成为终端智能元年,看好拥有终端资源、深耕场景、掌握行业 knowhow、积累了海量数据的 B 端和 C 端公司。
1)未来每台终端都将是 AI 终端,包括 AI PC、AI 手机、AI MR 等,这将带来全新的用户体验。
2)AI PC 有望成为“AI+”终端中最先爆发的。英特尔预计全球今年将交付 4000 万台 AI PC,明年将交付 6000 万台,预估 2025 年底 AI PC 在全球 PC 市场中占比将超 过 20%;微软 AI PC 预计于今年亮相。
3)随着大模型逐步发展,尤其是多模态 能力增强,更广泛的 AIoT 设备也迎来了更新换代的重要机遇。
4)B 端私有化 部署也是 AI 应用的重要方向,关注边缘侧 AI。
5)鸿蒙:提供顶级流畅连接体 验,大模型有望赋能奔赴万物智联下一站。
人形机器人是大模型应用的重要硬件载体,也是终端智能发展的核心方向。
1) 人形机器人是目前具身智能最好的形态,因为它们有着与人相似的外观设计, 能更好地适应周围的环境和基础设施。2)端云混合的“大脑”让机器人既能处理 复杂和高强度的计算任务,又能实时进行信息处理和分析。










好文章,需要你的鼓励


旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

三一学院与华为研究院联手出招:AI大模型“智能分诊“系统,省钱又省时
三一学院与华为联合提出两阶段AI模型调度框架:先按语义聚类分配最优模型,再用轻量分类器拦截低质回答升级处理,在保留97-99%最强模型准确率的同时显著降低推理延迟。

美国NRC提出核废料处置新规,为长期搁置问题开辟出路
美国核管理委员会(NRC)近期提出对第61部分法规进行全面修订,首次为"超C类"(GTCC)低放射性核废料建立明确的许可处置路径。现有框架要求将其送入从未建成的深层地质处置库,形成"监管死胡同"。新规拟采用基于风险的分析方法,按废料实际放射性危害而非来源确定处置方式,约80%的GTCC废料或可适用近地表处置。这些废料目前分散存放于反应堆、医院及工业设施,新规将为其提供集中处置的可行路径。

当AI团队“各自为政“时,伊利诺伊大学如何用“梯度指纹“找出问题根源?
多智能体AI系统常因无法精准定位错误来源而难以优化,GBC通过梯度计算为每个AI的输出建立影响力评分,实现跨智能体的精细归因与针对性提示词优化。

